 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Bridge: Bridging Video Generative Priors to Versatile Few-shot Image Restoration
Mar 13, 2026Large-scale video generative models are trained on vast and diverse visual data, enabling them to internalize rich structural, semantic, and dynamic priors of the visual world. While these models have demonstrated impressive generative capability, their potential as general-purpose visual learners remains largely untapped. In this work, we introduce V-Bridge, a framework that bridges this latent capacity to versatile few-shot image restoration tasks. We reinterpret image restoration not as a static regression problem, but as a progressive generative process, and leverage video models to simulate the gradual refinement from degraded inputs to high-fidelity outputs. Surprisingly, with only 1,000 multi-task training samples (less than 2% of existing restoration methods), pretrained video models can be induced to perform competitive image restoration, achieving multiple tasks with a single model, rivaling specialized architectures designed explicitly for this purpose. Our findings reveal that video generative models implicitly learn powerful and transferable restoration priors that can be activated with only extremely limited data, challenging the traditional boundary between generative modeling and low-level vision, and opening a new design paradigm for foundation models in visual tasks.
P1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads
Feb 10, 2026The transition from symbolic manipulation to science-grade reasoning represents a pivotal frontier for Large Language Models (LLMs), with physics serving as the critical test anchor for binding abstract logic to physical reality. Physics demands that a model maintain physical consistency with the laws governing the universe, a task that fundamentally requires multimodal perception to ground abstract logic in reality. At the Olympiad level, diagrams are often constitutive rather than illustrative, containing essential constraints, such as boundary conditions and spatial symmetries, that are absent from the text. To bridge this visual-logical gap, we introduce P1-VL, a family of open-source vision-language models engineered for advanced scientific reasoning. Our method harmonizes Curriculum Reinforcement Learning, which employs progressive difficulty expansion to stabilize post-training, with Agentic Augmentation, enabling iterative self-verification at inference. Evaluated on HiPhO, a rigorous benchmark of 13 exams from 2024-2025, our flagship P1-VL-235B-A22B becomes the first open-source Vision-Language Model (VLM) to secure 12 gold medals and achieves the state-of-the-art performance in the open-source models. Our agent-augmented system achieves the No.2 overall rank globally, trailing only Gemini-3-Pro. Beyond physics, P1-VL demonstrates remarkable scientific reasoning capacity and generalizability, establishing significant leads over base models in STEM benchmarks. By open-sourcing P1-VL, we provide a foundational step toward general-purpose physical intelligence to better align visual perceptions with abstract physical laws for machine scientific discovery.
FRISM: Fine-Grained Reasoning Injection via Subspace-Level Model Merging for Vision-Language Models
Jan 29, 2026Efficiently enhancing the reasoning capabilities of Vision-Language Models (VLMs) by merging them with Large Reasoning Models (LRMs) has emerged as a promising direction. However, existing methods typically operate at a coarse-grained layer level, which often leads to a trade-off between injecting reasoning capabilities and preserving visual capabilities. To address this limitation, we propose {FRISM} (Fine-grained Reasoning Injection via Subspace-level model Merging), a fine-grained reasoning injection framework based on subspace-level model merging. Observing that reasoning capabilities are encoded in distinct subspaces, FRISM decomposes LRM task vectors via Singular Value Decomposition (SVD) and adaptively tunes the scaling coefficients of each subspace through learning to realize fine-grained reasoning injection. Furthermore, we introduce a label-free self-distillation learning strategy with a dual-objective optimization using common vision-language perception datasets. Extensive experiments demonstrate that FRISM effectively improves reasoning capabilities without compromising the model's original visual capabilities by consistently achieving state-of-the-art performance across diverse visual reasoning benchmarks.
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
P1: Mastering Physics Olympiads with Reinforcement Learning
Nov 17, 2025Recent progress in large language models (LLMs) has moved the frontier from puzzle-solving to science-grade reasoning-the kind needed to tackle problems whose answers must stand against nature, not merely fit a rubric. Physics is the sharpest test of this shift, which binds symbols to reality in a fundamental way, serving as the cornerstone of most modern technologies. In this work, we manage to advance physics research by developing large language models with exceptional physics reasoning capabilities, especially excel at solving Olympiad-level physics problems. We introduce P1, a family of open-source physics reasoning models trained entirely through reinforcement learning (RL). Among them, P1-235B-A22B is the first open-source model with Gold-medal performance at the latest International Physics Olympiad (IPhO 2025), and wins 12 gold medals out of 13 international/regional physics competitions in 2024/2025. P1-30B-A3B also surpasses almost all other open-source models on IPhO 2025, getting a silver medal. Further equipped with an agentic framework PhysicsMinions, P1-235B-A22B+PhysicsMinions achieves overall No.1 on IPhO 2025, and obtains the highest average score over the 13 physics competitions. Besides physics, P1 models also present great performance on other reasoning tasks like math and coding, showing the great generalibility of P1 series.
Decouple and Orthogonalize: A Data-Free Framework for LoRA Merging
May 21, 2025With more open-source models available for diverse tasks, model merging has gained attention by combining models into one, reducing training, storage, and inference costs. Current research mainly focuses on model merging for full fine-tuning, overlooking the popular LoRA. However, our empirical analysis reveals that: a) existing merging methods designed for full fine-tuning perform poorly on LoRA; b) LoRA modules show much larger parameter magnitude variance than full fine-tuned weights; c) greater parameter magnitude variance correlates with worse merging performance. Considering that large magnitude variances cause deviations in the distribution of the merged parameters, resulting in information loss and performance degradation, we propose a Decoupled and Orthogonal merging approach(DO-Merging). By separating parameters into magnitude and direction components and merging them independently, we reduce the impact of magnitude differences on the directional alignment of the merged models, thereby preserving task information. Furthermore, we introduce a data-free, layer-wise gradient descent method with orthogonal constraints to mitigate interference during the merging of direction components. We provide theoretical guarantees for both the decoupling and orthogonal components. And we validate through extensive experiments across vision, language, and multi-modal domains that our proposed DO-Merging can achieve significantly higher performance than existing merging methods at a minimal cost. Notably, each component can be flexibly integrated with existing methods, offering near free-lunch improvements across tasks.
Dynamic Base model Shift for Delta Compression
May 16, 2025
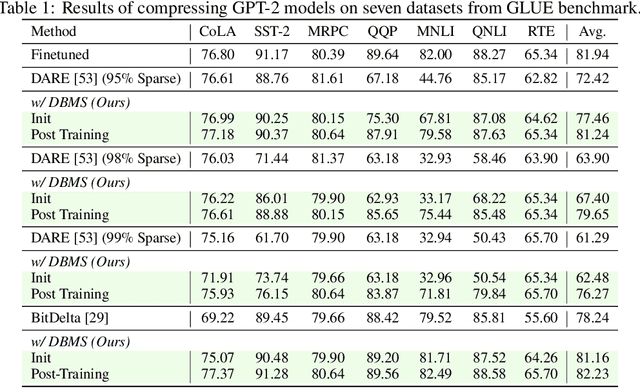

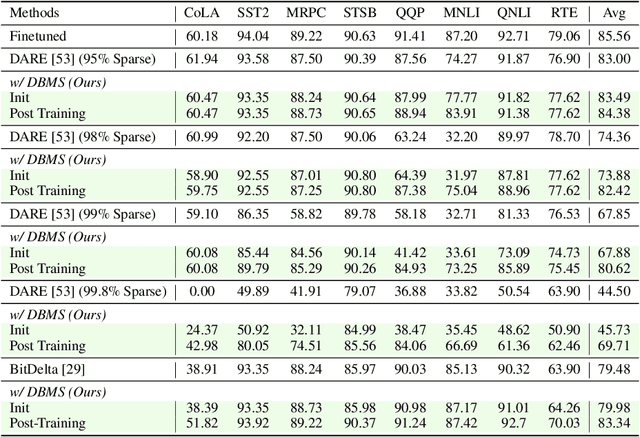
Transformer-based models with the pretrain-finetune paradigm bring about significant progress, along with the heavy storage and deployment costs of finetuned models on multiple tasks. Delta compression attempts to lower the costs by reducing the redundancy of delta parameters (i.e., the difference between the finetuned and pre-trained model weights) through pruning or quantization. However, existing methods by default employ the pretrained model as the base model and compress the delta parameters for every task, which may causes significant performance degradation, especially when the compression rate is extremely high. To tackle this issue, we investigate the impact of different base models on the performance of delta compression and find that the pre-trained base model can hardly be optimal. To this end, we propose Dynamic Base Model Shift (DBMS), which dynamically adapts the base model to the target task before performing delta compression. Specifically, we adjust two parameters, which respectively determine the magnitude of the base model shift and the overall scale of delta compression, to boost the compression performance on each task. Through low-cost learning of these two parameters, our DBMS can maintain most of the finetuned model's performance even under an extremely high compression ratio setting, significantly surpassing existing methods. Moreover, our DBMS is orthogonal and can be integrated with a variety of other methods, and it has been evaluated across different types of models including language, vision transformer, and multi-modal models.
Seeing Delta Parameters as JPEG Images: Data-Free Delta Compression with Discrete Cosine Transform
Mar 09, 2025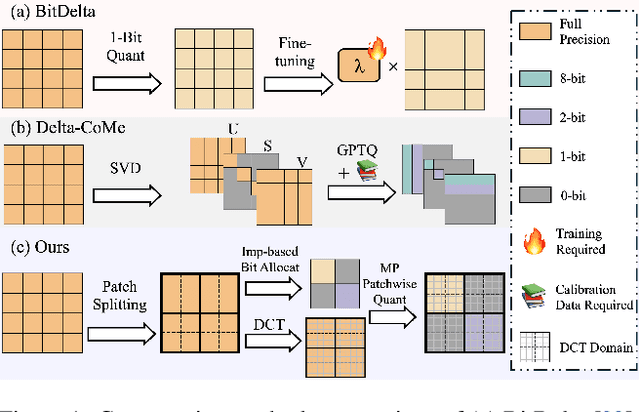



With transformer-based models and the pretrain-finetune paradigm becoming mainstream, the high storage and deployment costs of individual finetuned models on multiple tasks pose critical challenges. Delta compression attempts to lower the costs by reducing the redundancy of delta parameters (i.e., the difference between the finetuned and pre-trained model weights). However, existing methods usually face problems including data accessibility and training requirements. To tackle this issue, we introduce Delta-DCT, the first data-free delta compression method inspired by classic JPEG image compression, leveraging the Discrete Cosine Transform (DCT). We first (a) group delta parameters within a layer into patches. Then we (b) assess the importance of each patch and allocate them with different quantization bit-widths. Afterwards, we (c) convert these patches to the DCT domain and conduct quantization to each patch based on the allocated bit-width. The proposed Delta-DCT does not require any training or data calibration, while achieving performance comparable to or even surpassing original finetuned models under 1-bit equivalent delta compression ratios on different kinds of models including: (1) recently-released LLMs of different sizes from 7B to 13B, (2) relatively smaller language models including RoBERTa and T5 models, (3) variants of vision transformer models, and (4) multi-modal BEiT-3 models.
FREE-Merging: Fourier Transform for Model Merging with Lightweight Experts
Nov 25, 2024



In the current era of rapid expansion in model scale, there is an increasing availability of open-source model weights for various tasks. However, the capabilities of a single fine-tuned model often fall short of meeting diverse deployment needs. Model merging has thus emerged as a widely focused method for efficiently building a single model tailored for multiple tasks combined from existing models. Nevertheless, existing model merging methods face challenging trade-offs between performance and deployment costs, primarily due to task conflicts within the merged network. Our analysis of neural networks reveals that some task-specific information introduced by fine-tuning minimally enhances performance but heavily impacts generalization, leading to task conflicts. To mitigate the impact of this information, we propose FR-Merging, an innovative method that leverages frequency domain information to efficiently filter harmful specialized information, thereby minimizing the impact of task conflicts on the backbone with minimal cost. Since performance loss is inevitable with cost-free merging methods, we introduce a lightweight task-specific expert that can be dynamically integrated during inference to compensate for information loss. This framework, FREE-Merging (FR-Merging with lightweight experts), strikes a balanced trade-off between training cost, inference speed, storage requirements, and performance. We demonstrate the effectiveness of both FR-Merging and FREE-Merging on multiple tasks across CV, NLP, and Multi-Modal domains and show that they can be flexibly adapted to meet specific needs.
IntraMix: Intra-Class Mixup Generation for Accurate Labels and Neighbors
May 02, 2024



Graph Neural Networks (GNNs) demonstrate excellent performance on graphs, with their core idea about aggregating neighborhood information and learning from labels. However, the prevailing challenges in most graph datasets are twofold of Insufficient High-Quality Labels and Lack of Neighborhoods, resulting in weak GNNs. Existing data augmentation methods designed to address these two issues often tackle only one. They may either require extensive training of generators, rely on overly simplistic strategies, or demand substantial prior knowledge, leading to suboptimal generalization abilities. To simultaneously address both of these two challenges, we propose an elegant method called IntraMix. IntraMix innovatively employs Mixup among low-quality labeled data of the same class, generating high-quality labeled data at minimal cost. Additionally, it establishes neighborhoods for the generated data by connecting them with data from the same class with high confidence, thereby enriching the neighborhoods of graphs. IntraMix efficiently tackles both challenges faced by graphs and challenges the prior notion of the limited effectiveness of Mixup in node classification. IntraMix serves as a universal framework that can be readily applied to all GNNs. Extensive experiments demonstrate the effectiveness of IntraMix across various GNNs and datasets.