 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence across Europe: A Study on Awareness, Attitude and Trust
Aug 19, 2023



This paper presents the results of an extensive study investigating the opinions on Artificial Intelligence (AI) of a sample of 4,006 European citizens from eight distinct countries (France, Germany, Italy, Netherlands, Poland, Romania, Spain, and Sweden). The aim of the study is to gain a better understanding of people's views and perceptions within the European context, which is already marked by important policy actions and regulatory processes. To survey the perceptions of the citizens of Europe we design and validate a new questionnaire (PAICE) structured around three dimensions: people's awareness, attitude, and trust. We observe that while awareness is characterized by a low level of self-assessed competency, the attitude toward AI is very positive for more than half of the population. Reflecting upon the collected results, we highlight implicit contradictions and identify trends that may interfere with the creation of an ecosystem of trust and the development of inclusive AI policies. The introduction of rules that ensure legal and ethical standards, along with the activity of high-level educational entities, and the promotion of AI literacy are identified as key factors in supporting a trustworthy AI ecosystem. We make some recommendations for AI governance focused on the European context and conclude with suggestions for future work.
An Algebraic Framework for Stock & Flow Diagrams and Dynamical Systems Using Category Theory
Nov 01, 2022



Mathematical modeling of infectious disease at scale is important, but challenging. Some of these difficulties can be alleviated by an approach that takes diagrams seriously as mathematical formalisms in their own right. Stock & flow diagrams are widely used as broadly accessible building blocks for infectious disease modeling. In this chapter, rather than focusing on the underlying mathematics, we informally use communicable disease examples created by the implemented software of StockFlow.jl to explain the basics, characteristics, and benefits of the categorical framework. We first characterize categorical stock & flow diagrams, and note the clear separation between the syntax of stock & flow diagrams and their semantics, demonstrating three examples of semantics already implemented in the software: ODEs, causal loop diagrams, and system structure diagrams. We then establish composition and stratification frameworks and examples for stock & flow diagrams. Applying category theory, these frameworks can build large diagrams from smaller ones in a modular fashion. Finally, we introduce the open-source ModelCollab software for diagram-centric real-time collaborative modeling. Using the graphical user interface, this web-based software allows the user to undertake the types of categorically-rooted operations discussed above, but without any knowledge of their categorical foundations.
Compressive Features in Offline Reinforcement Learning for Recommender Systems
Nov 16, 2021
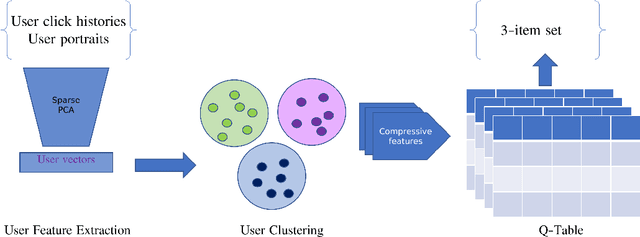

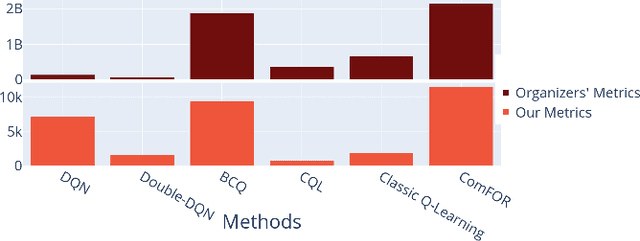
In this paper, we develop a recommender system for a game that suggests potential items to players based on their interactive behaviors to maximize revenue for the game provider. Our approach is built on a reinforcement learning-based technique and is trained on an offline data set that is publicly available on an IEEE Big Data Cup challenge. The limitation of the offline data set and the curse of high dimensionality pose significant obstacles to solving this problem. Our proposed method focuses on improving the total rewards and performance by tackling these main difficulties. More specifically, we utilized sparse PCA to extract important features of user behaviors. Our Q-learning-based system is then trained from the processed offline data set. To exploit all possible information from the provided data set, we cluster user features to different groups and build an independent Q-table for each group. Furthermore, to tackle the challenge of unknown formula for evaluation metrics, we design a metric to self-evaluate our system's performance based on the potential value the game provider might achieve and a small collection of actual evaluation metrics that we obtain from the live scoring environment. Our experiments show that our proposed metric is consistent with the results published by the challenge organizers. We have implemented the proposed training pipeline, and the results show that our method outperforms current state-of-the-art methods in terms of both total rewards and training speed. By addressing the main challenges and leveraging the state-of-the-art techniques, we have achieved the best public leaderboard result in the challenge. Furthermore, our proposed method achieved an estimated score of approximately 20% better and can be trained faster by 30 times than the best of the current state-of-the-art methods.