 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCandidate Set Sampling for Evaluating Top-N Recommendation
Sep 21, 2023The strategy for selecting candidate sets -- the set of items that the recommendation system is expected to rank for each user -- is an important decision in carrying out an offline top-$N$ recommender system evaluation. The set of candidates is composed of the union of the user's test items and an arbitrary number of non-relevant items that we refer to as decoys. Previous studies have aimed to understand the effect of different candidate set sizes and selection strategies on evaluation. In this paper, we extend this knowledge by studying the specific interaction of candidate set selection strategies with popularity bias, and use simulation to assess whether sampled candidate sets result in metric estimates that are less biased with respect to the true metric values under complete data that is typically unavailable in ordinary experiments.
Inference at Scale Significance Testing for Large Search and Recommendation Experiments
May 12, 2023
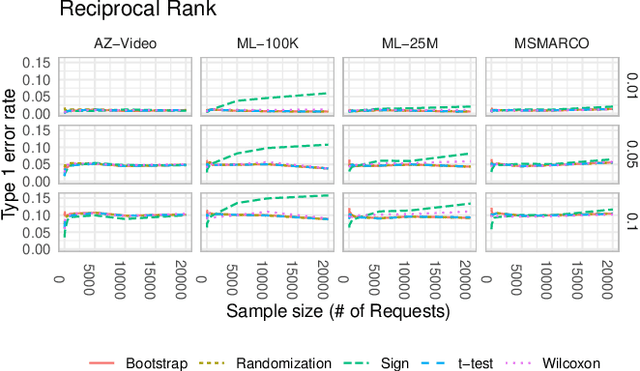
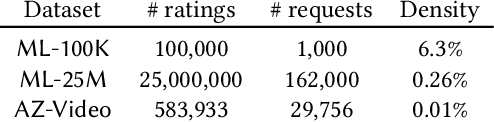
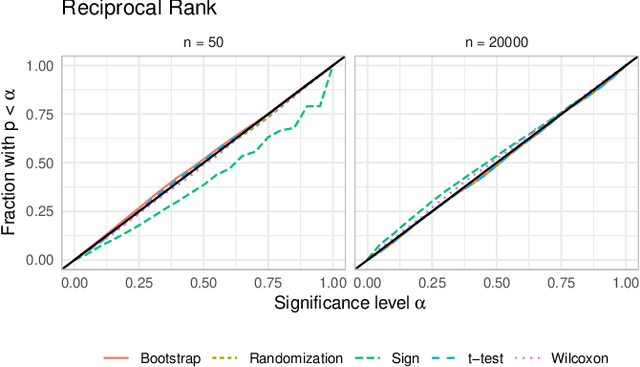
A number of information retrieval studies have been done to assess which statistical techniques are appropriate for comparing systems. However, these studies are focused on TREC-style experiments, which typically have fewer than 100 topics. There is no similar line of work for large search and recommendation experiments; such studies typically have thousands of topics or users and much sparser relevance judgements, so it is not clear if recommendations for analyzing traditional TREC experiments apply to these settings. In this paper, we empirically study the behavior of significance tests with large search and recommendation evaluation data. Our results show that the Wilcoxon and Sign tests show significantly higher Type-1 error rates for large sample sizes than the bootstrap, randomization and t-tests, which were more consistent with the expected error rate. While the statistical tests displayed differences in their power for smaller sample sizes, they showed no difference in their power for large sample sizes. We recommend the sign and Wilcoxon tests should not be used to analyze large scale evaluation results. Our result demonstrate that with Top-N recommendation and large search evaluation data, most tests would have a 100% chance of finding statistically significant results. Therefore, the effect size should be used to determine practical or scientific significance.
Statistical Inference: The Missing Piece of RecSys Experiment Reliability Discourse
Sep 14, 2021
This paper calls attention to the missing component of the recommender system evaluation process: Statistical Inference. There is active research in several components of the recommender system evaluation process: selecting baselines, standardizing benchmarks, and target item sampling. However, there has not yet been significant work on the role and use of statistical inference for analyzing recommender system evaluation results. In this paper, we argue that the use of statistical inference is a key component of the evaluation process that has not been given sufficient attention. We support this argument with systematic review of recent RecSys papers to understand how statistical inference is currently being used, along with a brief survey of studies that have been done on the use of statistical inference in the information retrieval community. We present several challenges that exist for inference in recommendation experiment which buttresses the need for empirical studies to aid with appropriately selecting and applying statistical inference techniques.