 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiased Embeddings from Wild Data: Measuring, Understanding and Removing
Jun 16, 2018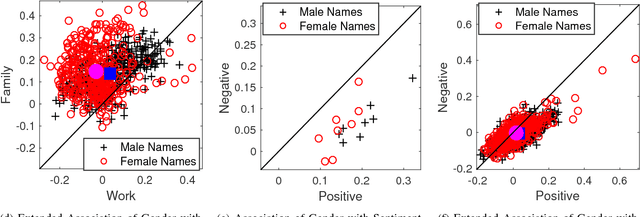

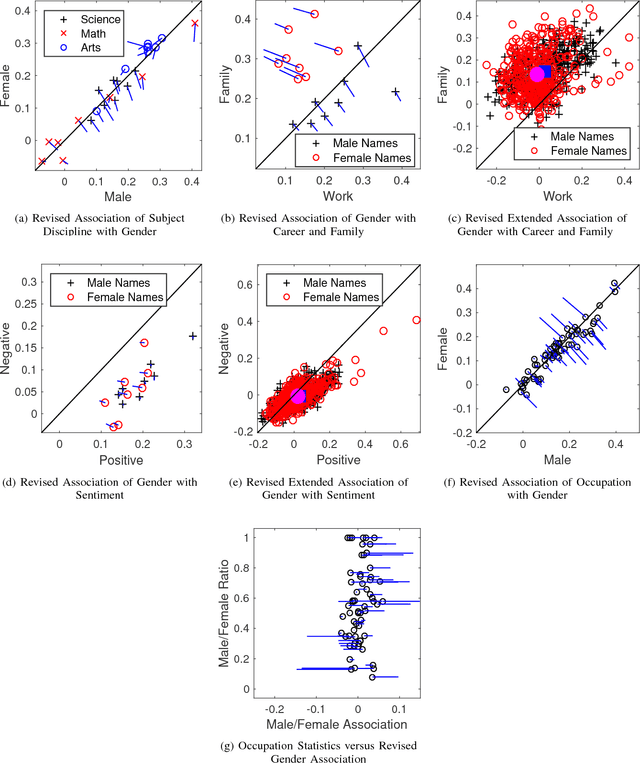

Many modern Artificial Intelligence (AI) systems make use of data embeddings, particularly in the domain of Natural Language Processing (NLP). These embeddings are learnt from data that has been gathered "from the wild" and have been found to contain unwanted biases. In this paper we make three contributions towards measuring, understanding and removing this problem. We present a rigorous way to measure some of these biases, based on the use of word lists created for social psychology applications; we observe how gender bias in occupations reflects actual gender bias in the same occupations in the real world; and finally we demonstrate how a simple projection can significantly reduce the effects of embedding bias. All this is part of an ongoing effort to understand how trust can be built into AI systems.
Right for the Right Reason: Training Agnostic Networks
Jun 16, 2018



We consider the problem of a neural network being requested to classify images (or other inputs) without making implicit use of a "protected concept", that is a concept that should not play any role in the decision of the network. Typically these concepts include information such as gender or race, or other contextual information such as image backgrounds that might be implicitly reflected in unknown correlations with other variables, making it insufficient to simply remove them from the input features. In other words, making accurate predictions is not good enough if those predictions rely on information that should not be used: predictive performance is not the only important metric for learning systems. We apply a method developed in the context of domain adaptation to address this problem of "being right for the right reason", where we request a classifier to make a decision in a way that is entirely 'agnostic' to a given protected concept (e.g. gender, race, background etc.), even if this could be implicitly reflected in other attributes via unknown correlations. After defining the concept of an 'agnostic model', we demonstrate how the Domain-Adversarial Neural Network can remove unwanted information from a model using a gradient reversal layer.
History Playground: A Tool for Discovering Temporal Trends in Massive Textual Corpora
Jun 04, 2018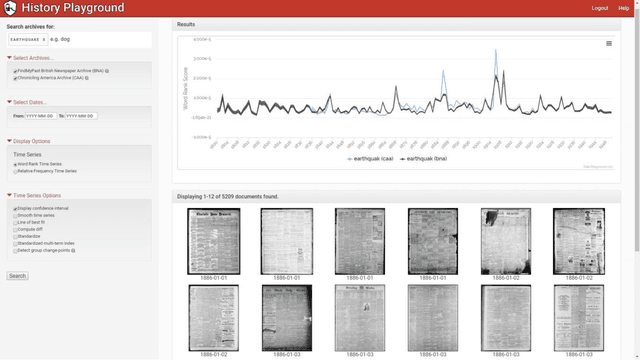
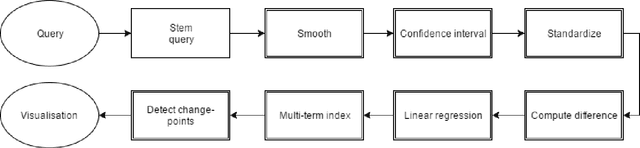
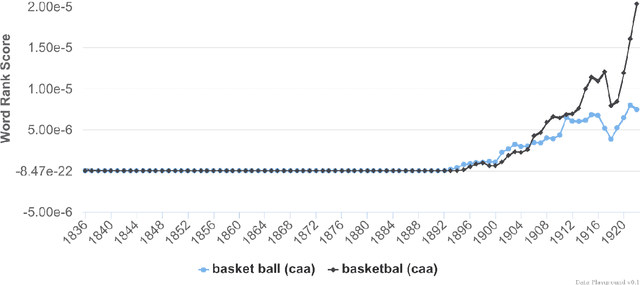
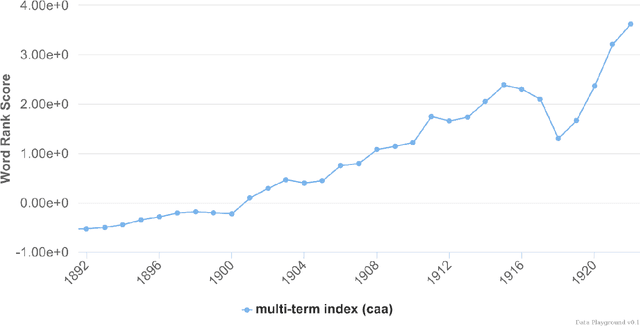
Recent studies have shown that macroscopic patterns of continuity and change over the course of centuries can be detected through the analysis of time series extracted from massive textual corpora. Similar data-driven approaches have already revolutionised the natural sciences, and are widely believed to hold similar potential for the humanities and social sciences, driven by the mass-digitisation projects that are currently under way, and coupled with the ever-increasing number of documents which are "born digital". As such, new interactive tools are required to discover and extract macroscopic patterns from these vast quantities of textual data. Here we present History Playground, an interactive web-based tool for discovering trends in massive textual corpora. The tool makes use of scalable algorithms to first extract trends from textual corpora, before making them available for real-time search and discovery, presenting users with an interface to explore the data. Included in the tool are algorithms for standardization, regression, change-point detection in the relative frequencies of ngrams, multi-term indices and comparison of trends across different corpora.
The Anatomy of a Modular System for Media Content Analysis
Jun 04, 2018Intelligent systems for the annotation of media content are increasingly being used for the automation of parts of social science research. In this domain the problem of integrating various Artificial Intelligence (AI) algorithms into a single intelligent system arises spontaneously. As part of our ongoing effort in automating media content analysis for the social sciences, we have built a modular system by combining multiple AI modules into a flexible framework in which they can cooperate in complex tasks. Our system combines data gathering, machine translation, topic classification, extraction and annotation of entities and social networks, as well as many other tasks that have been perfected over the past years of AI research. Over the last few years, it has allowed us to realise a series of scientific studies over a vast range of applications including comparative studies between news outlets and media content in different countries, modelling of user preferences, and monitoring public mood. The framework is flexible and allows the design and implementation of modular agents, where simple modules cooperate in the annotation of a large dataset without central coordination.