 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoTS: Automatic Time Series Forecasting Model Design Based on Two-Stage Pruning
Mar 26, 2022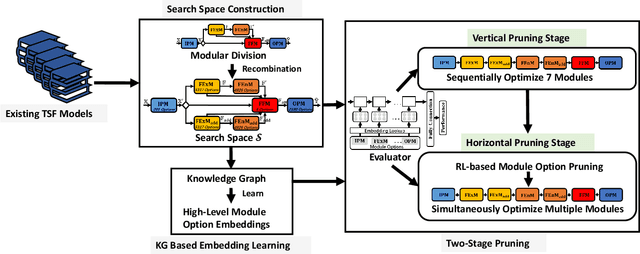
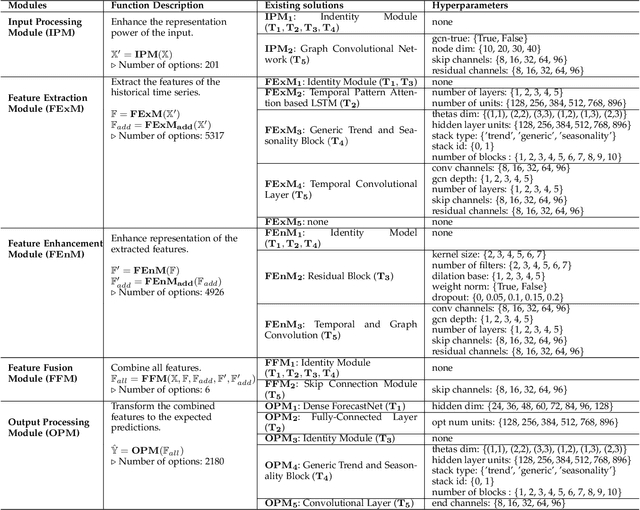
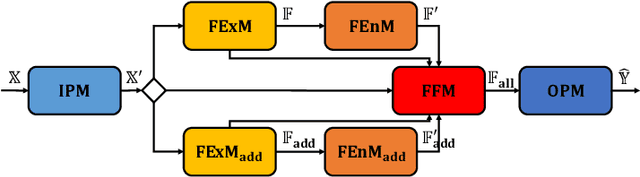

Automatic Time Series Forecasting (TSF) model design which aims to help users to efficiently design suitable forecasting model for the given time series data scenarios, is a novel research topic to be urgently solved. In this paper, we propose AutoTS algorithm trying to utilize the existing design skills and design efficient search methods to effectively solve this problem. In AutoTS, we extract effective design experience from the existing TSF works. We allow the effective combination of design experience from different sources, so as to create an effective search space containing a variety of TSF models to support different TSF tasks. Considering the huge search space, in AutoTS, we propose a two-stage pruning strategy to reduce the search difficulty and improve the search efficiency. In addition, in AutoTS, we introduce the knowledge graph to reveal associations between module options. We make full use of these relational information to learn higher-level features of each module option, so as to further improve the search quality. Extensive experimental results show that AutoTS is well-suited for the TSF area. It is more efficient than the existing neural architecture search algorithms, and can quickly design powerful TSF model better than the manually designed ones.
AutoMC: Automated Model Compression based on Domain Knowledge and Progressive search strategy
Jan 24, 2022



Model compression methods can reduce model complexity on the premise of maintaining acceptable performance, and thus promote the application of deep neural networks under resource constrained environments. Despite their great success, the selection of suitable compression methods and design of details of the compression scheme are difficult, requiring lots of domain knowledge as support, which is not friendly to non-expert users. To make more users easily access to the model compression scheme that best meet their needs, in this paper, we propose AutoMC, an effective automatic tool for model compression. AutoMC builds the domain knowledge on model compression to deeply understand the characteristics and advantages of each compression method under different settings. In addition, it presents a progressive search strategy to efficiently explore pareto optimal compression scheme according to the learned prior knowledge combined with the historical evaluation information. Extensive experimental results show that AutoMC can provide satisfying compression schemes within short time, demonstrating the effectiveness of AutoMC.
TPAD: Identifying Effective Trajectory Predictions Under the Guidance of Trajectory Anomaly Detection Model
Jan 09, 2022
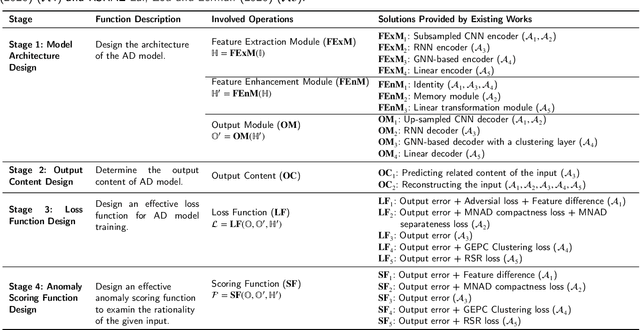


Trajectory Prediction (TP) is an important research topic in computer vision and robotics fields. Recently, many stochastic TP models have been proposed to deal with this problem and have achieved better performance than the traditional models with deterministic trajectory outputs. However, these stochastic models can generate a number of future trajectories with different qualities. They are lack of self-evaluation ability, that is, to examine the rationality of their prediction results, thus failing to guide users to identify high-quality ones from their candidate results. This hinders them from playing their best in real applications. In this paper, we make up for this defect and propose TPAD, a novel TP evaluation method based on the trajectory Anomaly Detection (AD) technique. In TPAD, we firstly combine the Automated Machine Learning (AutoML) technique and the experience in the AD and TP field to automatically design an effective trajectory AD model. Then, we utilize the learned trajectory AD model to examine the rationality of the predicted trajectories, and screen out good TP results for users. Extensive experimental results demonstrate that TPAD can effectively identify near-optimal prediction results, improving stochastic TP models' practical application effect.
Search For Deep Graph Neural Networks
Sep 21, 2021

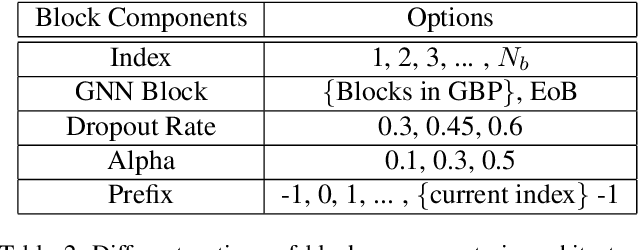
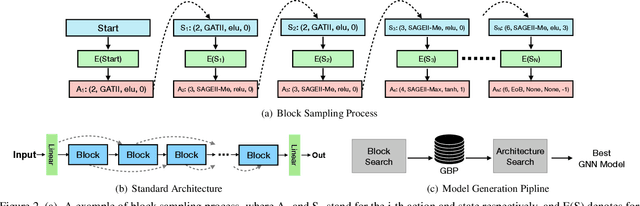
Current GNN-oriented NAS methods focus on the search for different layer aggregate components with shallow and simple architectures, which are limited by the 'over-smooth' problem. To further explore the benefits from structural diversity and depth of GNN architectures, we propose a GNN generation pipeline with a novel two-stage search space, which aims at automatically generating high-performance while transferable deep GNN models in a block-wise manner. Meanwhile, to alleviate the 'over-smooth' problem, we incorporate multiple flexible residual connection in our search space and apply identity mapping in the basic GNN layers. For the search algorithm, we use deep-q-learning with epsilon-greedy exploration strategy and reward reshaping. Extensive experiments on real-world datasets show that our generated GNN models outperforms existing manually designed and NAS-based ones.
FL-AGCNS: Federated Learning Framework for Automatic Graph Convolutional Network Search
Apr 09, 2021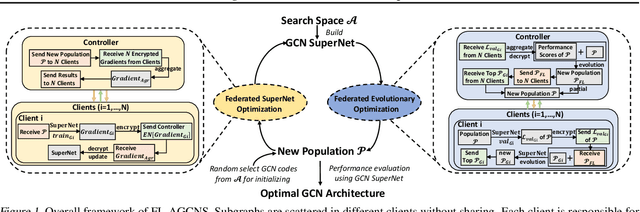
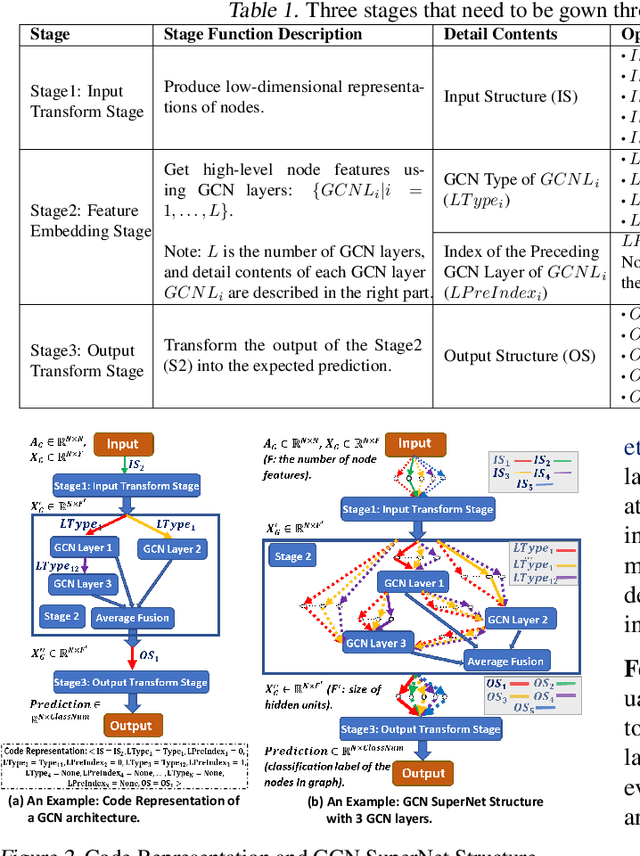

Recently, some Neural Architecture Search (NAS) techniques are proposed for the automatic design of Graph Convolutional Network (GCN) architectures. They bring great convenience to the use of GCN, but could hardly apply to the Federated Learning (FL) scenarios with distributed and private datasets, which limit their applications. Moreover, they need to train many candidate GCN models from scratch, which is inefficient for FL. To address these challenges, we propose FL-AGCNS, an efficient GCN NAS algorithm suitable for FL scenarios. FL-AGCNS designs a federated evolutionary optimization strategy to enable distributed agents to cooperatively design powerful GCN models while keeping personal information on local devices. Besides, it applies the GCN SuperNet and a weight sharing strategy to speed up the evaluation of GCN models. Experimental results show that FL-AGCNS can find better GCN models in short time under the FL framework, surpassing the state-of-the-arts NAS methods and GCN models.
Auto-STGCN: Autonomous Spatial-Temporal Graph Convolutional Network Search Based on Reinforcement Learning and Existing Research Results
Oct 15, 2020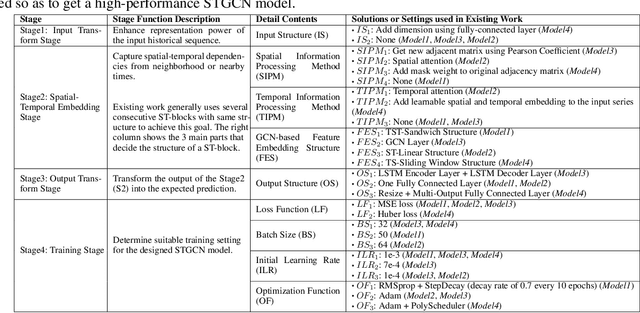
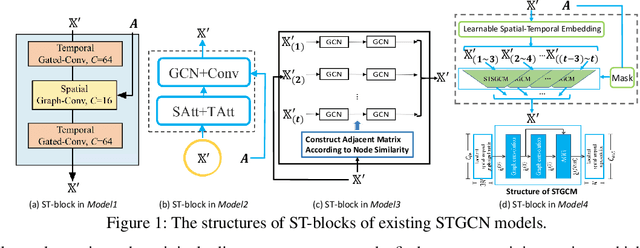
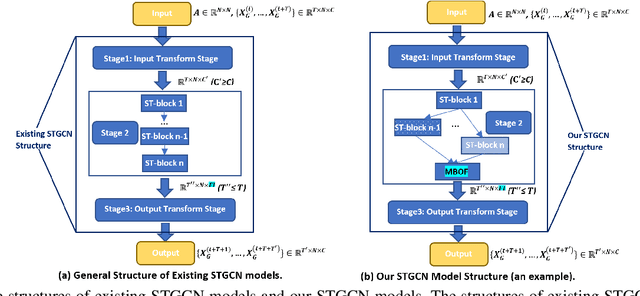
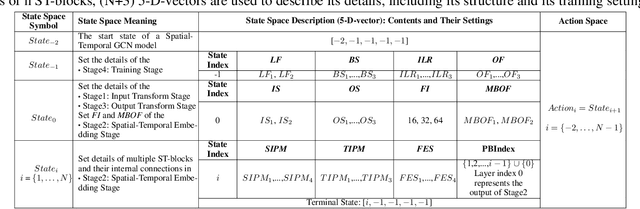
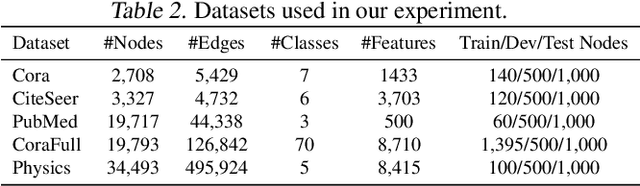
In recent years, many spatial-temporal graph convolutional network (STGCN) models are proposed to deal with the spatial-temporal network data forecasting problem. These STGCN models have their own advantages, i.e., each of them puts forward many effective operations and achieves good prediction results in the real applications. If users can effectively utilize and combine these excellent operations integrating the advantages of existing models, then they may obtain more effective STGCN models thus create greater value using existing work. However, they fail to do so due to the lack of domain knowledge, and there is lack of automated system to help users to achieve this goal. In this paper, we fill this gap and propose Auto-STGCN algorithm, which makes use of existing models to automatically explore high-performance STGCN model for specific scenarios. Specifically, we design Unified-STGCN framework, which summarizes the operations of existing architectures, and use parameters to control the usage and characteristic attributes of each operation, so as to realize the parameterized representation of the STGCN architecture and the reorganization and fusion of advantages. Then, we present Auto-STGCN, an optimization method based on reinforcement learning, to quickly search the parameter search space provided by Unified-STGCN, and generate optimal STGCN models automatically. Extensive experiments on real-world benchmark datasets show that our Auto-STGCN can find STGCN models superior to existing STGCN models with heuristic parameters, which demonstrates the effectiveness of our proposed method.
Auto-CASH: Autonomous Classification Algorithm Selection with Deep Q-Network
Jul 07, 2020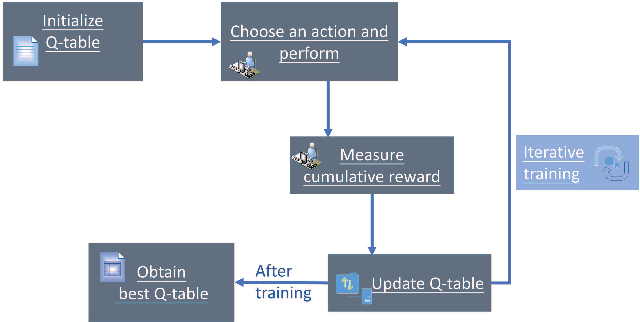

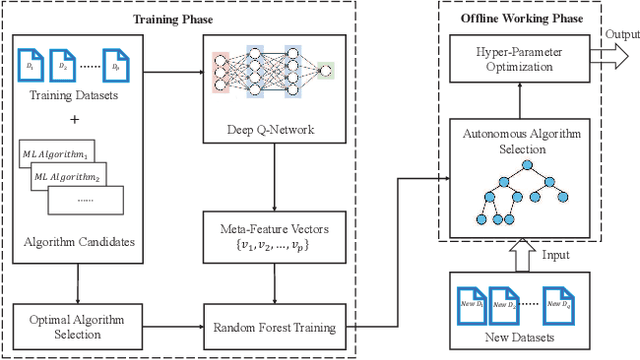
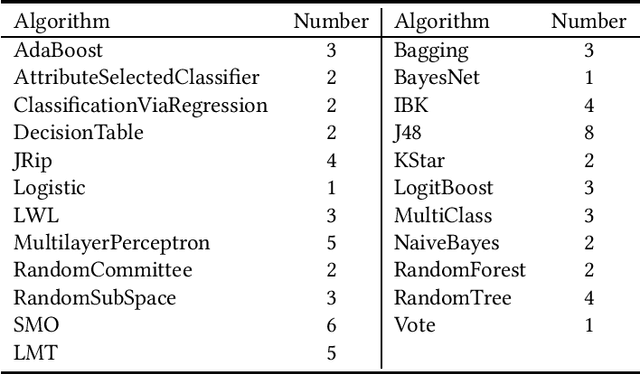
The great amount of datasets generated by various data sources have posed the challenge to machine learning algorithm selection and hyperparameter configuration. For a specific machine learning task, it usually takes domain experts plenty of time to select an appropriate algorithm and configure its hyperparameters. If the problem of algorithm selection and hyperparameter optimization can be solved automatically, the task will be executed more efficiently with performance guarantee. Such problem is also known as the CASH problem. Early work either requires a large amount of human labor, or suffers from high time or space complexity. In our work, we present Auto-CASH, a pre-trained model based on meta-learning, to solve the CASH problem more efficiently. Auto-CASH is the first approach that utilizes Deep Q-Network to automatically select the meta-features for each dataset, thus reducing the time cost tremendously without introducing too much human labor. To demonstrate the effectiveness of our model, we conduct extensive experiments on 120 real-world classification datasets. Compared with classical and the state-of-art CASH approaches, experimental results show that Auto-CASH achieves better performance within shorter time.
Multi-Objective Neural Architecture Search Based on Diverse Structures and Adaptive Recommendation
Jul 06, 2020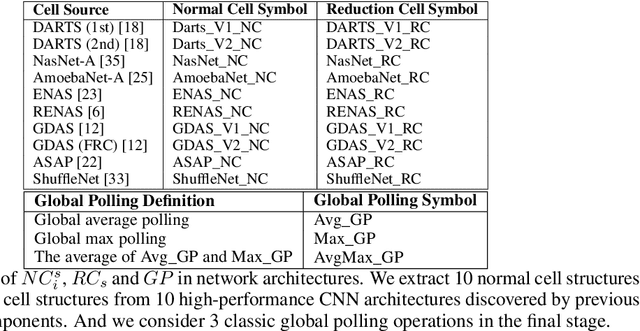
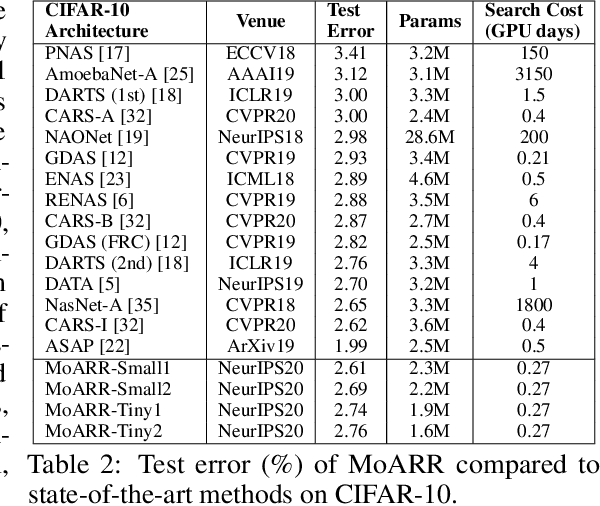
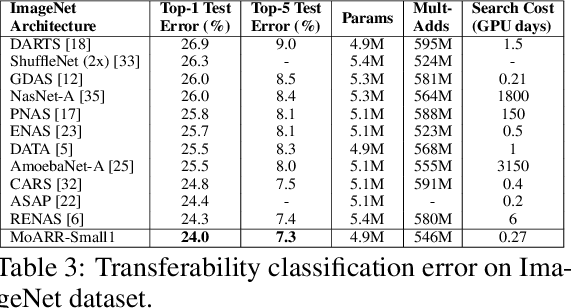
The search space of neural architecture search (NAS) for convolutional neural network (CNN) is huge. To reduce searching cost, most NAS algorithms use fixed outer network level structure, and search the repeatable cell structure only. Such kind of fixed architecture performs well when enough cells and channels are used. However, when the architecture becomes more lightweight, the performance decreases significantly. To obtain better lightweight architectures, more flexible and diversified neural architectures are in demand, and more efficient methods should be designed for larger search space. Motivated by this, we propose MoARR algorithm, which utilizes the existing research results and historical information to quickly find architectures that are both lightweight and accurate. We use the discovered high-performance cells to construct network architectures. This method increases the network architecture diversity while also reduces the search space of cell structure design. In addition, we designs a novel multi-objective method to effectively analyze the historical evaluation information, so as to efficiently search for the Pareto optimal architectures with high accuracy and small parameter number. Experimental results show that our MoARR can achieve a powerful and lightweight model (with 1.9% error rate and 2.3M parameters) on CIFAR-10 in 6 GPU hours, which is better than the state-of-the-arts. The explored architecture is transferable to ImageNet and achieves 76.0% top-1 accuracy with 4.9M parameters.
Automatic Hyper-Parameter Optimization Based on Mapping Discovery from Data to Hyper-Parameters
Mar 03, 2020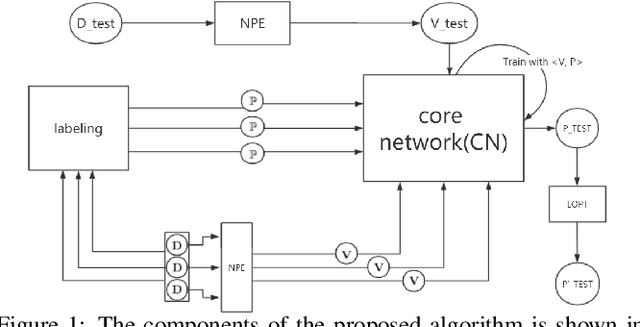
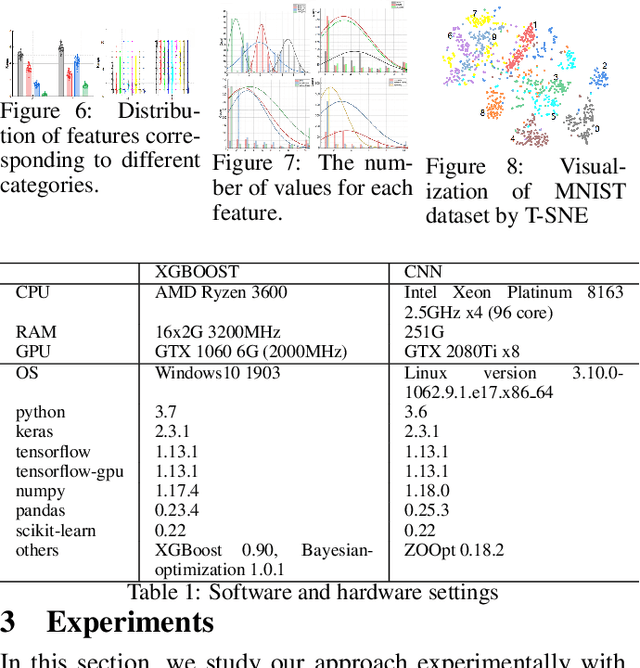
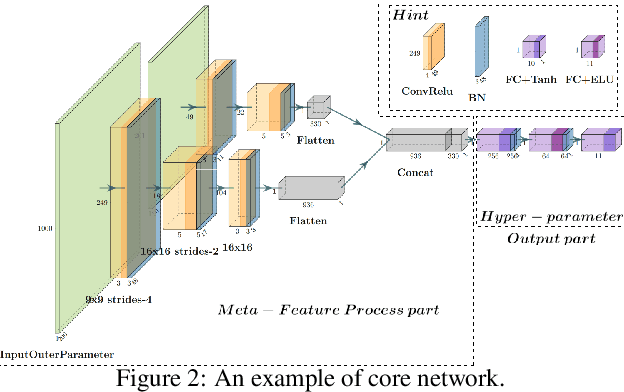
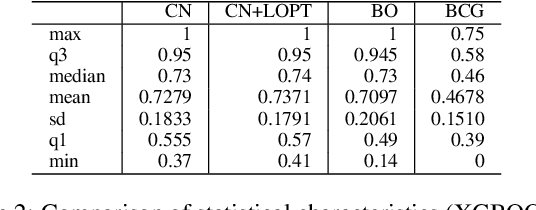
Machine learning algorithms have made remarkable achievements in the field of artificial intelligence. However, most machine learning algorithms are sensitive to the hyper-parameters. Manually optimizing the hyper-parameters is a common method of hyper-parameter tuning. However, it is costly and empirically dependent. Automatic hyper-parameter optimization (autoHPO) is favored due to its effectiveness. However, current autoHPO methods are usually only effective for a certain type of problems, and the time cost is high. In this paper, we propose an efficient automatic parameter optimization approach, which is based on the mapping from data to the corresponding hyper-parameters. To describe such mapping, we propose a sophisticated network structure. To obtain such mapping, we develop effective network constrution algorithms. We also design strategy to optimize the result futher during the application of the mapping. Extensive experimental results demonstrate that the proposed approaches outperform the state-of-the-art apporaches significantly.
ExperienceThinking: Hyperparameter Optimization with Budget Constraints
Dec 02, 2019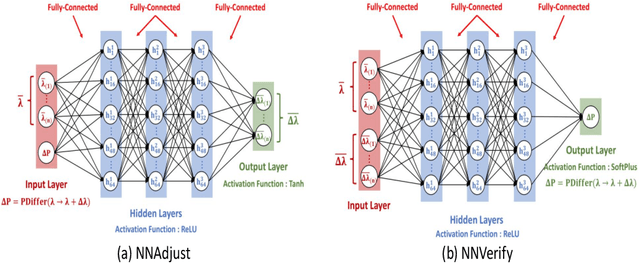
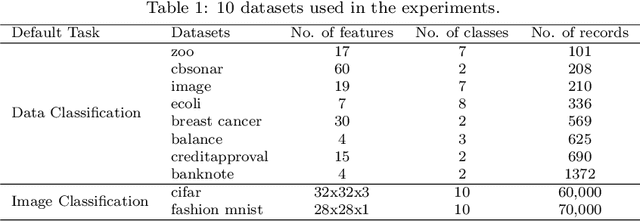
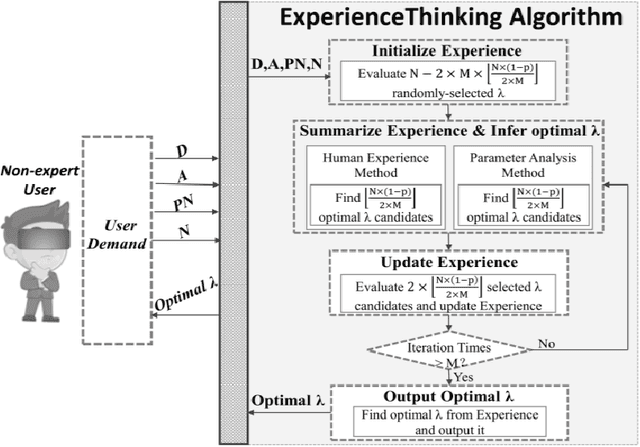
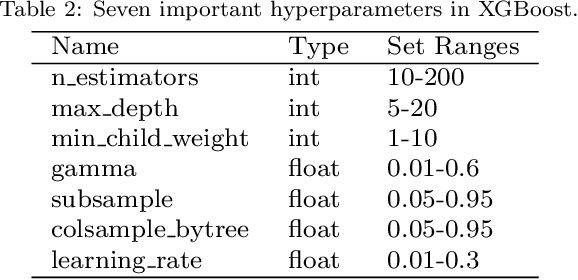
The problem of hyperparameter optimization exists widely in the real life and many common tasks can be transformed into it, such as neural architecture search and feature subset selection. Without considering various constraints, the existing hyperparameter tuning techniques can solve these problems effectively by traversing as many hyperparameter configurations as possible. However, because of the limited resources and budget, it is not feasible to evaluate so many kinds of configurations, which requires us to design effective algorithms to find a best possible hyperparameter configuration with a finite number of configuration evaluations. In this paper, we simulate human thinking processes and combine the merit of the existing techniques, and thus propose a new algorithm called ExperienceThinking, trying to solve this constrained hyperparameter optimization problem. In addition, we analyze the performances of 3 classical hyperparameter optimization algorithms with a finite number of configuration evaluations, and compare with that of ExperienceThinking. The experimental results show that our proposed algorithm provides superior results and has better performance.