 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Moral Exercises for Human Oversight of AI systems: Insights from Three Pilot Studies
May 20, 2025This paper elaborates on the concept of moral exercises as a means to help AI actors cultivate virtues that enable effective human oversight of AI systems. We explore the conceptual framework and significance of moral exercises, situating them within the contexts of philosophical discourse, ancient practices, and contemporary AI ethics scholarship. We outline the core pillars of the moral exercises methodology - eliciting an engaged personal disposition, fostering relational understanding, and cultivating technomoral wisdom - and emphasize their relevance to key activities and competencies essential for human oversight of AI systems. Our argument is supported by findings from three pilot studies involving a company, a multidisciplinary team of AI researchers, and higher education students. These studies allow us to explore both the potential and the limitations of moral exercises. Based on the collected data, we offer insights into how moral exercises can foster a responsible AI culture within organizations, and suggest directions for future research.
On Prediction-Modelers and Decision-Makers: Why Fairness Requires More Than a Fair Prediction Model
Oct 09, 2023An implicit ambiguity in the field of prediction-based decision-making regards the relation between the concepts of prediction and decision. Much of the literature in the field tends to blur the boundaries between the two concepts and often simply speaks of 'fair prediction.' In this paper, we point out that a differentiation of these concepts is helpful when implementing algorithmic fairness. Even if fairness properties are related to the features of the used prediction model, what is more properly called 'fair' or 'unfair' is a decision system, not a prediction model. This is because fairness is about the consequences on human lives, created by a decision, not by a prediction. We clarify the distinction between the concepts of prediction and decision and show the different ways in which these two elements influence the final fairness properties of a prediction-based decision system. In addition to exploring this relationship conceptually and practically, we propose a framework that enables a better understanding and reasoning of the conceptual logic of creating fairness in prediction-based decision-making. In our framework, we specify different roles, namely the 'prediction-modeler' and the 'decision-maker,' and the information required from each of them for being able to implement fairness of the system. Our framework allows for deriving distinct responsibilities for both roles and discussing some insights related to ethical and legal requirements. Our contribution is twofold. First, we shift the focus from abstract algorithmic fairness to context-dependent decision-making, recognizing diverse actors with unique objectives and independent actions. Second, we provide a conceptual framework that can help structure prediction-based decision problems with respect to fairness issues, identify responsibilities, and implement fairness governance mechanisms in real-world scenarios.
Artificial Intelligence across Europe: A Study on Awareness, Attitude and Trust
Aug 19, 2023



This paper presents the results of an extensive study investigating the opinions on Artificial Intelligence (AI) of a sample of 4,006 European citizens from eight distinct countries (France, Germany, Italy, Netherlands, Poland, Romania, Spain, and Sweden). The aim of the study is to gain a better understanding of people's views and perceptions within the European context, which is already marked by important policy actions and regulatory processes. To survey the perceptions of the citizens of Europe we design and validate a new questionnaire (PAICE) structured around three dimensions: people's awareness, attitude, and trust. We observe that while awareness is characterized by a low level of self-assessed competency, the attitude toward AI is very positive for more than half of the population. Reflecting upon the collected results, we highlight implicit contradictions and identify trends that may interfere with the creation of an ecosystem of trust and the development of inclusive AI policies. The introduction of rules that ensure legal and ethical standards, along with the activity of high-level educational entities, and the promotion of AI literacy are identified as key factors in supporting a trustworthy AI ecosystem. We make some recommendations for AI governance focused on the European context and conclude with suggestions for future work.
On some Foundational Aspects of Human-Centered Artificial Intelligence
Dec 29, 2021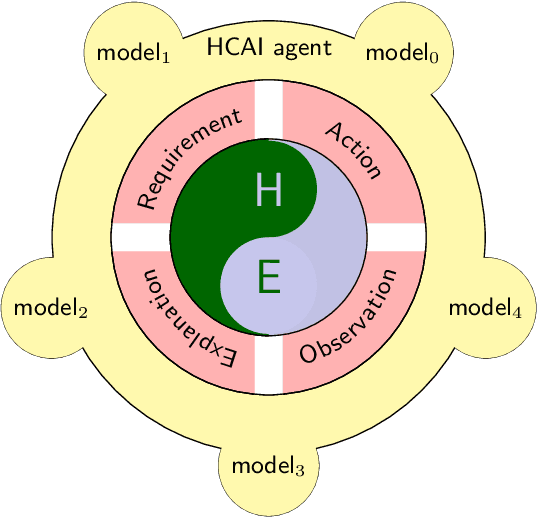
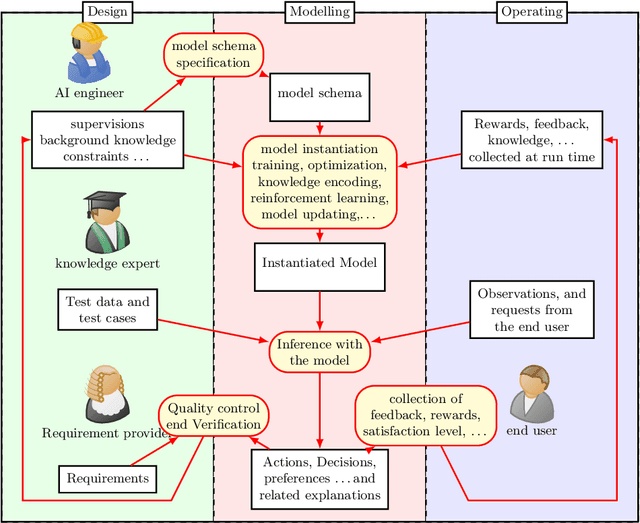
The burgeoning of AI has prompted recommendations that AI techniques should be "human-centered". However, there is no clear definition of what is meant by Human Centered Artificial Intelligence, or for short, HCAI. This paper aims to improve this situation by addressing some foundational aspects of HCAI. To do so, we introduce the term HCAI agent to refer to any physical or software computational agent equipped with AI components and that interacts and/or collaborates with humans. This article identifies five main conceptual components that participate in an HCAI agent: Observations, Requirements, Actions, Explanations and Models. We see the notion of HCAI agent, together with its components and functions, as a way to bridge the technical and non-technical discussions on human-centered AI. In this paper, we focus our analysis on scenarios consisting of a single agent operating in dynamic environments in presence of humans.
European Strategy on AI: Are we truly fostering social good?
Nov 25, 2020
Artificial intelligence (AI) is already part of our daily lives and is playing a key role in defining the economic and social shape of the future. In 2018, the European Commission introduced its AI strategy able to compete in the next years with world powers such as China and US, but relying on the respect of European values and fundamental rights. As a result, most of the Member States have published their own National Strategy with the aim to work on a coordinated plan for Europe. In this paper, we present an ongoing study on how European countries are approaching the field of Artificial Intelligence, with its promises and risks, through the lens of their national AI strategies. In particular, we aim to investigate how European countries are investing in AI and to what extent the stated plans can contribute to the benefit of the whole society. This paper reports the main findings of a qualitative analysis of the investment plans reported in 15 European National Strategies
On Social Machines for Algorithmic Regulation
Apr 30, 2019Autonomous mechanisms have been proposed to regulate certain aspects of society and are already being used to regulate business organisations. We take seriously recent proposals for algorithmic regulation of society, and we identify the existing technologies that can be used to implement them, most of them originally introduced in business contexts. We build on the notion of 'social machine' and we connect it to various ongoing trends and ideas, including crowdsourced task-work, social compiler, mechanism design, reputation management systems, and social scoring. After showing how all the building blocks of algorithmic regulation are already well in place, we discuss possible implications for human autonomy and social order. The main contribution of this paper is to identify convergent social and technical trends that are leading towards social regulation by algorithms, and to discuss the possible social, political, and ethical consequences of taking this path.
Machine Decisions and Human Consequences
Nov 16, 2018


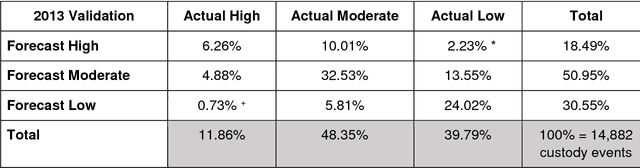
As we increasingly delegate decision-making to algorithms, whether directly or indirectly, important questions emerge in circumstances where those decisions have direct consequences for individual rights and personal opportunities, as well as for the collective good. A key problem for policymakers is that the social implications of these new methods can only be grasped if there is an adequate comprehension of their general technical underpinnings. The discussion here focuses primarily on the case of enforcement decisions in the criminal justice system, but draws on similar situations emerging from other algorithms utilised in controlling access to opportunities, to explain how machine learning works and, as a result, how decisions are made by modern intelligent algorithms or 'classifiers'. It examines the key aspects of the performance of classifiers, including how classifiers learn, the fact that they operate on the basis of correlation rather than causation, and that the term 'bias' in machine learning has a different meaning to common usage.An example of a real world 'classifier', the Harm Assessment Risk Tool (HART), is examined, through identification of its technical features: the classification method, the training data and the test data, the features and the labels, validation and performance measures. Four normative benchmarks are then considered by reference to HART: (a) prediction accuracy (b) fairness and equality before the law (c) transparency and accountability (d) informational privacy and freedom of expression, in order to demonstrate how its technical features have important normative dimensions that bear directly on the extent to which the system can be regarded as a viable and legitimate support for, or even alternative to, existing human decision-makers.