 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAQA: A Quantum Framework for Supervised Learning
Mar 20, 2023Quantum Machine Learning has the potential to improve traditional machine learning methods and overcome some of the main limitations imposed by the classical computing paradigm. However, the practical advantages of using quantum resources to solve pattern recognition tasks are still to be demonstrated. This work proposes a universal, efficient framework that can reproduce the output of a plethora of classical supervised machine learning algorithms exploiting quantum computation's advantages. The proposed framework is named Multiple Aggregator Quantum Algorithm (MAQA) due to its capability to combine multiple and diverse functions to solve typical supervised learning problems. In its general formulation, MAQA can be potentially adopted as the quantum counterpart of all those models falling into the scheme of aggregation of multiple functions, such as ensemble algorithms and neural networks. From a computational point of view, the proposed framework allows generating an exponentially large number of different transformations of the input at the cost of increasing the depth of the corresponding quantum circuit linearly. Thus, MAQA produces a model with substantial descriptive power to broaden the horizon of possible applications of quantum machine learning with a computational advantage over classical methods. As a second meaningful addition, we discuss the adoption of the proposed framework as hybrid quantum-classical and fault-tolerant quantum algorithm.
Enabling Non-Linear Quantum Operations through Variational Quantum Splines
Mar 13, 2023The postulates of quantum mechanics impose only unitary transformations on quantum states, which is a severe limitation for quantum machine learning algorithms. Quantum Splines (QSplines) have recently been proposed to approximate quantum activation functions to introduce non-linearity in quantum algorithms. However, QSplines make use of the HHL as a subroutine and require a fault-tolerant quantum computer to be correctly implemented. This work proposes the Generalised QSplines (GQSplines), a novel method for approximating non-linear quantum activation functions using hybrid quantum-classical computation. The GQSplines overcome the highly demanding requirements of the original QSplines in terms of quantum hardware and can be implemented using near-term quantum computers. Furthermore, the proposed method relies on a flexible problem representation for non-linear approximation and it is suitable to be embedded in existing quantum neural network architectures. In addition, we provide a practical implementation of GQSplines using Pennylane and show that our model outperforms the original QSplines in terms of quality of fitting.
Quantum Splines for Non-Linear Approximations
Mar 09, 2023



Quantum Computing offers a new paradigm for efficient computing and many AI applications could benefit from its potential boost in performance. However, the main limitation is the constraint to linear operations that hampers the representation of complex relationships in data. In this work, we propose an efficient implementation of quantum splines for non-linear approximation. In particular, we first discuss possible parametrisations, and select the most convenient for exploiting the HHL algorithm to obtain the estimates of spline coefficients. Then, we investigate QSpline performance as an evaluation routine for some of the most popular activation functions adopted in ML. Finally, a detailed comparison with classical alternatives to the HHL is also presented.
OptAGAN: Entropy-based finetuning on text VAE-GAN
Sep 01, 2021

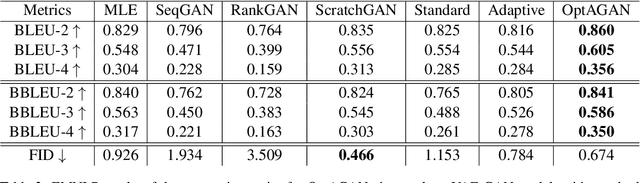
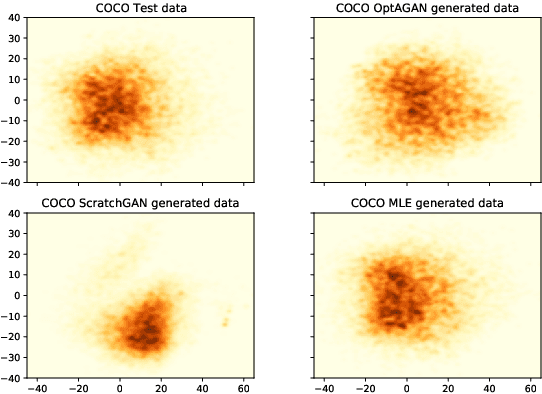
Transfer learning through large pre-trained models has changed the landscape of current applications in natural language processing (NLP). Recently Optimus, a variational autoencoder (VAE) which combines two pre-trained models, BERT and GPT-2, has been released, and its combination with generative adversial networks (GANs) has been shown to produce novel, yet very human-looking text. The Optimus and GANs combination avoids the troublesome application of GANs to the discrete domain of text, and prevents the exposure bias of standard maximum likelihood methods. We combine the training of GANs in the latent space, with the finetuning of the decoder of Optimus for single word generation. This approach lets us model both the high-level features of the sentences, and the low-level word-by-word generation. We finetune using reinforcement learning (RL) by exploiting the structure of GPT-2 and by adding entropy-based intrinsically motivated rewards to balance between quality and diversity. We benchmark the results of the VAE-GAN model, and show the improvements brought by our RL finetuning on three widely used datasets for text generation, with results that greatly surpass the current state-of-the-art for the quality of the generated texts.
Self-Supervised Bernoulli Autoencoders for Semi-Supervised Hashing
Jul 17, 2020



Semantic hashing is an emerging technique for large-scale similarity search based on representing high-dimensional data using similarity-preserving binary codes used for efficient indexing and search. It has recently been shown that variational autoencoders, with Bernoulli latent representations parametrized by neural nets, can be successfully trained to learn such codes in supervised and unsupervised scenarios, improving on more traditional methods thanks to their ability to handle the binary constraints architecturally. However, the scenario where labels are scarce has not been studied yet. This paper investigates the robustness of hashing methods based on variational autoencoders to the lack of supervision, focusing on two semi-supervised approaches currently in use. The first augments the variational autoencoder's training objective to jointly model the distribution over the data and the class labels. The second approach exploits the annotations to define an additional pairwise loss that enforces consistency between the similarity in the code (Hamming) space and the similarity in the label space. Our experiments show that both methods can significantly increase the hash codes' quality. The pairwise approach can exhibit an advantage when the number of labelled points is large. However, we found that this method degrades quickly and loses its advantage when labelled samples decrease. To circumvent this problem, we propose a novel supervision method in which the model uses its label distribution predictions to implement the pairwise objective. Compared to the best baseline, this procedure yields similar performance in fully supervised settings but improves the results significantly when labelled data is scarce. Our code is made publicly available at https://github.com/amacaluso/SSB-VAE.
Quantum Ensemble for Classification
Jul 03, 2020



A powerful way to improve performance in machine learning is to construct an ensemble that combines the predictions of multiple models. Ensemble methods are often much more accurate and lower variance than the individual classifiers that make them up but have high requirements in terms of memory and computational time. In fact, a large number of alternative algorithms is usually adopted, each requiring to query all available data. We propose a new quantum algorithm that exploits quantum superposition, entanglement and interference to build an ensemble of classification models. Thanks to the generation of the several quantum trajectories in superposition, we obtain $B$ transformations of the quantum state which encodes the training set in only $log\left(B\right)$ operations. This implies an exponential speed-up in the size of the ensemble with respect to classical methods. Furthermore, when considering the overall cost of the algorithm, we show that the training of a single weak classifier impacts additively rather than multiplicatively, as it usually happens. We also present small-scale experiments, defining a quantum version of the cosine classifier and using the IBM qiskit environment to show how the algorithm works.
Fast and Scalable Lasso via Stochastic Frank-Wolfe Methods with a Convergence Guarantee
Oct 24, 2015



Frank-Wolfe (FW) algorithms have been often proposed over the last few years as efficient solvers for a variety of optimization problems arising in the field of Machine Learning. The ability to work with cheap projection-free iterations and the incremental nature of the method make FW a very effective choice for many large-scale problems where computing a sparse model is desirable. In this paper, we present a high-performance implementation of the FW method tailored to solve large-scale Lasso regression problems, based on a randomized iteration, and prove that the convergence guarantees of the standard FW method are preserved in the stochastic setting. We show experimentally that our algorithm outperforms several existing state of the art methods, including the Coordinate Descent algorithm by Friedman et al. (one of the fastest known Lasso solvers), on several benchmark datasets with a very large number of features, without sacrificing the accuracy of the model. Our results illustrate that the algorithm is able to generate the complete regularization path on problems of size up to four million variables in less than one minute.
Training Support Vector Machines Using Frank-Wolfe Optimization Methods
Dec 04, 2012



Training a Support Vector Machine (SVM) requires the solution of a quadratic programming problem (QP) whose computational complexity becomes prohibitively expensive for large scale datasets. Traditional optimization methods cannot be directly applied in these cases, mainly due to memory restrictions. By adopting a slightly different objective function and under mild conditions on the kernel used within the model, efficient algorithms to train SVMs have been devised under the name of Core Vector Machines (CVMs). This framework exploits the equivalence of the resulting learning problem with the task of building a Minimal Enclosing Ball (MEB) problem in a feature space, where data is implicitly embedded by a kernel function. In this paper, we improve on the CVM approach by proposing two novel methods to build SVMs based on the Frank-Wolfe algorithm, recently revisited as a fast method to approximate the solution of a MEB problem. In contrast to CVMs, our algorithms do not require to compute the solutions of a sequence of increasingly complex QPs and are defined by using only analytic optimization steps. Experiments on a large collection of datasets show that our methods scale better than CVMs in most cases, sometimes at the price of a slightly lower accuracy. As CVMs, the proposed methods can be easily extended to machine learning problems other than binary classification. However, effective classifiers are also obtained using kernels which do not satisfy the condition required by CVMs and can thus be used for a wider set of problems.