 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCLP: Neural Architecture Predictor with Curriculum Contrastive Learning
Feb 25, 2023
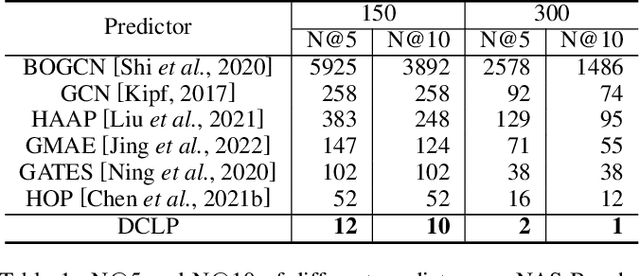
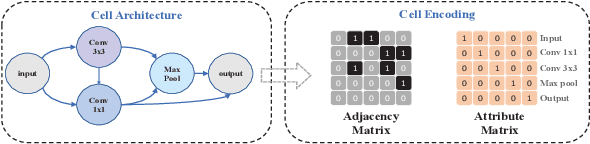

Neural predictors currently show great potential in the performance evaluation phase of neural architecture search (NAS). Despite their efficiency in the evaluation process, it is challenging to train the predictor with fewer architecture evaluations for efficient NAS. However, most of the current approaches are more concerned with improving the structure of the predictor to solve this problem, while the full use of the information contained in unlabeled data is less explored. To address this issue, we introduce a contrastive learning framework with curriculum learning guidance for the neural predictor called DCLP. To be specific, we develop a plan for the training order of positive samples during pre-training through the proposed difficulty measurer and training scheduler, and utilize the contrastive learner to learn representations of data. Compared with existing predictors, we experimentally demonstrate that DCLP has high accuracy and efficiency, and also shows an encouraging ability to discover superior architectures in multiple search spaces when combined with search strategies.
Auto-CASH: Autonomous Classification Algorithm Selection with Deep Q-Network
Jul 07, 2020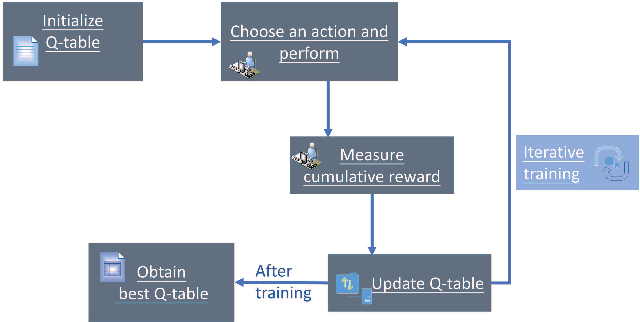

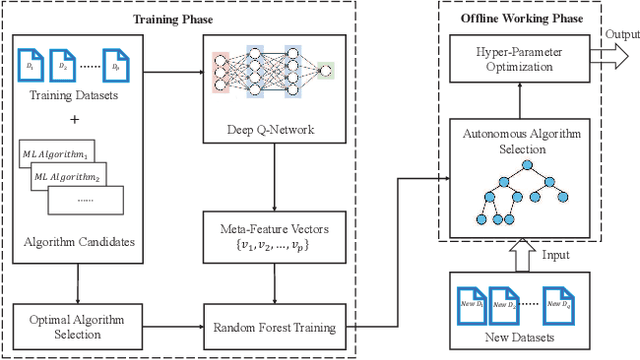
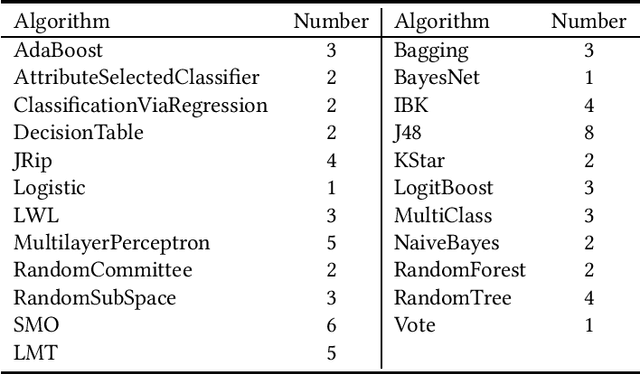
The great amount of datasets generated by various data sources have posed the challenge to machine learning algorithm selection and hyperparameter configuration. For a specific machine learning task, it usually takes domain experts plenty of time to select an appropriate algorithm and configure its hyperparameters. If the problem of algorithm selection and hyperparameter optimization can be solved automatically, the task will be executed more efficiently with performance guarantee. Such problem is also known as the CASH problem. Early work either requires a large amount of human labor, or suffers from high time or space complexity. In our work, we present Auto-CASH, a pre-trained model based on meta-learning, to solve the CASH problem more efficiently. Auto-CASH is the first approach that utilizes Deep Q-Network to automatically select the meta-features for each dataset, thus reducing the time cost tremendously without introducing too much human labor. To demonstrate the effectiveness of our model, we conduct extensive experiments on 120 real-world classification datasets. Compared with classical and the state-of-art CASH approaches, experimental results show that Auto-CASH achieves better performance within shorter time.
Auto-Model: Utilizing Research Papers and HPO Techniques to Deal with the CASH problem
Oct 24, 2019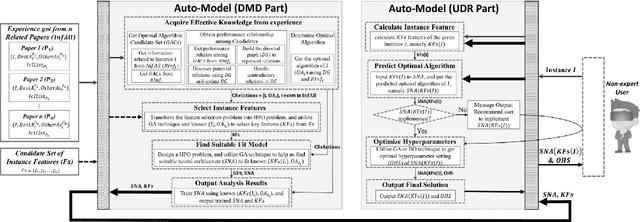



In many fields, a mass of algorithms with completely different hyperparameters have been developed to address the same type of problems. Choosing the algorithm and hyperparameter setting correctly can promote the overall performance greatly, but users often fail to do so due to the absence of knowledge. How to help users to effectively and quickly select the suitable algorithm and hyperparameter settings for the given task instance is an important research topic nowadays, which is known as the CASH problem. In this paper, we design the Auto-Model approach, which makes full use of known information in the related research paper and introduces hyperparameter optimization techniques, to solve the CASH problem effectively. Auto-Model tremendously reduces the cost of algorithm implementations and hyperparameter configuration space, and thus capable of dealing with the CASH problem efficiently and easily. To demonstrate the benefit of Auto-Model, we compare it with classical Auto-Weka approach. The experimental results show that our proposed approach can provide superior results and achieves better performance in a short time.