 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Fusion of Signals in Data Embedding
Nov 18, 2023



Embeddings in AI convert symbolic structures into fixed-dimensional vectors, effectively fusing multiple signals. However, the nature of this fusion in real-world data is often unclear. To address this, we introduce two methods: (1) Correlation-based Fusion Detection, measuring correlation between known attributes and embeddings, and (2) Additive Fusion Detection, viewing embeddings as sums of individual vectors representing attributes. Applying these methods, word embeddings were found to combine semantic and morphological signals. BERT sentence embeddings were decomposed into individual word vectors of subject, verb and object. In the knowledge graph-based recommender system, user embeddings, even without training on demographic data, exhibited signals of demographics like age and gender. This study highlights that embeddings are fusions of multiple signals, from Word2Vec components to demographic hints in graph embeddings.
EXTRACT: Explainable Transparent Control of Bias in Embeddings
Oct 31, 2023



Knowledge Graphs are a widely used method to represent relations between entities in various AI applications, and Graph Embedding has rapidly become a standard technique to represent Knowledge Graphs in such a way as to facilitate inferences and decisions. As this representation is obtained from behavioural data, and is not in a form readable by humans, there is a concern that it might incorporate unintended information that could lead to biases. We propose EXTRACT: a suite of Explainable and Transparent methods to ConTrol bias in knowledge graph embeddings, so as to assess and decrease the implicit presence of protected information. Our method uses Canonical Correlation Analysis (CCA) to investigate the presence, extent and origins of information leaks during training, then decomposes embeddings into a sum of their private attributes by solving a linear system. Our experiments, performed on the MovieLens1M dataset, show that a range of personal attributes can be inferred from a user's viewing behaviour and preferences, including gender, age, and occupation. Further experiments, performed on the KG20C citation dataset, show that the information about the conference in which a paper was published can be inferred from the citation network of that article. We propose four transparent methods to maintain the capability of the embedding to make the intended predictions without retaining unwanted information. A trade-off between these two goals is observed.
QBERT: Generalist Model for Processing Questions
Dec 05, 2022Using a single model across various tasks is beneficial for training and applying deep neural sequence models. We address the problem of developing generalist representations of text that can be used to perform a range of different tasks rather than being specialised to a single application. We focus on processing short questions and developing an embedding for these questions that is useful on a diverse set of problems, such as question topic classification, equivalent question recognition, and question answering. This paper introduces QBERT, a generalist model for processing questions. With QBERT, we demonstrate how we can train a multi-task network that performs all question-related tasks and has achieved similar performance compared to its corresponding single-task models.
What makes us curious? analysis of a corpus of open-domain questions
Oct 28, 2021
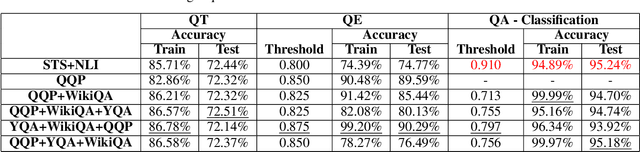

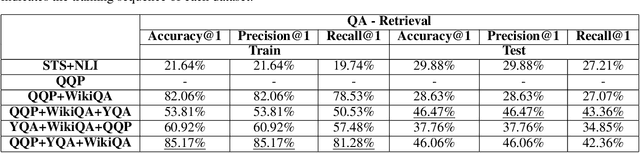
Every day people ask short questions through smart devices or online forums to seek answers to all kinds of queries. With the increasing number of questions collected it becomes difficult to provide answers to each of them, which is one of the reasons behind the growing interest in automated question answering. Some questions are similar to existing ones that have already been answered, while others could be answered by an external knowledge source such as Wikipedia. An important question is what can be revealed by analysing a large set of questions. In 2017, "We the Curious" science centre in Bristol started a project to capture the curiosity of Bristolians: the project collected more than 10,000 questions on various topics. As no rules were given during collection, the questions are truly open-domain, and ranged across a variety of topics. One important aim for the science centre was to understand what concerns its visitors had beyond science, particularly on societal and cultural issues. We addressed this question by developing an Artificial Intelligence tool that can be used to perform various processing tasks: detection of equivalence between questions; detection of topic and type; and answering of the question. As we focused on the creation of a "generalist" tool, we trained it with labelled data from different datasets. We called the resulting model QBERT. This paper describes what information we extracted from the automated analysis of the WTC corpus of open-domain questions.
On the Learnability of Concepts: With Applications to Comparing Word Embedding Algorithms
Jun 17, 2020



Word Embeddings are used widely in multiple Natural Language Processing (NLP) applications. They are coordinates associated with each word in a dictionary, inferred from statistical properties of these words in a large corpus. In this paper we introduce the notion of "concept" as a list of words that have shared semantic content. We use this notion to analyse the learnability of certain concepts, defined as the capability of a classifier to recognise unseen members of a concept after training on a random subset of it. We first use this method to measure the learnability of concepts on pretrained word embeddings. We then develop a statistical analysis of concept learnability, based on hypothesis testing and ROC curves, in order to compare the relative merits of various embedding algorithms using a fixed corpora and hyper parameters. We find that all embedding methods capture the semantic content of those word lists, but fastText performs better than the others.
* 7 Pages. AIAI 2020. 5 equations 6 tables
On Social Machines for Algorithmic Regulation
Apr 30, 2019Autonomous mechanisms have been proposed to regulate certain aspects of society and are already being used to regulate business organisations. We take seriously recent proposals for algorithmic regulation of society, and we identify the existing technologies that can be used to implement them, most of them originally introduced in business contexts. We build on the notion of 'social machine' and we connect it to various ongoing trends and ideas, including crowdsourced task-work, social compiler, mechanism design, reputation management systems, and social scoring. After showing how all the building blocks of algorithmic regulation are already well in place, we discuss possible implications for human autonomy and social order. The main contribution of this paper is to identify convergent social and technical trends that are leading towards social regulation by algorithms, and to discuss the possible social, political, and ethical consequences of taking this path.
Machine Decisions and Human Consequences
Nov 16, 2018


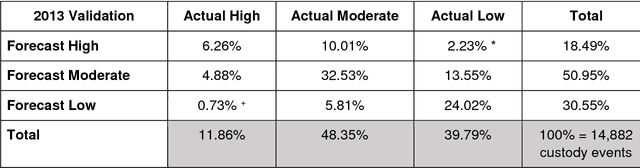
As we increasingly delegate decision-making to algorithms, whether directly or indirectly, important questions emerge in circumstances where those decisions have direct consequences for individual rights and personal opportunities, as well as for the collective good. A key problem for policymakers is that the social implications of these new methods can only be grasped if there is an adequate comprehension of their general technical underpinnings. The discussion here focuses primarily on the case of enforcement decisions in the criminal justice system, but draws on similar situations emerging from other algorithms utilised in controlling access to opportunities, to explain how machine learning works and, as a result, how decisions are made by modern intelligent algorithms or 'classifiers'. It examines the key aspects of the performance of classifiers, including how classifiers learn, the fact that they operate on the basis of correlation rather than causation, and that the term 'bias' in machine learning has a different meaning to common usage.An example of a real world 'classifier', the Harm Assessment Risk Tool (HART), is examined, through identification of its technical features: the classification method, the training data and the test data, the features and the labels, validation and performance measures. Four normative benchmarks are then considered by reference to HART: (a) prediction accuracy (b) fairness and equality before the law (c) transparency and accountability (d) informational privacy and freedom of expression, in order to demonstrate how its technical features have important normative dimensions that bear directly on the extent to which the system can be regarded as a viable and legitimate support for, or even alternative to, existing human decision-makers.
Biased Embeddings from Wild Data: Measuring, Understanding and Removing
Jun 16, 2018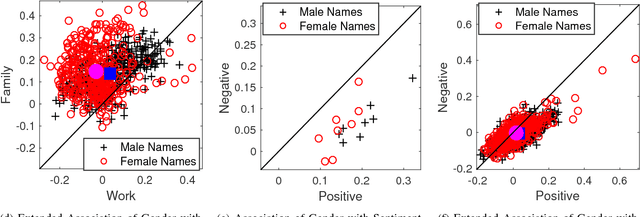

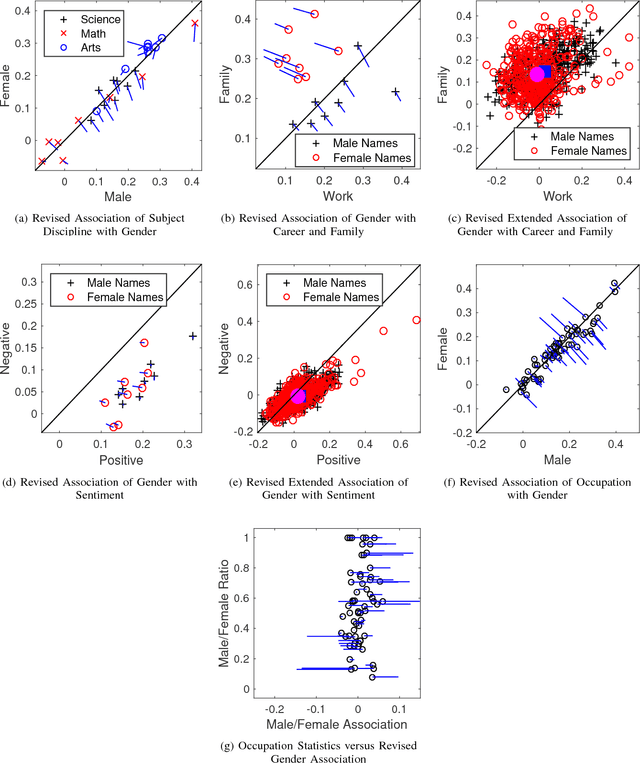

Many modern Artificial Intelligence (AI) systems make use of data embeddings, particularly in the domain of Natural Language Processing (NLP). These embeddings are learnt from data that has been gathered "from the wild" and have been found to contain unwanted biases. In this paper we make three contributions towards measuring, understanding and removing this problem. We present a rigorous way to measure some of these biases, based on the use of word lists created for social psychology applications; we observe how gender bias in occupations reflects actual gender bias in the same occupations in the real world; and finally we demonstrate how a simple projection can significantly reduce the effects of embedding bias. All this is part of an ongoing effort to understand how trust can be built into AI systems.
Right for the Right Reason: Training Agnostic Networks
Jun 16, 2018



We consider the problem of a neural network being requested to classify images (or other inputs) without making implicit use of a "protected concept", that is a concept that should not play any role in the decision of the network. Typically these concepts include information such as gender or race, or other contextual information such as image backgrounds that might be implicitly reflected in unknown correlations with other variables, making it insufficient to simply remove them from the input features. In other words, making accurate predictions is not good enough if those predictions rely on information that should not be used: predictive performance is not the only important metric for learning systems. We apply a method developed in the context of domain adaptation to address this problem of "being right for the right reason", where we request a classifier to make a decision in a way that is entirely 'agnostic' to a given protected concept (e.g. gender, race, background etc.), even if this could be implicitly reflected in other attributes via unknown correlations. After defining the concept of an 'agnostic model', we demonstrate how the Domain-Adversarial Neural Network can remove unwanted information from a model using a gradient reversal layer.
History Playground: A Tool for Discovering Temporal Trends in Massive Textual Corpora
Jun 04, 2018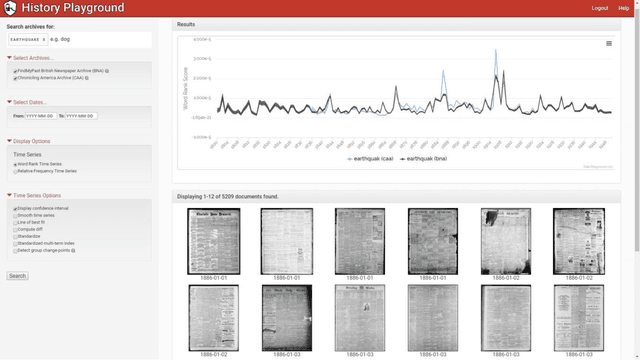
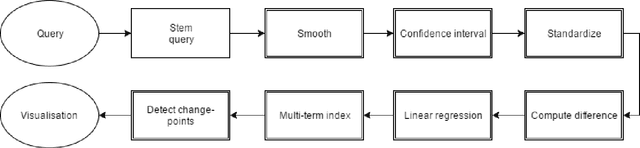
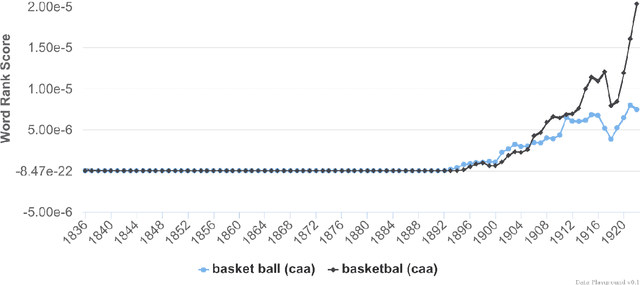
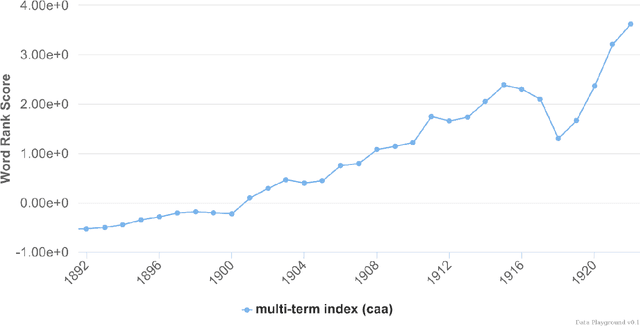
Recent studies have shown that macroscopic patterns of continuity and change over the course of centuries can be detected through the analysis of time series extracted from massive textual corpora. Similar data-driven approaches have already revolutionised the natural sciences, and are widely believed to hold similar potential for the humanities and social sciences, driven by the mass-digitisation projects that are currently under way, and coupled with the ever-increasing number of documents which are "born digital". As such, new interactive tools are required to discover and extract macroscopic patterns from these vast quantities of textual data. Here we present History Playground, an interactive web-based tool for discovering trends in massive textual corpora. The tool makes use of scalable algorithms to first extract trends from textual corpora, before making them available for real-time search and discovery, presenting users with an interface to explore the data. Included in the tool are algorithms for standardization, regression, change-point detection in the relative frequencies of ngrams, multi-term indices and comparison of trends across different corpora.