 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdisum: Summarizing and Explaining Wikipedia Edits at Scale
Apr 04, 2024An edit summary is a succinct comment written by a Wikipedia editor explaining the nature of, and reasons for, an edit to a Wikipedia page. Edit summaries are crucial for maintaining the encyclopedia: they are the first thing seen by content moderators and help them decide whether to accept or reject an edit. Additionally, edit summaries constitute a valuable data source for researchers. Unfortunately, as we show, for many edits, summaries are either missing or incomplete. To overcome this problem and help editors write useful edit summaries, we propose a model for recommending edit summaries generated by a language model trained to produce good edit summaries given the representation of an edit diff. This is a challenging task for multiple reasons, including mixed-quality training data, the need to understand not only what was changed in the article but also why it was changed, and efficiency requirements imposed by the scale of Wikipedia. We address these challenges by curating a mix of human and synthetically generated training data and fine-tuning a generative language model sufficiently small to be used on Wikipedia at scale. Our model performs on par with human editors. Commercial large language models are able to solve this task better than human editors, but would be too expensive to run on Wikipedia at scale. More broadly, this paper showcases how language modeling technology can be used to support humans in maintaining one of the largest and most visible projects on the Web.
Search For Deep Graph Neural Networks
Sep 21, 2021

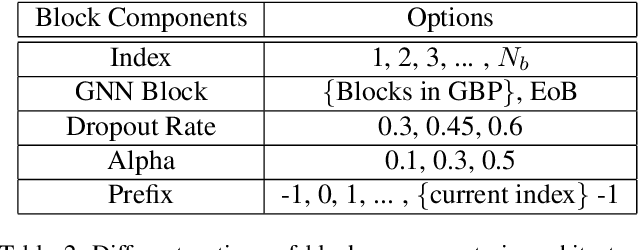
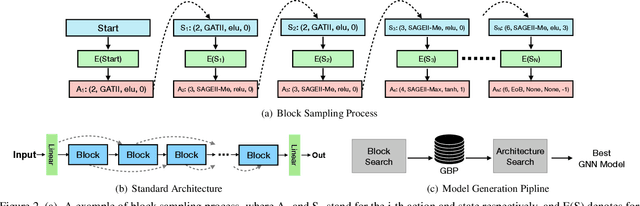
Current GNN-oriented NAS methods focus on the search for different layer aggregate components with shallow and simple architectures, which are limited by the 'over-smooth' problem. To further explore the benefits from structural diversity and depth of GNN architectures, we propose a GNN generation pipeline with a novel two-stage search space, which aims at automatically generating high-performance while transferable deep GNN models in a block-wise manner. Meanwhile, to alleviate the 'over-smooth' problem, we incorporate multiple flexible residual connection in our search space and apply identity mapping in the basic GNN layers. For the search algorithm, we use deep-q-learning with epsilon-greedy exploration strategy and reward reshaping. Extensive experiments on real-world datasets show that our generated GNN models outperforms existing manually designed and NAS-based ones.