 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat News Recommendation Research Did (But Mostly Didn't) Teach Us About Building A News Recommender
Sep 15, 2025One of the goals of recommender systems research is to provide insights and methods that can be used by practitioners to build real-world systems that deliver high-quality recommendations to actual people grounded in their genuine interests and needs. We report on our experience trying to apply the news recommendation literature to build POPROX, a live platform for news recommendation research, and reflect on the extent to which the current state of research supports system-building efforts. Our experience highlights several unexpected challenges encountered in building personalization features that are commonly found in products from news aggregators and publishers, and shows how those difficulties are connected to surprising gaps in the literature. Finally, we offer a set of lessons learned from building a live system with a persistent user base and highlight opportunities to make future news recommendation research more applicable and impactful in practice.
We're Still Doing It (All) Wrong: Recommender Systems, Fifteen Years Later
Sep 11, 2025
In 2011, Xavier Amatriain sounded the alarm: recommender systems research was "doing it all wrong" [1]. His critique, rooted in statistical misinterpretation and methodological shortcuts, remains as relevant today as it was then. But rather than correcting course, we added new layers of sophistication on top of the same broken foundations. This paper revisits Amatriain's diagnosis and argues that many of the conceptual, epistemological, and infrastructural failures he identified still persist, in more subtle or systemic forms. Drawing on recent work in reproducibility, evaluation methodology, environmental impact, and participatory design, we showcase how the field's accelerating complexity has outpaced its introspection. We highlight ongoing community-led initiatives that attempt to shift the paradigm, including workshops, evaluation frameworks, and calls for value-sensitive and participatory research. At the same time, we contend that meaningful change will require not only new metrics or better tooling, but a fundamental reframing of what recommender systems research is for, who it serves, and how knowledge is produced and validated. Our call is not just for technical reform, but for a recommender systems research agenda grounded in epistemic humility, human impact, and sustainable practice.
User and Recommender Behavior Over Time: Contextualizing Activity, Effectiveness, Diversity, and Fairness in Book Recommendation
May 07, 2025



Data is an essential resource for studying recommender systems. While there has been significant work on improving and evaluating state-of-the-art models and measuring various properties of recommender system outputs, less attention has been given to the data itself, particularly how data has changed over time. Such documentation and analysis provide guidance and context for designing and evaluating recommender systems, particularly for evaluation designs making use of time (e.g., temporal splitting). In this paper, we present a temporal explanatory analysis of the UCSD Book Graph dataset scraped from Goodreads, a social reading and recommendation platform active since 2006. We measure the book interaction data using a set of activity, diversity, and fairness metrics; we then train a set of collaborative filtering algorithms on rolling training windows to observe how the same measures evolve over time in the recommendations. Additionally, we explore whether the introduction of algorithmic recommendations in 2011 was followed by observable changes in user or recommender system behavior.
Candidate Set Sampling for Evaluating Top-N Recommendation
Sep 21, 2023



The strategy for selecting candidate sets -- the set of items that the recommendation system is expected to rank for each user -- is an important decision in carrying out an offline top-$N$ recommender system evaluation. The set of candidates is composed of the union of the user's test items and an arbitrary number of non-relevant items that we refer to as decoys. Previous studies have aimed to understand the effect of different candidate set sizes and selection strategies on evaluation. In this paper, we extend this knowledge by studying the specific interaction of candidate set selection strategies with popularity bias, and use simulation to assess whether sampled candidate sets result in metric estimates that are less biased with respect to the true metric values under complete data that is typically unavailable in ordinary experiments.
Towards Measuring Fairness in Grid Layout in Recommender Systems
Sep 19, 2023There has been significant research in the last five years on ensuring the providers of items in a recommender system are treated fairly, particularly in terms of the exposure the system provides to their work through its results. However, the metrics developed to date have all been designed and tested for linear ranked lists. It is unknown whether and how existing fair ranking metrics for linear layouts can be applied to grid-based displays. Moreover, depending on the device (phone, tab, or laptop) users use to interact with systems, column size is adjusted using column reduction approaches in a grid-view. The visibility or exposure of recommended items in grid layouts varies based on column sizes and column reduction approaches as well. In this paper, we extend existing fair ranking concepts and metrics to study provider-side group fairness in grid layouts, present an analysis of the behavior of these grid adaptations of fair ranking metrics, and study how their behavior changes across different grid ranking layout designs and geometries. We examine how fairness scores change with different ranking layouts to yield insights into (1) the consistency of fair ranking measurements across layouts; (2) whether rankings optimized for fairness in a linear ranking remain fair when the results are displayed in a grid; and (3) the impact of column reduction approaches to support different device geometries on fairness measurement. This work highlights the need to use layout-specific user attention models when measuring fairness of rankings, and provide practitioners with a first set of insights on what to expect when translating existing fair ranking metrics to the grid layouts in wide use today.
* 12 pages
Distributionally-Informed Recommender System Evaluation
Sep 12, 2023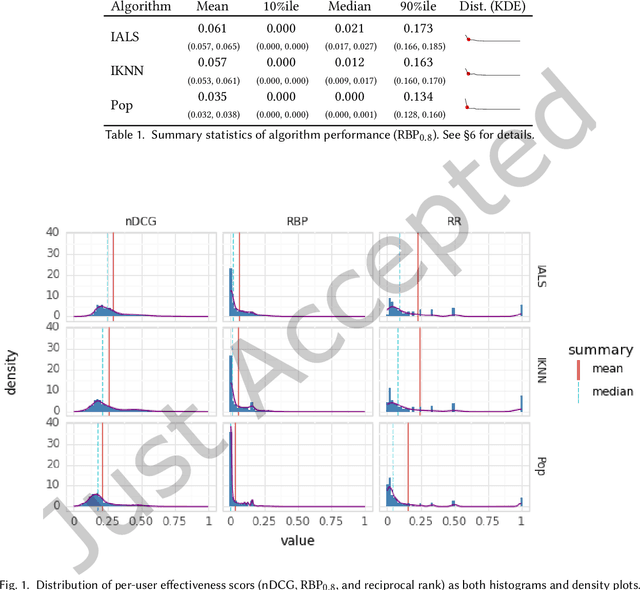
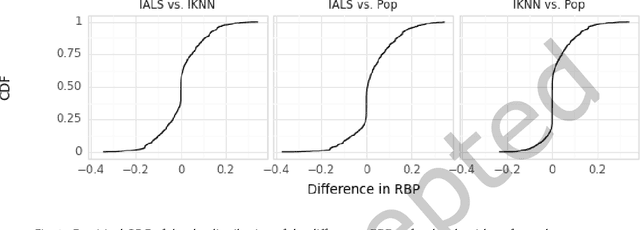
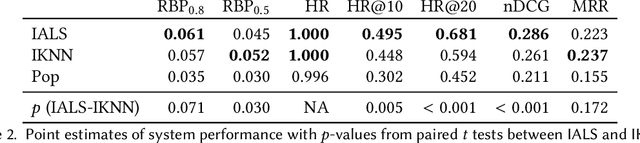
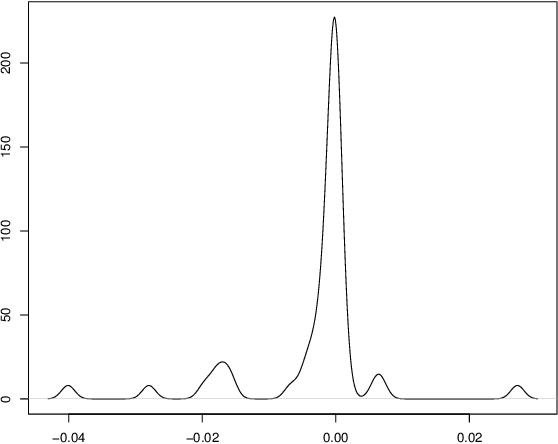
Current practice for evaluating recommender systems typically focuses on point estimates of user-oriented effectiveness metrics or business metrics, sometimes combined with additional metrics for considerations such as diversity and novelty. In this paper, we argue for the need for researchers and practitioners to attend more closely to various distributions that arise from a recommender system (or other information access system) and the sources of uncertainty that lead to these distributions. One immediate implication of our argument is that both researchers and practitioners must report and examine more thoroughly the distribution of utility between and within different stakeholder groups. However, distributions of various forms arise in many more aspects of the recommender systems experimental process, and distributional thinking has substantial ramifications for how we design, evaluate, and present recommender systems evaluation and research results. Leveraging and emphasizing distributions in the evaluation of recommender systems is a necessary step to ensure that the systems provide appropriate and equitably-distributed benefit to the people they affect.
Inference at Scale Significance Testing for Large Search and Recommendation Experiments
May 12, 2023
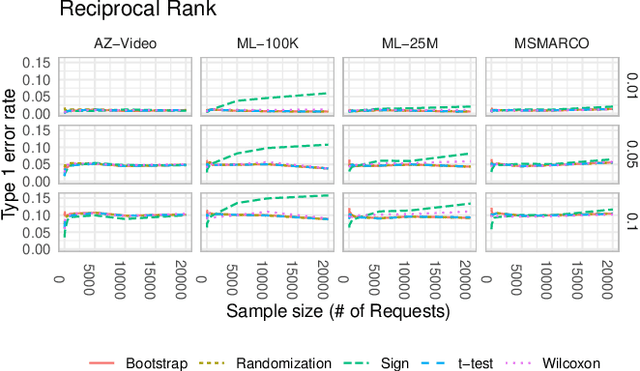
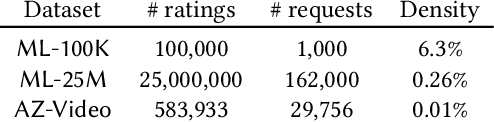
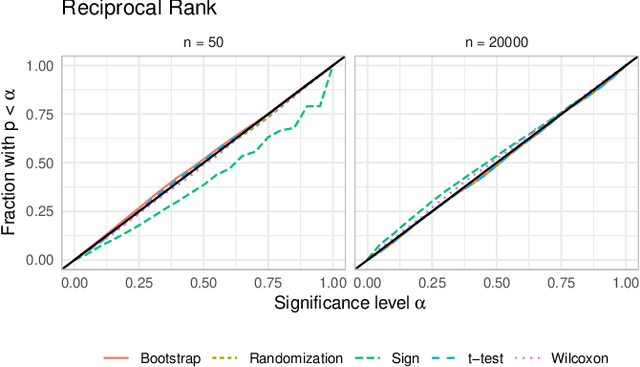
A number of information retrieval studies have been done to assess which statistical techniques are appropriate for comparing systems. However, these studies are focused on TREC-style experiments, which typically have fewer than 100 topics. There is no similar line of work for large search and recommendation experiments; such studies typically have thousands of topics or users and much sparser relevance judgements, so it is not clear if recommendations for analyzing traditional TREC experiments apply to these settings. In this paper, we empirically study the behavior of significance tests with large search and recommendation evaluation data. Our results show that the Wilcoxon and Sign tests show significantly higher Type-1 error rates for large sample sizes than the bootstrap, randomization and t-tests, which were more consistent with the expected error rate. While the statistical tests displayed differences in their power for smaller sample sizes, they showed no difference in their power for large sample sizes. We recommend the sign and Wilcoxon tests should not be used to analyze large scale evaluation results. Our result demonstrate that with Top-N recommendation and large search evaluation data, most tests would have a 100% chance of finding statistically significant results. Therefore, the effect size should be used to determine practical or scientific significance.
Patterns of gender-specializing query reformulation
Apr 25, 2023Users of search systems often reformulate their queries by adding query terms to reflect their evolving information need or to more precisely express their information need when the system fails to surface relevant content. Analyzing these query reformulations can inform us about both system and user behavior. In this work, we study a special category of query reformulations that involve specifying demographic group attributes, such as gender, as part of the reformulated query (e.g., "olympic 2021 soccer results" to "olympic 2021 women's soccer results"). There are many ways a query, the search results, and a demographic attribute such as gender may relate, leading us to hypothesize different causes for these reformulation patterns, such as under-representation on the original result page or based on the linguistic theory of markedness. This paper reports on an observational study of gender-specializing query reformulations -- their contexts and effects -- as a lens on the relationship between system results and gender, based on large-scale search log data from Bing. We find that these reformulations sometimes correct for and other times reinforce gender representation on the original result page, but typically yield better access to the ultimately-selected results. The prevalence of these reformulations -- and which gender they skew towards -- differ by topical context. However, we do not find evidence that either group under-representation or markedness alone adequately explains these reformulations. We hope that future research will use such reformulations as a probe for deeper investigation into gender (and other demographic) representation on the search result page.
Overview of the TREC 2021 Fair Ranking Track
Feb 21, 2023The TREC Fair Ranking Track aims to provide a platform for participants to develop and evaluate novel retrieval algorithms that can provide a fair exposure to a mixture of demographics or attributes, such as ethnicity, that are represented by relevant documents in response to a search query. For example, particular demographics or attributes can be represented by the documents' topical content or authors. The 2021 Fair Ranking Track adopted a resource allocation task. The task focused on supporting Wikipedia editors who are looking to improve the encyclopedia's coverage of topics under the purview of a WikiProject. WikiProject coordinators and/or Wikipedia editors search for Wikipedia documents that are in need of editing to improve the quality of the article. The 2021 Fair Ranking track aimed to ensure that documents that are about, or somehow represent, certain protected characteristics receive a fair exposure to the Wikipedia editors, so that the documents have an fair opportunity of being improved and, therefore, be well-represented in Wikipedia. The under-representation of particular protected characteristics in Wikipedia can result in systematic biases that can have a negative human, social, and economic impact, particularly for disadvantaged or protected societal groups.
Overview of the TREC 2022 Fair Ranking Track
Feb 11, 2023The TREC Fair Ranking Track aims to provide a platform for participants to develop and evaluate novel retrieval algorithms that can provide a fair exposure to a mixture of demographics or attributes, such as ethnicity, that are represented by relevant documents in response to a search query. For example, particular demographics or attributes can be represented by the documents topical content or authors. The 2022 Fair Ranking Track adopted a resource allocation task. The task focused on supporting Wikipedia editors who are looking to improve the encyclopedia's coverage of topics under the purview of a WikiProject. WikiProject coordinators and/or Wikipedia editors search for Wikipedia documents that are in need of editing to improve the quality of the article. The 2022 Fair Ranking track aimed to ensure that documents that are about, or somehow represent, certain protected characteristics receive a fair exposure to the Wikipedia editors, so that the documents have an fair opportunity of being improved and, therefore, be well-represented in Wikipedia. The under-representation of particular protected characteristics in Wikipedia can result in systematic biases that can have a negative human, social, and economic impact, particularly for disadvantaged or protected societal groups.