 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Query Fairness Under Unawareness
Jun 04, 2025


Traditional ranking algorithms are designed to retrieve the most relevant items for a user's query, but they often inherit biases from data that can unfairly disadvantage vulnerable groups. Fairness in information access systems (IAS) is typically assessed by comparing the distribution of groups in a ranking to a target distribution, such as the overall group distribution in the dataset. These fairness metrics depend on knowing the true group labels for each item. However, when groups are defined by demographic or sensitive attributes, these labels are often unknown, leading to a setting known as "fairness under unawareness". To address this, group membership can be inferred using machine-learned classifiers, and group prevalence is estimated by counting the predicted labels. Unfortunately, such an estimation is known to be unreliable under dataset shift, compromising the accuracy of fairness evaluations. In this paper, we introduce a robust fairness estimator based on quantification that effectively handles multiple sensitive attributes beyond binary classifications. Our method outperforms existing baselines across various sensitive attributes and, to the best of our knowledge, is the first to establish a reliable protocol for measuring fairness under unawareness across multiple queries and groups.
Generative Relevance Feedback and Convergence of Adaptive Re-Ranking: University of Glasgow Terrier Team at TREC DL 2023
May 02, 2024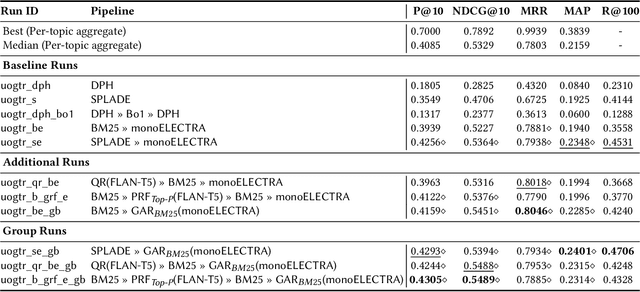
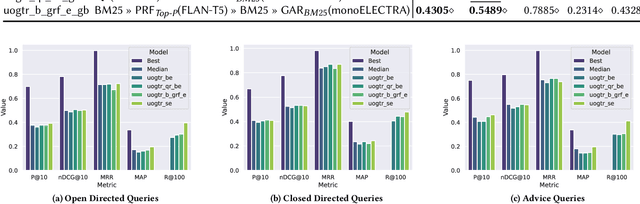
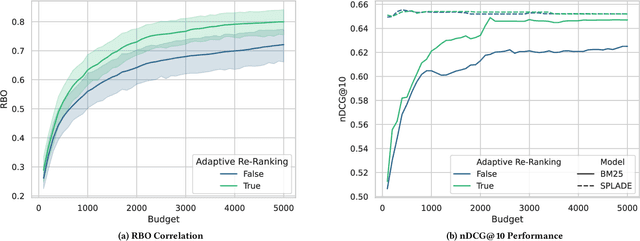
This paper describes our participation in the TREC 2023 Deep Learning Track. We submitted runs that apply generative relevance feedback from a large language model in both a zero-shot and pseudo-relevance feedback setting over two sparse retrieval approaches, namely BM25 and SPLADE. We couple this first stage with adaptive re-ranking over a BM25 corpus graph scored using a monoELECTRA cross-encoder. We investigate the efficacy of these generative approaches for different query types in first-stage retrieval. In re-ranking, we investigate operating points of adaptive re-ranking with different first stages to find the point in graph traversal where the first stage no longer has an effect on the performance of the overall retrieval pipeline. We find some performance gains from the application of generative query reformulation. However, our strongest run in terms of P@10 and nDCG@10 applied both adaptive re-ranking and generative pseudo-relevance feedback, namely uogtr_b_grf_e_gb.
Query Exposure Prediction for Groups of Documents in Rankings
Jan 24, 2024The main objective of an Information Retrieval system is to provide a user with the most relevant documents to the user's query. To do this, modern IR systems typically deploy a re-ranking pipeline in which a set of documents is retrieved by a lightweight first-stage retrieval process and then re-ranked by a more effective but expensive model. However, the success of a re-ranking pipeline is heavily dependent on the performance of the first stage retrieval, since new documents are not usually identified during the re-ranking stage. Moreover, this can impact the amount of exposure that a particular group of documents, such as documents from a particular demographic group, can receive in the final ranking. For example, the fair allocation of exposure becomes more challenging or impossible if the first stage retrieval returns too few documents from certain groups, since the number of group documents in the ranking affects the exposure more than the documents' positions. With this in mind, it is beneficial to predict the amount of exposure that a group of documents is likely to receive in the results of the first stage retrieval process, in order to ensure that there are a sufficient number of documents included from each of the groups. In this paper, we introduce the novel task of query exposure prediction (QEP). Specifically, we propose the first approach for predicting the distribution of exposure that groups of documents will receive for a given query. Our new approach, called GEP, uses lexical information from individual groups of documents to estimate the exposure the groups will receive in a ranking. Our experiments on the TREC 2021 and 2022 Fair Ranking Track test collections show that our proposed GEP approach results in exposure predictions that are up to 40 % more accurate than the predictions of adapted existing query performance prediction and resource allocation approaches.