 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Machine-Generated Short Descriptions into the Wikipedia Android App: A Pilot Deployment of Descartes
Jan 12, 2026Short descriptions are a key part of the Wikipedia user experience, but their coverage remains uneven across languages and topics. In previous work, we introduced Descartes, a multilingual model for generating short descriptions. In this report, we present the results of a pilot deployment of Descartes in the Wikipedia Android app, where editors were offered suggestions based on outputs from Descartes while editing short descriptions. The experiment spanned 12 languages, with over 3,900 articles and 375 editors participating. Overall, 90% of accepted Descartes descriptions were rated at least 3 out of 5 in quality, and their average ratings were comparable to human-written ones. Editors adopted machine suggestions both directly and with modifications, while the rate of reverts and reports remained low. The pilot also revealed practical considerations for deployment, including latency, language-specific gaps, and the need for safeguards around sensitive topics. These results indicate that Descartes's short descriptions can support editors in reducing content gaps, provided that technical, design, and community guardrails are in place.
Edisum: Summarizing and Explaining Wikipedia Edits at Scale
Apr 04, 2024An edit summary is a succinct comment written by a Wikipedia editor explaining the nature of, and reasons for, an edit to a Wikipedia page. Edit summaries are crucial for maintaining the encyclopedia: they are the first thing seen by content moderators and help them decide whether to accept or reject an edit. Additionally, edit summaries constitute a valuable data source for researchers. Unfortunately, as we show, for many edits, summaries are either missing or incomplete. To overcome this problem and help editors write useful edit summaries, we propose a model for recommending edit summaries generated by a language model trained to produce good edit summaries given the representation of an edit diff. This is a challenging task for multiple reasons, including mixed-quality training data, the need to understand not only what was changed in the article but also why it was changed, and efficiency requirements imposed by the scale of Wikipedia. We address these challenges by curating a mix of human and synthetically generated training data and fine-tuning a generative language model sufficiently small to be used on Wikipedia at scale. Our model performs on par with human editors. Commercial large language models are able to solve this task better than human editors, but would be too expensive to run on Wikipedia at scale. More broadly, this paper showcases how language modeling technology can be used to support humans in maintaining one of the largest and most visible projects on the Web.
Leveraging Recommender Systems to Reduce Content Gaps on Peer Production Platforms
Jul 18, 2023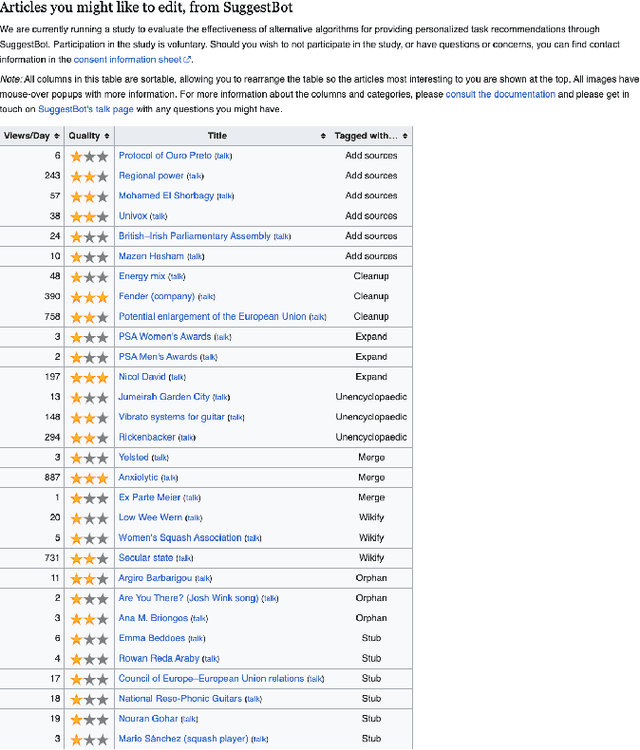
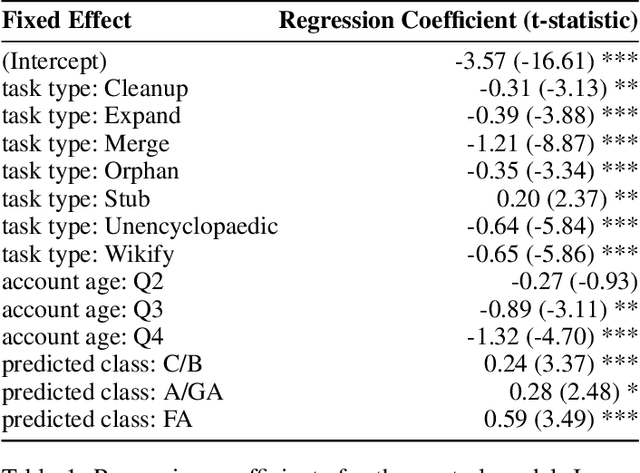
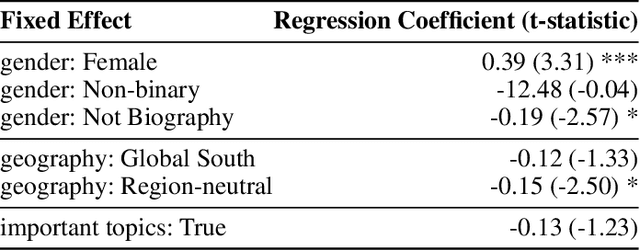
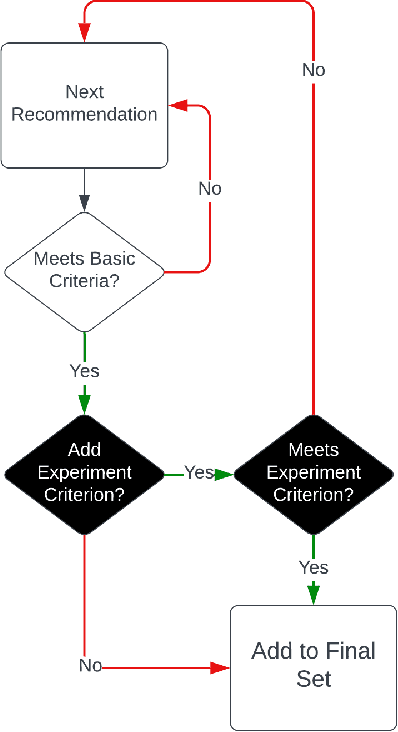
Peer production platforms like Wikipedia commonly suffer from content gaps. Prior research suggests recommender systems can help solve this problem, by guiding editors towards underrepresented topics. However, it remains unclear whether this approach would result in less relevant recommendations, leading to reduced overall engagement with recommended items. To answer this question, we first conducted offline analyses (Study 1) on SuggestBot, a task-routing recommender system for Wikipedia, then did a three-month controlled experiment (Study 2). Our results show that presenting users with articles from underrepresented topics increased the proportion of work done on those articles without significantly reducing overall recommendation uptake. We discuss the implications of our results, including how ignoring the article discovery process can artificially narrow recommendations. We draw parallels between this phenomenon and the common issue of "filter bubbles" to show how any platform that employs recommender systems is susceptible to it.
Overview of the TREC 2021 Fair Ranking Track
Feb 21, 2023The TREC Fair Ranking Track aims to provide a platform for participants to develop and evaluate novel retrieval algorithms that can provide a fair exposure to a mixture of demographics or attributes, such as ethnicity, that are represented by relevant documents in response to a search query. For example, particular demographics or attributes can be represented by the documents' topical content or authors. The 2021 Fair Ranking Track adopted a resource allocation task. The task focused on supporting Wikipedia editors who are looking to improve the encyclopedia's coverage of topics under the purview of a WikiProject. WikiProject coordinators and/or Wikipedia editors search for Wikipedia documents that are in need of editing to improve the quality of the article. The 2021 Fair Ranking track aimed to ensure that documents that are about, or somehow represent, certain protected characteristics receive a fair exposure to the Wikipedia editors, so that the documents have an fair opportunity of being improved and, therefore, be well-represented in Wikipedia. The under-representation of particular protected characteristics in Wikipedia can result in systematic biases that can have a negative human, social, and economic impact, particularly for disadvantaged or protected societal groups.
Overview of the TREC 2022 Fair Ranking Track
Feb 11, 2023The TREC Fair Ranking Track aims to provide a platform for participants to develop and evaluate novel retrieval algorithms that can provide a fair exposure to a mixture of demographics or attributes, such as ethnicity, that are represented by relevant documents in response to a search query. For example, particular demographics or attributes can be represented by the documents topical content or authors. The 2022 Fair Ranking Track adopted a resource allocation task. The task focused on supporting Wikipedia editors who are looking to improve the encyclopedia's coverage of topics under the purview of a WikiProject. WikiProject coordinators and/or Wikipedia editors search for Wikipedia documents that are in need of editing to improve the quality of the article. The 2022 Fair Ranking track aimed to ensure that documents that are about, or somehow represent, certain protected characteristics receive a fair exposure to the Wikipedia editors, so that the documents have an fair opportunity of being improved and, therefore, be well-represented in Wikipedia. The under-representation of particular protected characteristics in Wikipedia can result in systematic biases that can have a negative human, social, and economic impact, particularly for disadvantaged or protected societal groups.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Considerations for Multilingual Wikipedia Research
Apr 05, 2022English Wikipedia has long been an important data source for much research and natural language machine learning modeling. The growth of non-English language editions of Wikipedia, greater computational resources, and calls for equity in the performance of language and multimodal models have led to the inclusion of many more language editions of Wikipedia in datasets and models. Building better multilingual and multimodal models requires more than just access to expanded datasets; it also requires a better understanding of what is in the data and how this content was generated. This paper seeks to provide some background to help researchers think about what differences might arise between different language editions of Wikipedia and how that might affect their models. It details three major ways in which content differences between language editions arise (local context, community and governance, and technology) and recommendations for good practices when using multilingual and multimodal data for research and modeling.