 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Machine-Generated Short Descriptions into the Wikipedia Android App: A Pilot Deployment of Descartes
Jan 12, 2026Short descriptions are a key part of the Wikipedia user experience, but their coverage remains uneven across languages and topics. In previous work, we introduced Descartes, a multilingual model for generating short descriptions. In this report, we present the results of a pilot deployment of Descartes in the Wikipedia Android app, where editors were offered suggestions based on outputs from Descartes while editing short descriptions. The experiment spanned 12 languages, with over 3,900 articles and 375 editors participating. Overall, 90% of accepted Descartes descriptions were rated at least 3 out of 5 in quality, and their average ratings were comparable to human-written ones. Editors adopted machine suggestions both directly and with modifications, while the rate of reverts and reports remained low. The pilot also revealed practical considerations for deployment, including latency, language-specific gaps, and the need for safeguards around sensitive topics. These results indicate that Descartes's short descriptions can support editors in reducing content gaps, provided that technical, design, and community guardrails are in place.
Combining Constrained and Unconstrained Decoding via Boosting: BoostCD and Its Application to Information Extraction
Jun 17, 2025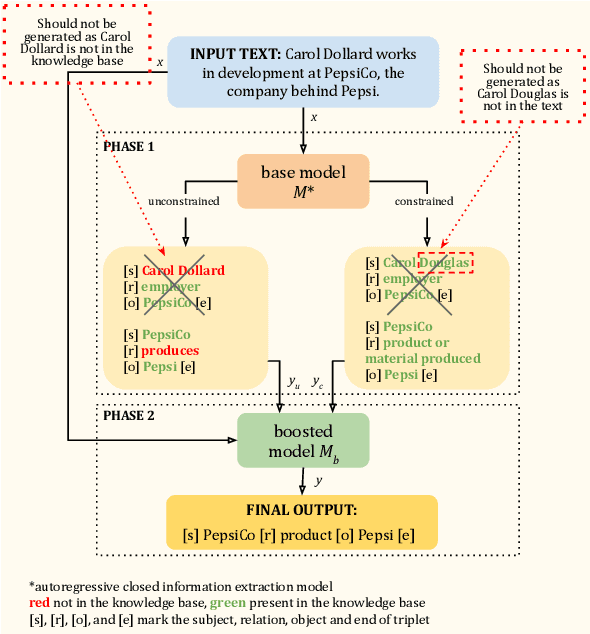
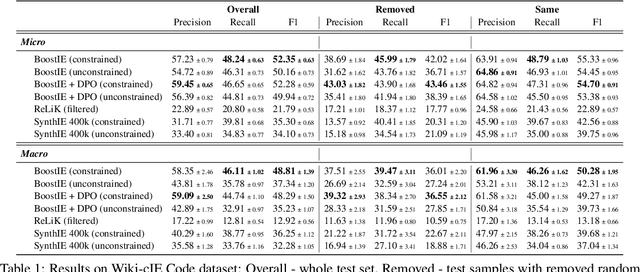
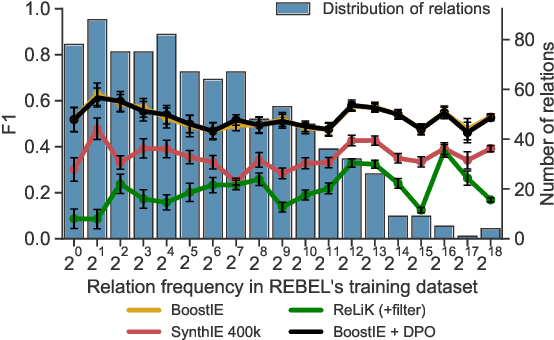
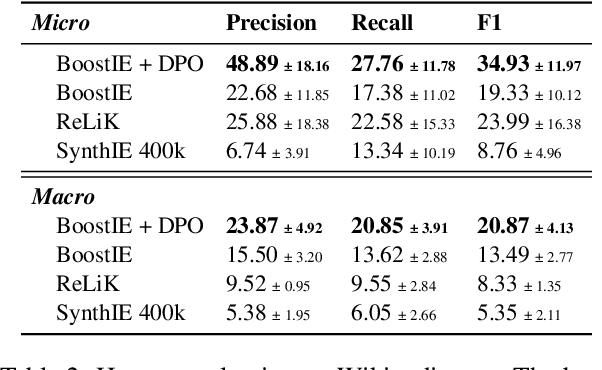
Many recent approaches to structured NLP tasks use an autoregressive language model $M$ to map unstructured input text $x$ to output text $y$ representing structured objects (such as tuples, lists, trees, code, etc.), where the desired output structure is enforced via constrained decoding. During training, these approaches do not require the model to be aware of the constraints, which are merely implicit in the training outputs $y$. This is advantageous as it allows for dynamic constraints without requiring retraining, but can lead to low-quality output during constrained decoding at test time. We overcome this problem with Boosted Constrained Decoding (BoostCD), which combines constrained and unconstrained decoding in two phases: Phase 1 decodes from the base model $M$ twice, in constrained and unconstrained mode, obtaining two weak predictions. In phase 2, a learned autoregressive boosted model combines the two weak predictions into one final prediction. The mistakes made by the base model with vs. without constraints tend to be complementary, which the boosted model learns to exploit for improved performance. We demonstrate the power of BoostCD by applying it to closed information extraction. Our model, BoostIE, outperforms prior approaches both in and out of distribution, addressing several common errors identified in those approaches.
Edisum: Summarizing and Explaining Wikipedia Edits at Scale
Apr 04, 2024An edit summary is a succinct comment written by a Wikipedia editor explaining the nature of, and reasons for, an edit to a Wikipedia page. Edit summaries are crucial for maintaining the encyclopedia: they are the first thing seen by content moderators and help them decide whether to accept or reject an edit. Additionally, edit summaries constitute a valuable data source for researchers. Unfortunately, as we show, for many edits, summaries are either missing or incomplete. To overcome this problem and help editors write useful edit summaries, we propose a model for recommending edit summaries generated by a language model trained to produce good edit summaries given the representation of an edit diff. This is a challenging task for multiple reasons, including mixed-quality training data, the need to understand not only what was changed in the article but also why it was changed, and efficiency requirements imposed by the scale of Wikipedia. We address these challenges by curating a mix of human and synthetically generated training data and fine-tuning a generative language model sufficiently small to be used on Wikipedia at scale. Our model performs on par with human editors. Commercial large language models are able to solve this task better than human editors, but would be too expensive to run on Wikipedia at scale. More broadly, this paper showcases how language modeling technology can be used to support humans in maintaining one of the largest and most visible projects on the Web.
Fly-Swat or Cannon? Cost-Effective Language Model Choice via Meta-Modeling
Aug 11, 2023



Generative language models (LMs) have become omnipresent across data science. For a wide variety of tasks, inputs can be phrased as natural language prompts for an LM, from whose output the solution can then be extracted. LM performance has consistently been increasing with model size - but so has the monetary cost of querying the ever larger models. Importantly, however, not all inputs are equally hard: some require larger LMs for obtaining a satisfactory solution, whereas for others smaller LMs suffice. Based on this fact, we design a framework for Cost-Effective Language Model Choice (CELMOC). Given a set of inputs and a set of candidate LMs, CELMOC judiciously assigns each input to an LM predicted to do well on the input according to a so-called meta-model, aiming to achieve high overall performance at low cost. The cost-performance trade-off can be flexibly tuned by the user. Options include, among others, maximizing total expected performance (or the number of processed inputs) while staying within a given cost budget, or minimizing total cost while processing all inputs. We evaluate CELMOC on 14 datasets covering five natural language tasks, using four candidate LMs of vastly different size and cost. With CELMOC, we match the performance of the largest available LM while achieving a cost reduction of 63%. Via our publicly available library, researchers as well as practitioners can thus save large amounts of money without sacrificing performance.