 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Eyes on the Ranker: Participatory Auditing to Surface Blind Spots in Ranked Search Results
Apr 10, 2026Search engines that present users with a ranked list of search results are a fundamental technology for providing public access to information. Evaluations of such systems are typically conducted by domain experts and focus on model-centric metrics, relevance judgments, or output-based analyses, rather than on how accountability, harm, or trust are experienced by users. This paper argues that participatory auditing is essential for revealing users' causal and contextual understandings of how ranked search results produce impacts, particularly as ranking models appear increasingly convincing and sophisticated in their semantic interpretation of user queries. We report on three participatory auditing workshops (n=21) in which participants engaged with a custom search interface across four tasks, comparing a lexical ranker (BM25) and a neural semantic reranker (MonoT5), exploring varying levels of transparency and user controls, and examining an intentionally adversarially manipulated ranking. Reflexive activities prompted participants to articulate causal narratives linking search system properties to broader impacts. Synthesising the findings, we contribute a taxonomy of user-perceived impacts of ranked search results, spanning epistemic, representational, infrastructural, and downstream social impacts. However, interactions with the neural model revealed limits to participatory auditing itself: perceived system competence and accumulated trust reduced critical scrutiny during the workshop, allowing manipulations to go undetected. Participants expressed desire for visibility into the full search pipeline and recourse mechanisms. Together, these findings show how participatory auditing can surface user perceived impacts and accountability gaps that remain unseen when relying on conventional audits, while revealing where participatory auditing may encounter limitations.
Who Benefits from RAG? The Role of Exposure, Utility and Attribution Bias
Mar 25, 2026Large Language Models (LLMs) enhanced with Retrieval-Augmented Generation (RAG) have achieved substantial improvements in accuracy by grounding their responses in external documents that are relevant to the user's query. However, relatively little work has investigated the impact of RAG in terms of fairness. Particularly, it is not yet known if queries that are associated with certain groups within a fairness category systematically receive higher accuracy, or accuracy improvements in RAG systems compared to LLM-only, a phenomenon we refer to as query group fairness. In this work, we conduct extensive experiments to investigate the impact of three key factors on query group fairness in RAG, namely: Group exposure, i.e., the proportion of documents from each group appearing in the retrieved set, determined by the retriever; Group utility, i.e., the degree to which documents from each group contribute to improving answer accuracy, capturing retriever-generator interactions; and Group attribution, i.e., the extent to which the generator relies on documents from each group when producing responses. We examine group-level average accuracy and accuracy improvements disparities across four fairness categories using three datasets derived from the TREC 2022 Fair Ranking Track for two tasks: article generation and title generation. Our findings show that RAG systems suffer from the query group fairness problem and amplify disparities in terms of average accuracy across queries from different groups, compared to an LLM-only setting. Moreover, group utility, exposure, and attribution can exhibit strong positive or negative correlations with average accuracy or accuracy improvements of queries from that group, highlighting their important role in fair RAG. Our data and code are publicly available from Github.
Temporal Fact Conflicts in LLMs: Reproducibility Insights from Unifying DYNAMICQA and MULAN
Mar 16, 2026Large Language Models (LLMs) often struggle with temporal fact conflicts due to outdated or evolving information in their training data. Two recent studies with accompanying datasets report opposite conclusions on whether external context can effectively resolve such conflicts. DYNAMICQA evaluates how effective external context is in shifting the model's output distribution, finding that temporal facts are more resistant to change. In contrast, MULAN examines how often external context changes memorised facts, concluding that temporal facts are easier to update. In this reproducibility paper, we first reproduce experiments from both benchmarks. We then reproduce the experiments of each study on the dataset of the other to investigate the source of their disagreement. To enable direct comparison of findings, we standardise both datasets to align with the evaluation settings of each study. Importantly, using an LLM, we synthetically generate realistic natural language contexts to replace MULAN's programmatically constructed statements when reproducing the findings of DYNAMICQA. Our analysis reveals strong dataset dependence: MULAN's findings generalise under both methodological frameworks, whereas applying MULAN's evaluation to DYNAMICQA yields mixed outcomes. Finally, while the original studies only considered 7B LLMs, we reproduce these experiments across LLMs of varying sizes, revealing how model size influences the encoding and updating of temporal facts. Our results highlight how dataset design, evaluation metrics, and model size shape LLM behaviour in the presence of temporal knowledge conflicts.
Document Similarity Enhanced IPS Estimation for Unbiased Learning to Rank
Jul 10, 2025Learning to Rank (LTR) models learn from historical user interactions, such as user clicks. However, there is an inherent bias in the clicks of users due to position bias, i.e., users are more likely to click highly-ranked documents than low-ranked documents. To address this bias when training LTR models, many approaches from the literature re-weight the users' click data using Inverse Propensity Scoring (IPS). IPS re-weights the user's clicks proportionately to the position in the historical ranking that a document was placed when it was clicked since low-ranked documents are less likely to be seen by a user. In this paper, we argue that low-ranked documents that are similar to highly-ranked relevant documents are also likely to be relevant. Moreover, accounting for the similarity of low-ranked documents to highly ranked relevant documents when calculating IPS can more effectively mitigate the effects of position bias. Therefore, we propose an extension to IPS, called IPSsim, that takes into consideration the similarity of documents when estimating IPS. We evaluate our IPSsim estimator using two large publicly available LTR datasets under a number of simulated user click settings, and with different numbers of training clicks. Our experiments show that our IPSsim estimator is more effective than the existing IPS estimators for learning an unbiased LTR model, particularly in top-n settings when n >= 30. For example, when n = 50, our IPSsim estimator achieves a statistically significant ~3% improvement (p < 0.05) in terms of NDCG compared to the Doubly Robust estimator from the literature.
Measuring Hypothesis Testing Errors in the Evaluation of Retrieval Systems
Jul 10, 2025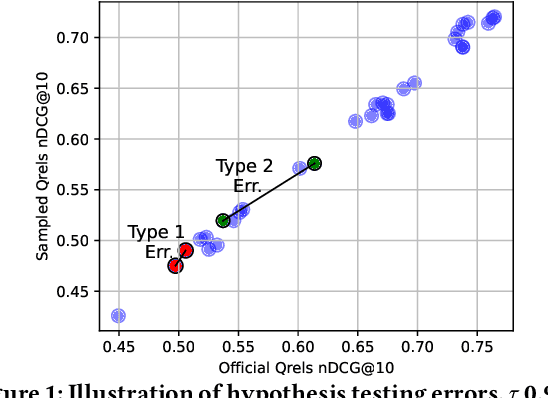

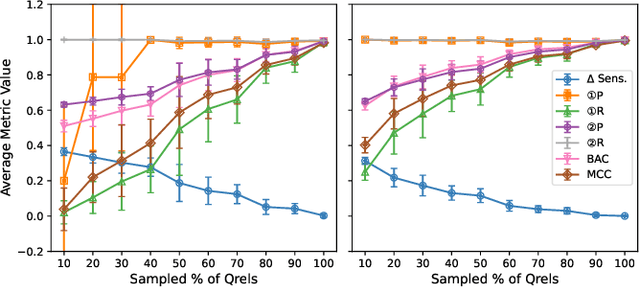

The evaluation of Information Retrieval (IR) systems typically uses query-document pairs with corresponding human-labelled relevance assessments (qrels). These qrels are used to determine if one system is better than another based on average retrieval performance. Acquiring large volumes of human relevance assessments is expensive. Therefore, more efficient relevance assessment approaches have been proposed, necessitating comparisons between qrels to ascertain their efficacy. Discriminative power, i.e. the ability to correctly identify significant differences between systems, is important for drawing accurate conclusions on the robustness of qrels. Previous work has measured the proportion of pairs of systems that are identified as significantly different and has quantified Type I statistical errors. Type I errors lead to incorrect conclusions due to false positive significance tests. We argue that also identifying Type II errors (false negatives) is important as they lead science in the wrong direction. We quantify Type II errors and propose that balanced classification metrics, such as balanced accuracy, can be used to portray the discriminative power of qrels. We perform experiments using qrels generated using alternative relevance assessment methods to investigate measuring hypothesis testing errors in IR evaluation. We find that additional insights into the discriminative power of qrels can be gained by quantifying Type II errors, and that balanced classification metrics can be used to give an overall summary of discriminative power in one, easily comparable, number.
Quantifying Query Fairness Under Unawareness
Jun 04, 2025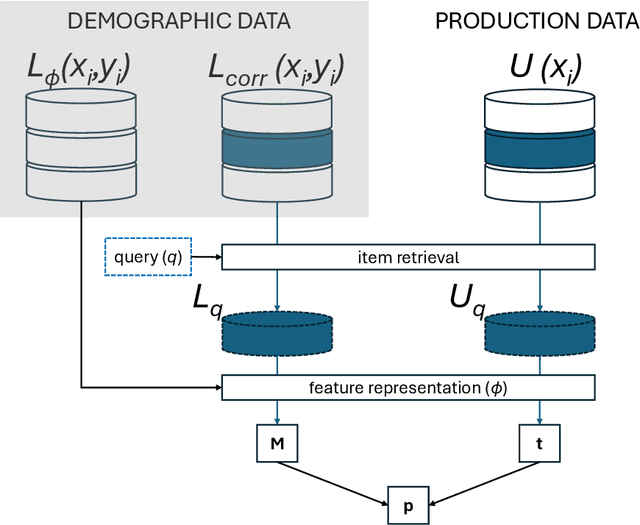

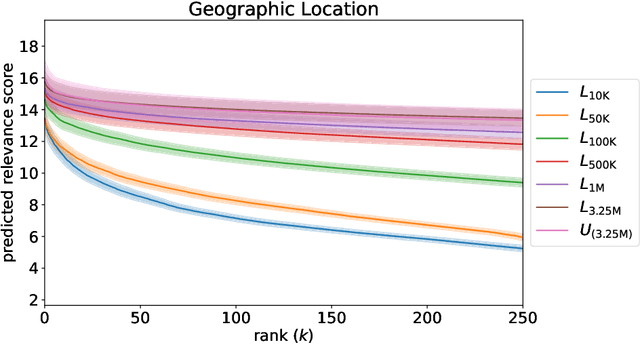

Traditional ranking algorithms are designed to retrieve the most relevant items for a user's query, but they often inherit biases from data that can unfairly disadvantage vulnerable groups. Fairness in information access systems (IAS) is typically assessed by comparing the distribution of groups in a ranking to a target distribution, such as the overall group distribution in the dataset. These fairness metrics depend on knowing the true group labels for each item. However, when groups are defined by demographic or sensitive attributes, these labels are often unknown, leading to a setting known as "fairness under unawareness". To address this, group membership can be inferred using machine-learned classifiers, and group prevalence is estimated by counting the predicted labels. Unfortunately, such an estimation is known to be unreliable under dataset shift, compromising the accuracy of fairness evaluations. In this paper, we introduce a robust fairness estimator based on quantification that effectively handles multiple sensitive attributes beyond binary classifications. Our method outperforms existing baselines across various sensitive attributes and, to the best of our knowledge, is the first to establish a reliable protocol for measuring fairness under unawareness across multiple queries and groups.
Zero-shot and Few-shot Generation Strategies for Artificial Clinical Records
Mar 14, 2024


The challenge of accessing historical patient data for clinical research, while adhering to privacy regulations, is a significant obstacle in medical science. An innovative approach to circumvent this issue involves utilising synthetic medical records that mirror real patient data without compromising individual privacy. The creation of these synthetic datasets, particularly without using actual patient data to train Large Language Models (LLMs), presents a novel solution as gaining access to sensitive patient information to train models is also a challenge. This study assesses the capability of the Llama 2 LLM to create synthetic medical records that accurately reflect real patient information, employing zero-shot and few-shot prompting strategies for comparison against fine-tuned methodologies that do require sensitive patient data during training. We focus on generating synthetic narratives for the History of Present Illness section, utilising data from the MIMIC-IV dataset for comparison. In this work introduce a novel prompting technique that leverages a chain-of-thought approach, enhancing the model's ability to generate more accurate and contextually relevant medical narratives without prior fine-tuning. Our findings suggest that this chain-of-thought prompted approach allows the zero-shot model to achieve results on par with those of fine-tuned models, based on Rouge metrics evaluation.
Query Exposure Prediction for Groups of Documents in Rankings
Jan 24, 2024The main objective of an Information Retrieval system is to provide a user with the most relevant documents to the user's query. To do this, modern IR systems typically deploy a re-ranking pipeline in which a set of documents is retrieved by a lightweight first-stage retrieval process and then re-ranked by a more effective but expensive model. However, the success of a re-ranking pipeline is heavily dependent on the performance of the first stage retrieval, since new documents are not usually identified during the re-ranking stage. Moreover, this can impact the amount of exposure that a particular group of documents, such as documents from a particular demographic group, can receive in the final ranking. For example, the fair allocation of exposure becomes more challenging or impossible if the first stage retrieval returns too few documents from certain groups, since the number of group documents in the ranking affects the exposure more than the documents' positions. With this in mind, it is beneficial to predict the amount of exposure that a group of documents is likely to receive in the results of the first stage retrieval process, in order to ensure that there are a sufficient number of documents included from each of the groups. In this paper, we introduce the novel task of query exposure prediction (QEP). Specifically, we propose the first approach for predicting the distribution of exposure that groups of documents will receive for a given query. Our new approach, called GEP, uses lexical information from individual groups of documents to estimate the exposure the groups will receive in a ranking. Our experiments on the TREC 2021 and 2022 Fair Ranking Track test collections show that our proposed GEP approach results in exposure predictions that are up to 40 % more accurate than the predictions of adapted existing query performance prediction and resource allocation approaches.
SARA: A Collection of Sensitivity-Aware Relevance Assessments
Jan 10, 2024Large archival collections, such as email or government documents, must be manually reviewed to identify any sensitive information before the collection can be released publicly. Sensitivity classification has received a lot of attention in the literature. However, more recently, there has been increasing interest in developing sensitivity-aware search engines that can provide users with relevant search results, while ensuring that no sensitive documents are returned to the user. Sensitivity-aware search would mitigate the need for a manual sensitivity review prior to collections being made available publicly. To develop such systems, there is a need for test collections that contain relevance assessments for a set of information needs as well as ground-truth labels for a variety of sensitivity categories. The well-known Enron email collection contains a classification ground-truth that can be used to represent sensitive information, e.g., the Purely Personal and Personal but in Professional Context categories can be used to represent sensitive personal information. However, the existing Enron collection does not contain a set of information needs and relevance assessments. In this work, we present a collection of fifty information needs (topics) with crowdsourced query formulations (3 per topic) and relevance assessments (11,471 in total) for the Enron collection (mean number of relevant documents per topic = 11, variance = 34.7). The developed information needs, queries and relevance judgements are available on GitHub and will be available along with the existing Enron collection through the popular ir_datasets library. Our proposed collection results in the first freely available test collection for developing sensitivity-aware search systems.
Overview of the TREC 2021 Fair Ranking Track
Feb 21, 2023The TREC Fair Ranking Track aims to provide a platform for participants to develop and evaluate novel retrieval algorithms that can provide a fair exposure to a mixture of demographics or attributes, such as ethnicity, that are represented by relevant documents in response to a search query. For example, particular demographics or attributes can be represented by the documents' topical content or authors. The 2021 Fair Ranking Track adopted a resource allocation task. The task focused on supporting Wikipedia editors who are looking to improve the encyclopedia's coverage of topics under the purview of a WikiProject. WikiProject coordinators and/or Wikipedia editors search for Wikipedia documents that are in need of editing to improve the quality of the article. The 2021 Fair Ranking track aimed to ensure that documents that are about, or somehow represent, certain protected characteristics receive a fair exposure to the Wikipedia editors, so that the documents have an fair opportunity of being improved and, therefore, be well-represented in Wikipedia. The under-representation of particular protected characteristics in Wikipedia can result in systematic biases that can have a negative human, social, and economic impact, particularly for disadvantaged or protected societal groups.