 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Anatomy of a Modular System for Media Content Analysis
Jun 04, 2018Intelligent systems for the annotation of media content are increasingly being used for the automation of parts of social science research. In this domain the problem of integrating various Artificial Intelligence (AI) algorithms into a single intelligent system arises spontaneously. As part of our ongoing effort in automating media content analysis for the social sciences, we have built a modular system by combining multiple AI modules into a flexible framework in which they can cooperate in complex tasks. Our system combines data gathering, machine translation, topic classification, extraction and annotation of entities and social networks, as well as many other tasks that have been perfected over the past years of AI research. Over the last few years, it has allowed us to realise a series of scientific studies over a vast range of applications including comparative studies between news outlets and media content in different countries, modelling of user preferences, and monitoring public mood. The framework is flexible and allows the design and implementation of modular agents, where simple modules cooperate in the annotation of a large dataset without central coordination.
Beyond the technical challenges for deploying Machine Learning solutions in a software company
Aug 08, 2017
Recently software development companies started to embrace Machine Learning (ML) techniques for introducing a series of advanced functionality in their products such as personalisation of the user experience, improved search, content recommendation and automation. The technical challenges for tackling these problems are heavily researched in literature. A less studied area is a pragmatic approach to the role of humans in a complex modern industrial environment where ML based systems are developed. Key stakeholders affect the system from inception and up to operation and maintenance. Product managers want to embed "smart" experiences for their users and drive the decisions on what should be built next; software engineers are challenged to build or utilise ML software tools that require skills that are well outside of their comfort zone; legal and risk departments may influence design choices and data access; operations teams are requested to maintain ML systems which are non-stationary in their nature and change behaviour over time; and finally ML practitioners should communicate with all these stakeholders to successfully build a reliable system. This paper discusses some of the challenges we faced in Atlassian as we started investing more in the ML space.
Efficient Classification of Multi-Labelled Text Streams by Clashing
Apr 12, 2016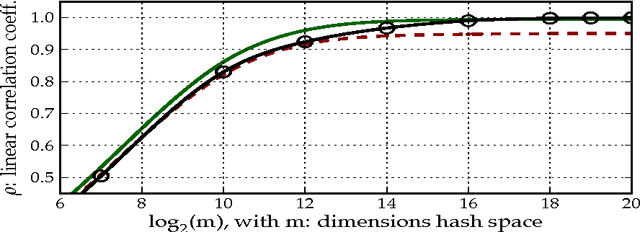
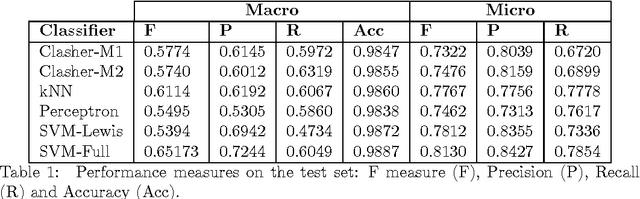
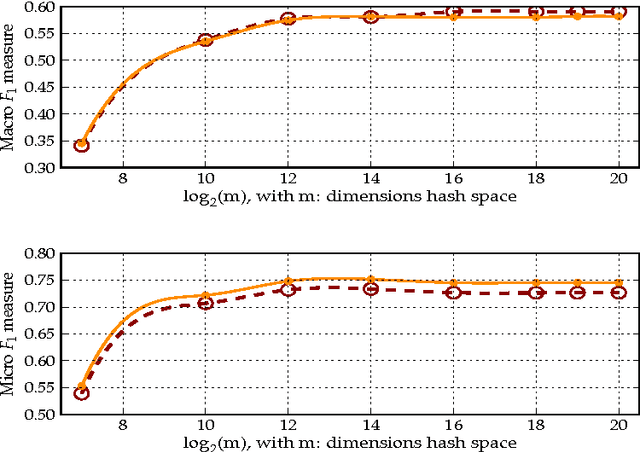
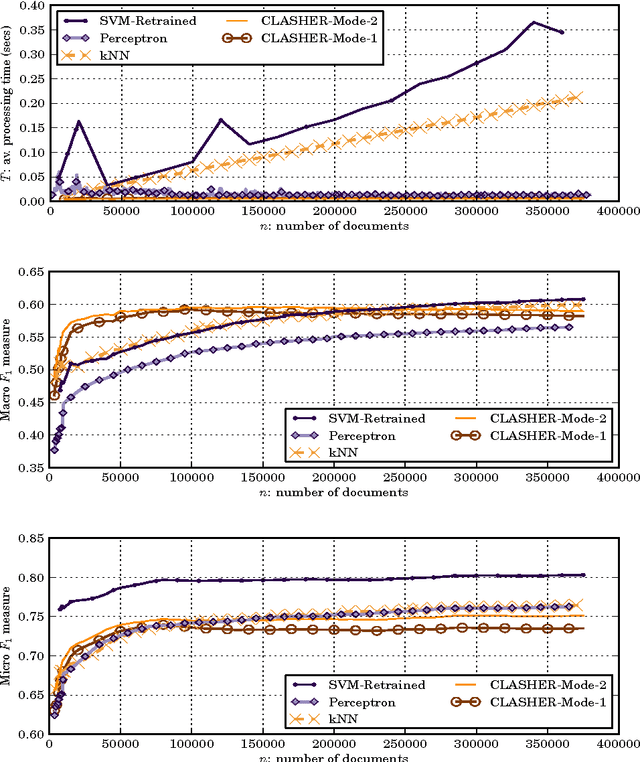
We present a method for the classification of multi-labelled text documents explicitly designed for data stream applications that require to process a virtually infinite sequence of data using constant memory and constant processing time. Our method is composed of an online procedure used to efficiently map text into a low-dimensional feature space and a partition of this space into a set of regions for which the system extracts and keeps statistics used to predict multi-label text annotations. Documents are fed into the system as a sequence of words, mapped to a region of the partition, and annotated using the statistics computed from the labelled instances colliding in the same region. This approach is referred to as clashing. We illustrate the method in real-world text data, comparing the results with those obtained using other text classifiers. In addition, we provide an analysis about the effect of the representation space dimensionality on the predictive performance of the system. Our results show that the online embedding indeed approximates the geometry of the full corpus-wise TF and TF-IDF space. The model obtains competitive F measures with respect to the most accurate methods, using significantly fewer computational resources. In addition, the method achieves a higher macro-averaged F measure than methods with similar running time. Furthermore, the system is able to learn faster than the other methods from partially labelled streams.
Finite-Time Analysis of Kernelised Contextual Bandits
Sep 26, 2013
We tackle the problem of online reward maximisation over a large finite set of actions described by their contexts. We focus on the case when the number of actions is too big to sample all of them even once. However we assume that we have access to the similarities between actions' contexts and that the expected reward is an arbitrary linear function of the contexts' images in the related reproducing kernel Hilbert space (RKHS). We propose KernelUCB, a kernelised UCB algorithm, and give a cumulative regret bound through a frequentist analysis. For contextual bandits, the related algorithm GP-UCB turns out to be a special case of our algorithm, and our finite-time analysis improves the regret bound of GP-UCB for the agnostic case, both in the terms of the kernel-dependent quantity and the RKHS norm of the reward function. Moreover, for the linear kernel, our regret bound matches the lower bound for contextual linear bandits.