 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Method to Predict Semantic Relations on Artificial Intelligence Papers
Jan 24, 2022
Predicting the emergence of links in large evolving networks is a difficult task with many practical applications. Recently, the Science4cast competition has illustrated this challenge presenting a network of 64.000 AI concepts and asking the participants to predict which topics are going to be researched together in the future. In this paper, we present a solution to this problem based on a new family of deep learning approaches, namely Graph Neural Networks. The results of the challenge show that our solution is competitive even if we had to impose severe restrictions to obtain a computationally efficient and parsimonious model: ignoring the intrinsic dynamics of the graph and using only a small subset of the nodes surrounding a target link. Preliminary experiments presented in this paper suggest the model is learning two related, but different patterns: the absorption of a node by a sub-graph and union of more dense sub-graphs. The model seems to excel at recognizing the first type of pattern.
Self-Supervised Bernoulli Autoencoders for Semi-Supervised Hashing
Jul 17, 2020



Semantic hashing is an emerging technique for large-scale similarity search based on representing high-dimensional data using similarity-preserving binary codes used for efficient indexing and search. It has recently been shown that variational autoencoders, with Bernoulli latent representations parametrized by neural nets, can be successfully trained to learn such codes in supervised and unsupervised scenarios, improving on more traditional methods thanks to their ability to handle the binary constraints architecturally. However, the scenario where labels are scarce has not been studied yet. This paper investigates the robustness of hashing methods based on variational autoencoders to the lack of supervision, focusing on two semi-supervised approaches currently in use. The first augments the variational autoencoder's training objective to jointly model the distribution over the data and the class labels. The second approach exploits the annotations to define an additional pairwise loss that enforces consistency between the similarity in the code (Hamming) space and the similarity in the label space. Our experiments show that both methods can significantly increase the hash codes' quality. The pairwise approach can exhibit an advantage when the number of labelled points is large. However, we found that this method degrades quickly and loses its advantage when labelled samples decrease. To circumvent this problem, we propose a novel supervision method in which the model uses its label distribution predictions to implement the pairwise objective. Compared to the best baseline, this procedure yields similar performance in fully supervised settings but improves the results significantly when labelled data is scarce. Our code is made publicly available at https://github.com/amacaluso/SSB-VAE.
Efficient Classification of Multi-Labelled Text Streams by Clashing
Apr 12, 2016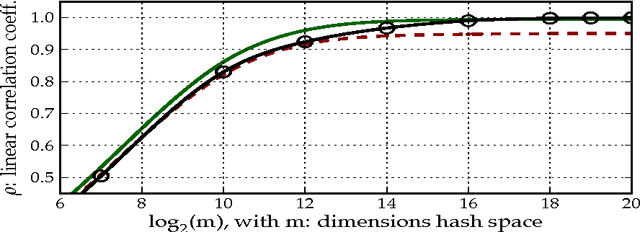
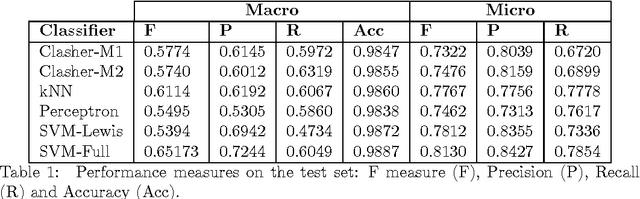
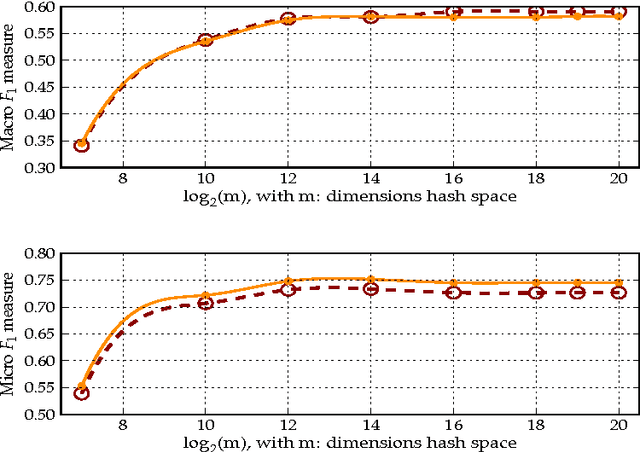
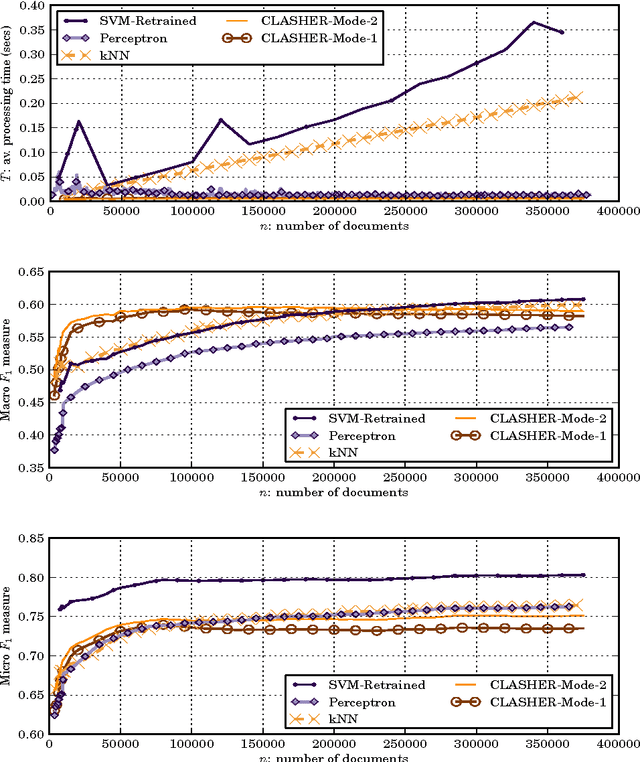
We present a method for the classification of multi-labelled text documents explicitly designed for data stream applications that require to process a virtually infinite sequence of data using constant memory and constant processing time. Our method is composed of an online procedure used to efficiently map text into a low-dimensional feature space and a partition of this space into a set of regions for which the system extracts and keeps statistics used to predict multi-label text annotations. Documents are fed into the system as a sequence of words, mapped to a region of the partition, and annotated using the statistics computed from the labelled instances colliding in the same region. This approach is referred to as clashing. We illustrate the method in real-world text data, comparing the results with those obtained using other text classifiers. In addition, we provide an analysis about the effect of the representation space dimensionality on the predictive performance of the system. Our results show that the online embedding indeed approximates the geometry of the full corpus-wise TF and TF-IDF space. The model obtains competitive F measures with respect to the most accurate methods, using significantly fewer computational resources. In addition, the method achieves a higher macro-averaged F measure than methods with similar running time. Furthermore, the system is able to learn faster than the other methods from partially labelled streams.