 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Begins with Data: The FairGround Corpus for Robust and Reproducible Research on Algorithmic Fairness
Oct 25, 2025As machine learning (ML) systems are increasingly adopted in high-stakes decision-making domains, ensuring fairness in their outputs has become a central challenge. At the core of fair ML research are the datasets used to investigate bias and develop mitigation strategies. Yet, much of the existing work relies on a narrow selection of datasets--often arbitrarily chosen, inconsistently processed, and lacking in diversity--undermining the generalizability and reproducibility of results. To address these limitations, we present FairGround: a unified framework, data corpus, and Python package aimed at advancing reproducible research and critical data studies in fair ML classification. FairGround currently comprises 44 tabular datasets, each annotated with rich fairness-relevant metadata. Our accompanying Python package standardizes dataset loading, preprocessing, transformation, and splitting, streamlining experimental workflows. By providing a diverse and well-documented dataset corpus along with robust tooling, FairGround enables the development of fairer, more reliable, and more reproducible ML models. All resources are publicly available to support open and collaborative research.
Reinforcement Learning for Durable Algorithmic Recourse
Sep 26, 2025Algorithmic recourse seeks to provide individuals with actionable recommendations that increase their chances of receiving favorable outcomes from automated decision systems (e.g., loan approvals). While prior research has emphasized robustness to model updates, considerably less attention has been given to the temporal dynamics of recourse--particularly in competitive, resource-constrained settings where recommendations shape future applicant pools. In this work, we present a novel time-aware framework for algorithmic recourse, explicitly modeling how candidate populations adapt in response to recommendations. Additionally, we introduce a novel reinforcement learning (RL)-based recourse algorithm that captures the evolving dynamics of the environment to generate recommendations that are both feasible and valid. We design our recommendations to be durable, supporting validity over a predefined time horizon T. This durability allows individuals to confidently reapply after taking time to implement the suggested changes. Through extensive experiments in complex simulation environments, we show that our approach substantially outperforms existing baselines, offering a superior balance between feasibility and long-term validity. Together, these results underscore the importance of incorporating temporal and behavioral dynamics into the design of practical recourse systems.
Quantifying Query Fairness Under Unawareness
Jun 04, 2025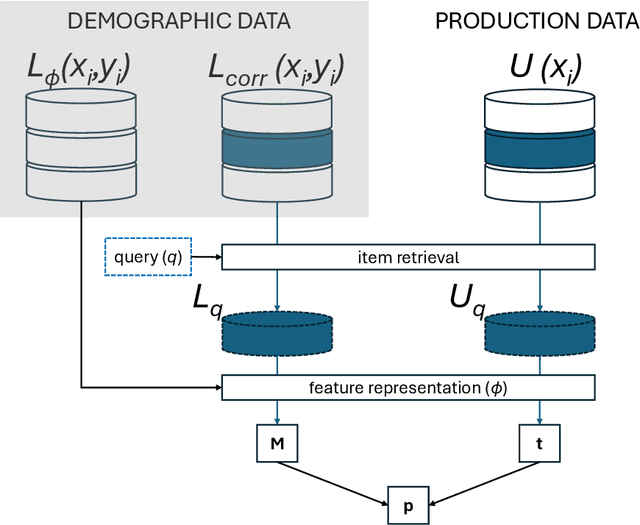

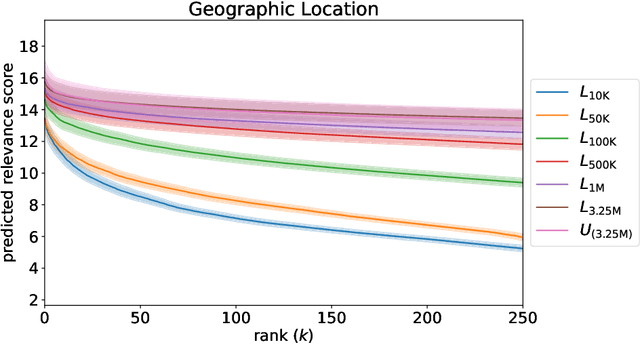

Traditional ranking algorithms are designed to retrieve the most relevant items for a user's query, but they often inherit biases from data that can unfairly disadvantage vulnerable groups. Fairness in information access systems (IAS) is typically assessed by comparing the distribution of groups in a ranking to a target distribution, such as the overall group distribution in the dataset. These fairness metrics depend on knowing the true group labels for each item. However, when groups are defined by demographic or sensitive attributes, these labels are often unknown, leading to a setting known as "fairness under unawareness". To address this, group membership can be inferred using machine-learned classifiers, and group prevalence is estimated by counting the predicted labels. Unfortunately, such an estimation is known to be unreliable under dataset shift, compromising the accuracy of fairness evaluations. In this paper, we introduce a robust fairness estimator based on quantification that effectively handles multiple sensitive attributes beyond binary classifications. Our method outperforms existing baselines across various sensitive attributes and, to the best of our knowledge, is the first to establish a reliable protocol for measuring fairness under unawareness across multiple queries and groups.
Testing software for non-discrimination: an updated and extended audit in the Italian car insurance domain
Feb 10, 2025Context. As software systems become more integrated into society's infrastructure, the responsibility of software professionals to ensure compliance with various non-functional requirements increases. These requirements include security, safety, privacy, and, increasingly, non-discrimination. Motivation. Fairness in pricing algorithms grants equitable access to basic services without discriminating on the basis of protected attributes. Method. We replicate a previous empirical study that used black box testing to audit pricing algorithms used by Italian car insurance companies, accessible through a popular online system. With respect to the previous study, we enlarged the number of tests and the number of demographic variables under analysis. Results. Our work confirms and extends previous findings, highlighting the problematic permanence of discrimination across time: demographic variables significantly impact pricing to this day, with birthplace remaining the main discriminatory factor against individuals not born in Italian cities. We also found that driver profiles can determine the number of quotes available to the user, denying equal opportunities to all. Conclusion. The study underscores the importance of testing for non-discrimination in software systems that affect people's everyday lives. Performing algorithmic audits over time makes it possible to evaluate the evolution of such algorithms. It also demonstrates the role that empirical software engineering can play in making software systems more accountable.
Lazy Data Practices Harm Fairness Research
Apr 26, 2024Data practices shape research and practice on fairness in machine learning (fair ML). Critical data studies offer important reflections and critiques for the responsible advancement of the field by highlighting shortcomings and proposing recommendations for improvement. In this work, we present a comprehensive analysis of fair ML datasets, demonstrating how unreflective yet common practices hinder the reach and reliability of algorithmic fairness findings. We systematically study protected information encoded in tabular datasets and their usage in 280 experiments across 142 publications. Our analyses identify three main areas of concern: (1) a \textbf{lack of representation for certain protected attributes} in both data and evaluations; (2) the widespread \textbf{exclusion of minorities} during data preprocessing; and (3) \textbf{opaque data processing} threatening the generalization of fairness research. By conducting exemplary analyses on the utilization of prominent datasets, we demonstrate how unreflective data decisions disproportionately affect minority groups, fairness metrics, and resultant model comparisons. Additionally, we identify supplementary factors such as limitations in publicly available data, privacy considerations, and a general lack of awareness, which exacerbate these challenges. To address these issues, we propose a set of recommendations for data usage in fairness research centered on transparency and responsible inclusion. This study underscores the need for a critical reevaluation of data practices in fair ML and offers directions to improve both the sourcing and usage of datasets.
Multi-Label Continual Learning for the Medical Domain: A Novel Benchmark
Apr 11, 2024



Multi-label image classification in dynamic environments is a problem that poses significant challenges. Previous studies have primarily focused on scenarios such as Domain Incremental Learning and Class Incremental Learning, which do not fully capture the complexity of real-world applications. In this paper, we study the problem of classification of medical imaging in the scenario termed New Instances and New Classes, which combines the challenges of both new class arrivals and domain shifts in a single framework. Unlike traditional scenarios, it reflects the realistic nature of CL in domains such as medical imaging, where updates may introduce both new classes and changes in domain characteristics. To address the unique challenges posed by this complex scenario, we introduce a novel approach called Pseudo-Label Replay. This method aims to mitigate forgetting while adapting to new classes and domain shifts by combining the advantages of the Replay and Pseudo-Label methods and solving their limitations in the proposed scenario. We evaluate our proposed approach on a challenging benchmark consisting of two datasets, seven tasks, and nineteen classes, modeling a realistic Continual Learning scenario. Our experimental findings demonstrate the effectiveness of Pseudo-Label Replay in addressing the challenges posed by the complex scenario proposed. Our method surpasses existing approaches, exhibiting superior performance while showing minimal forgetting.
A Fairness-Oriented Reinforcement Learning Approach for the Operation and Control of Shared Micromobility Services
Mar 23, 2024As Machine Learning systems become increasingly popular across diverse application domains, including those with direct human implications, the imperative of equity and algorithmic fairness has risen to prominence in the Artificial Intelligence community. On the other hand, in the context of Shared Micromobility Systems, the exploration of fairness-oriented approaches remains limited. Addressing this gap, we introduce a pioneering investigation into the balance between performance optimization and algorithmic fairness in the operation and control of Shared Micromobility Services. Our study leverages the Q-Learning algorithm in Reinforcement Learning, benefiting from its convergence guarantees to ensure the robustness of our proposed approach. Notably, our methodology stands out for its ability to achieve equitable outcomes, as measured by the Gini index, across different station categories--central, peripheral, and remote. Through strategic rebalancing of vehicle distribution, our approach aims to maximize operator performance while simultaneously upholding fairness principles for users. In addition to theoretical insights, we substantiate our findings with a case study or simulation based on synthetic data, validating the efficacy of our approach. This paper underscores the critical importance of fairness considerations in shaping control strategies for Shared Micromobility Services, offering a pragmatic framework for enhancing equity in urban transportation systems.
Fairness and Bias in Algorithmic Hiring
Sep 25, 2023

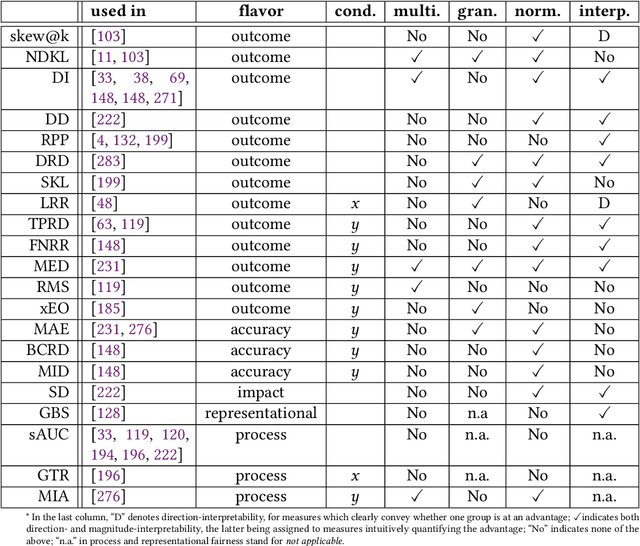

Employers are adopting algorithmic hiring technology throughout the recruitment pipeline. Algorithmic fairness is especially applicable in this domain due to its high stakes and structural inequalities. Unfortunately, most work in this space provides partial treatment, often constrained by two competing narratives, optimistically focused on replacing biased recruiter decisions or pessimistically pointing to the automation of discrimination. Whether, and more importantly what types of, algorithmic hiring can be less biased and more beneficial to society than low-tech alternatives currently remains unanswered, to the detriment of trustworthiness. This multidisciplinary survey caters to practitioners and researchers with a balanced and integrated coverage of systems, biases, measures, mitigation strategies, datasets, and legal aspects of algorithmic hiring and fairness. Our work supports a contextualized understanding and governance of this technology by highlighting current opportunities and limitations, providing recommendations for future work to ensure shared benefits for all stakeholders.
Artificial Intelligence across Europe: A Study on Awareness, Attitude and Trust
Aug 19, 2023



This paper presents the results of an extensive study investigating the opinions on Artificial Intelligence (AI) of a sample of 4,006 European citizens from eight distinct countries (France, Germany, Italy, Netherlands, Poland, Romania, Spain, and Sweden). The aim of the study is to gain a better understanding of people's views and perceptions within the European context, which is already marked by important policy actions and regulatory processes. To survey the perceptions of the citizens of Europe we design and validate a new questionnaire (PAICE) structured around three dimensions: people's awareness, attitude, and trust. We observe that while awareness is characterized by a low level of self-assessed competency, the attitude toward AI is very positive for more than half of the population. Reflecting upon the collected results, we highlight implicit contradictions and identify trends that may interfere with the creation of an ecosystem of trust and the development of inclusive AI policies. The introduction of rules that ensure legal and ethical standards, along with the activity of high-level educational entities, and the promotion of AI literacy are identified as key factors in supporting a trustworthy AI ecosystem. We make some recommendations for AI governance focused on the European context and conclude with suggestions for future work.
Measuring Fairness under Unawareness via Quantification
Sep 17, 2021
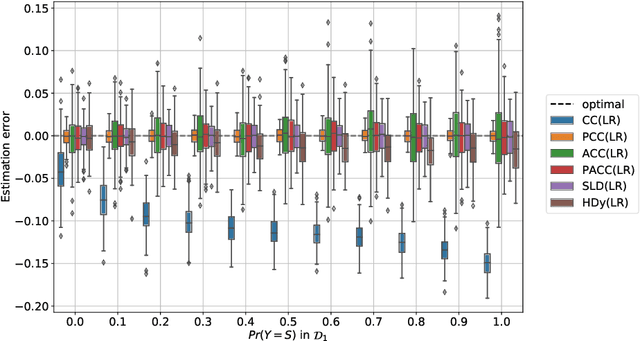

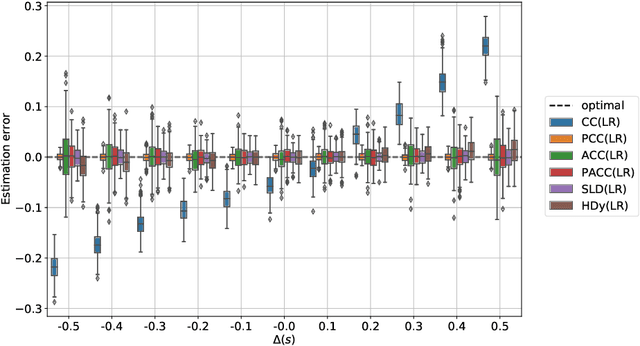
Models trained by means of supervised learning are increasingly deployed in high-stakes domains, and, when their predictions inform decisions about people, they inevitably impact (positively or negatively) on their lives. As a consequence, those in charge of developing these models must carefully evaluate their impact on different groups of people and ensure that sensitive demographic attributes, such as race or sex, do not result in unfair treatment for members of specific groups. For doing this, awareness of demographic attributes on the part of those evaluating model impacts is fundamental. Unfortunately, the collection of these attributes is often in conflict with industry practices and legislation on data minimization and privacy. For this reason, it may be hard to measure the group fairness of trained models, even from within the companies developing them. In this work, we tackle the problem of measuring group fairness under unawareness of sensitive attributes, by using techniques from quantification, a supervised learning task concerned with directly providing group-level prevalence estimates (rather than individual-level class labels). We identify five important factors that complicate the estimation of fairness under unawareness and formalize them into five different experimental protocols under which we assess the effectiveness of different estimators of group fairness. We also consider the problem of potential model misuse to infer sensitive attributes at an individual level, and demonstrate that quantification approaches are suitable for decoupling the (desirable) objective of measuring group fairness from the (undesirable) objective of inferring sensitive attributes of individuals.