 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Fusion of Signals in Data Embedding
Nov 18, 2023



Embeddings in AI convert symbolic structures into fixed-dimensional vectors, effectively fusing multiple signals. However, the nature of this fusion in real-world data is often unclear. To address this, we introduce two methods: (1) Correlation-based Fusion Detection, measuring correlation between known attributes and embeddings, and (2) Additive Fusion Detection, viewing embeddings as sums of individual vectors representing attributes. Applying these methods, word embeddings were found to combine semantic and morphological signals. BERT sentence embeddings were decomposed into individual word vectors of subject, verb and object. In the knowledge graph-based recommender system, user embeddings, even without training on demographic data, exhibited signals of demographics like age and gender. This study highlights that embeddings are fusions of multiple signals, from Word2Vec components to demographic hints in graph embeddings.
EXTRACT: Explainable Transparent Control of Bias in Embeddings
Oct 31, 2023



Knowledge Graphs are a widely used method to represent relations between entities in various AI applications, and Graph Embedding has rapidly become a standard technique to represent Knowledge Graphs in such a way as to facilitate inferences and decisions. As this representation is obtained from behavioural data, and is not in a form readable by humans, there is a concern that it might incorporate unintended information that could lead to biases. We propose EXTRACT: a suite of Explainable and Transparent methods to ConTrol bias in knowledge graph embeddings, so as to assess and decrease the implicit presence of protected information. Our method uses Canonical Correlation Analysis (CCA) to investigate the presence, extent and origins of information leaks during training, then decomposes embeddings into a sum of their private attributes by solving a linear system. Our experiments, performed on the MovieLens1M dataset, show that a range of personal attributes can be inferred from a user's viewing behaviour and preferences, including gender, age, and occupation. Further experiments, performed on the KG20C citation dataset, show that the information about the conference in which a paper was published can be inferred from the citation network of that article. We propose four transparent methods to maintain the capability of the embedding to make the intended predictions without retaining unwanted information. A trade-off between these two goals is observed.
QBERT: Generalist Model for Processing Questions
Dec 05, 2022Using a single model across various tasks is beneficial for training and applying deep neural sequence models. We address the problem of developing generalist representations of text that can be used to perform a range of different tasks rather than being specialised to a single application. We focus on processing short questions and developing an embedding for these questions that is useful on a diverse set of problems, such as question topic classification, equivalent question recognition, and question answering. This paper introduces QBERT, a generalist model for processing questions. With QBERT, we demonstrate how we can train a multi-task network that performs all question-related tasks and has achieved similar performance compared to its corresponding single-task models.
What makes us curious? analysis of a corpus of open-domain questions
Oct 28, 2021
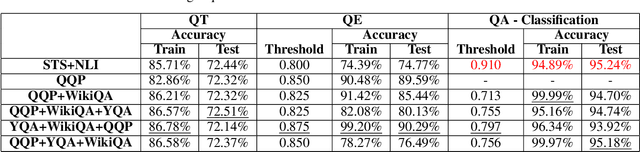

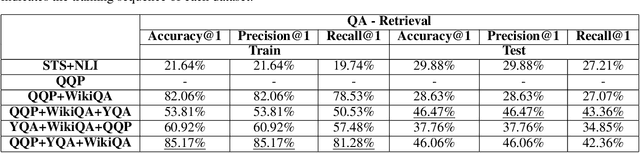
Every day people ask short questions through smart devices or online forums to seek answers to all kinds of queries. With the increasing number of questions collected it becomes difficult to provide answers to each of them, which is one of the reasons behind the growing interest in automated question answering. Some questions are similar to existing ones that have already been answered, while others could be answered by an external knowledge source such as Wikipedia. An important question is what can be revealed by analysing a large set of questions. In 2017, "We the Curious" science centre in Bristol started a project to capture the curiosity of Bristolians: the project collected more than 10,000 questions on various topics. As no rules were given during collection, the questions are truly open-domain, and ranged across a variety of topics. One important aim for the science centre was to understand what concerns its visitors had beyond science, particularly on societal and cultural issues. We addressed this question by developing an Artificial Intelligence tool that can be used to perform various processing tasks: detection of equivalence between questions; detection of topic and type; and answering of the question. As we focused on the creation of a "generalist" tool, we trained it with labelled data from different datasets. We called the resulting model QBERT. This paper describes what information we extracted from the automated analysis of the WTC corpus of open-domain questions.