 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Multiple Abstractions in Episodic RL via Reward Shaping
Feb 28, 2023



One major limitation to the applicability of Reinforcement Learning (RL) to many practical domains is the large number of samples required to learn an optimal policy. To address this problem and improve learning efficiency, we consider a linear hierarchy of abstraction layers of the Markov Decision Process (MDP) underlying the target domain. Each layer is an MDP representing a coarser model of the one immediately below in the hierarchy. In this work, we propose a novel form of Reward Shaping where the solution obtained at the abstract level is used to offer rewards to the more concrete MDP, in such a way that the abstract solution guides the learning in the more complex domain. In contrast with other works in Hierarchical RL, our technique has few requirements in the design of the abstract models and it is also tolerant to modeling errors, thus making the proposed approach practical. We formally analyze the relationship between the abstract models and the exploration heuristic induced in the lower-level domain. Moreover, we prove that the method guarantees optimal convergence and we demonstrate its effectiveness experimentally.
A Hierarchical Framework for Collaborative Artificial Intelligence
Dec 14, 2022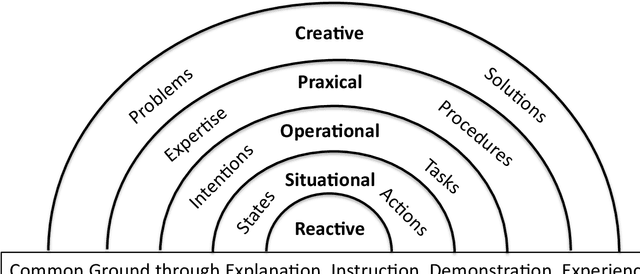
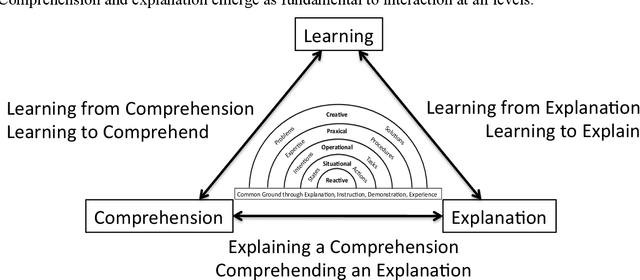
We propose a hierarchical framework for collaborative intelligent systems. This framework organizes research challenges based on the nature of the collaborative activity and the information that must be shared, with each level building on capabilities provided by lower levels. We review research paradigms at each level, with a description of classical engineering-based approaches and modern alternatives based on machine learning, illustrated with a running example using a hypothetical personal service robot. We discuss cross-cutting issues that occur at all levels, focusing on the problem of communicating and sharing comprehension, the role of explanation and the social nature of collaboration. We conclude with a summary of research challenges and a discussion of the potential for economic and societal impact provided by technologies that enhance human abilities and empower people and society through collaboration with Intelligent Systems.
On some Foundational Aspects of Human-Centered Artificial Intelligence
Dec 29, 2021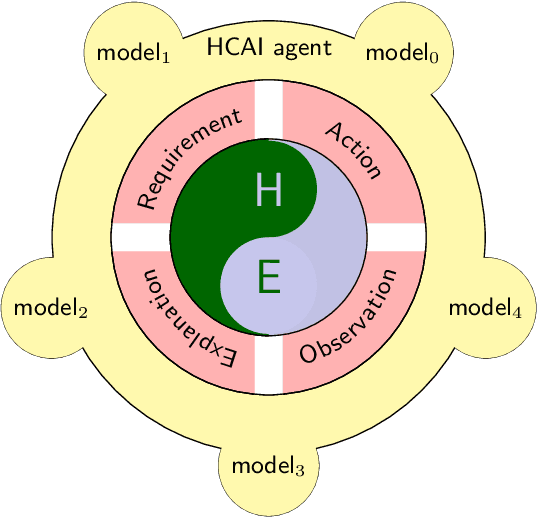
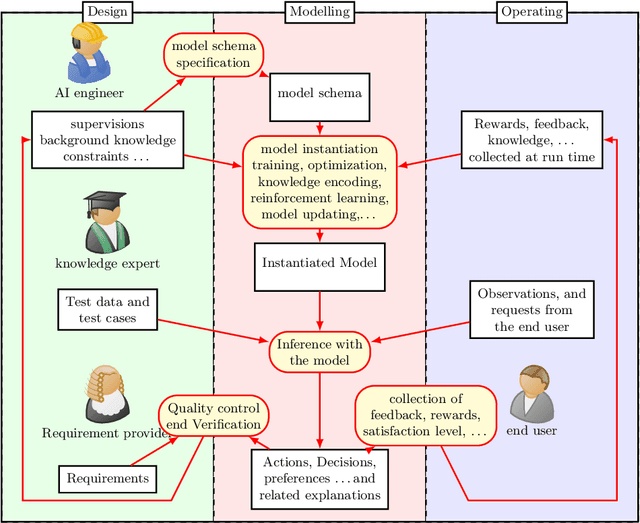
The burgeoning of AI has prompted recommendations that AI techniques should be "human-centered". However, there is no clear definition of what is meant by Human Centered Artificial Intelligence, or for short, HCAI. This paper aims to improve this situation by addressing some foundational aspects of HCAI. To do so, we introduce the term HCAI agent to refer to any physical or software computational agent equipped with AI components and that interacts and/or collaborates with humans. This article identifies five main conceptual components that participate in an HCAI agent: Observations, Requirements, Actions, Explanations and Models. We see the notion of HCAI agent, together with its components and functions, as a way to bridge the technical and non-technical discussions on human-centered AI. In this paper, we focus our analysis on scenarios consisting of a single agent operating in dynamic environments in presence of humans.
On the Effectiveness of Neural Ensembles for Image Classification with Small Datasets
Nov 29, 2021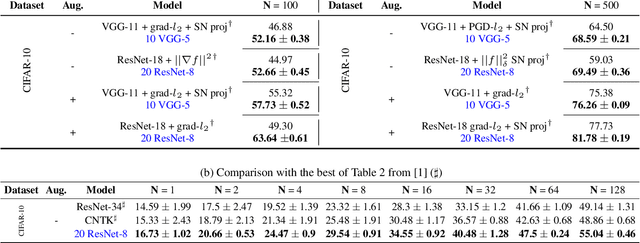
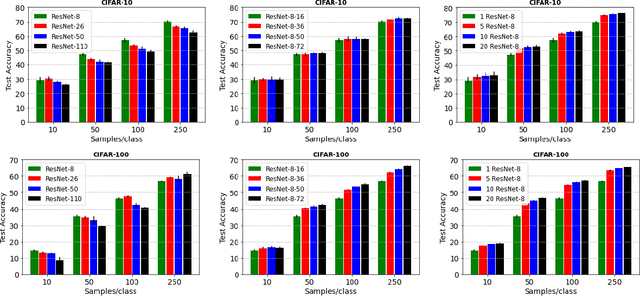
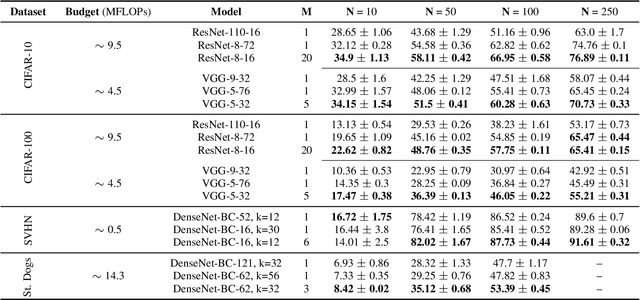
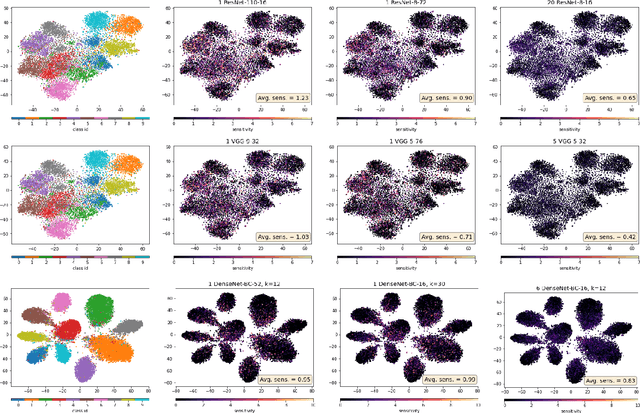
Deep neural networks represent the gold standard for image classification. However, they usually need large amounts of data to reach superior performance. In this work, we focus on image classification problems with a few labeled examples per class and improve data efficiency by using an ensemble of relatively small networks. For the first time, our work broadly studies the existing concept of neural ensembling in domains with small data, through extensive validation using popular datasets and architectures. We compare ensembles of networks to their deeper or wider single competitors given a total fixed computational budget. We show that ensembling relatively shallow networks is a simple yet effective technique that is generally better than current state-of-the-art approaches for learning from small datasets. Finally, we present our interpretation according to which neural ensembles are more sample efficient because they learn simpler functions.
A Strong Baseline for the VIPriors Data-Efficient Image Classification Challenge
Sep 28, 2021
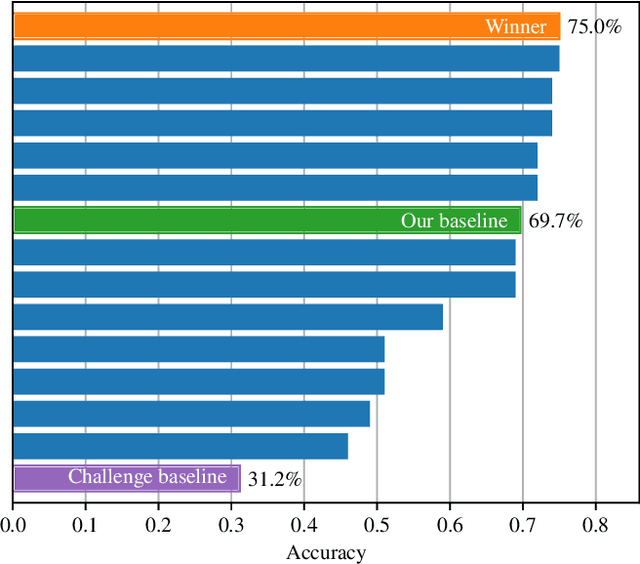
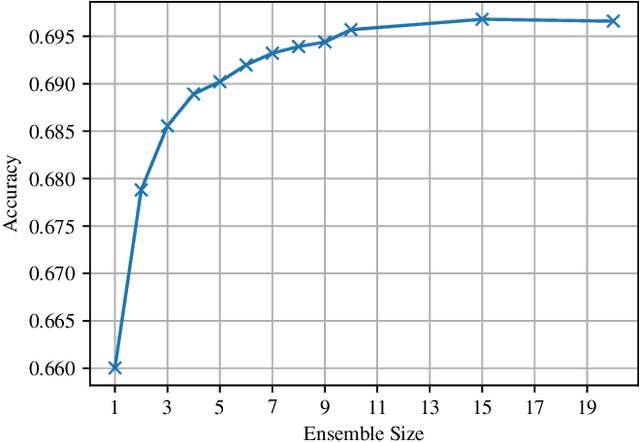
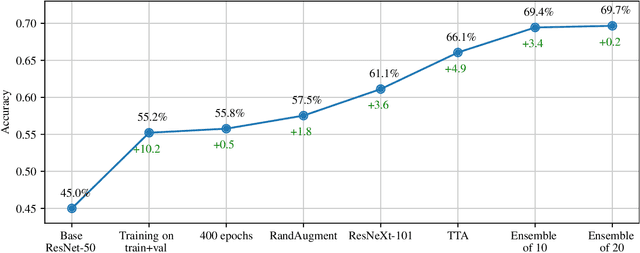
Learning from limited amounts of data is the hallmark of intelligence, requiring strong generalization and abstraction skills. In a machine learning context, data-efficient methods are of high practical importance since data collection and annotation are prohibitively expensive in many domains. Thus, coordinated efforts to foster progress in this area emerged recently, e.g., in the form of dedicated workshops and competitions. Besides a common benchmark, measuring progress requires strong baselines. We present such a strong baseline for data-efficient image classification on the VIPriors challenge dataset, which is a sub-sampled version of ImageNet-1k with 100 images per class. We do not use any methods tailored to data-efficient classification but only standard models and techniques as well as common competition tricks and thorough hyper-parameter tuning. Our baseline achieves 69.7% accuracy on the VIPriors image classification dataset and outperforms 50% of submissions to the VIPriors 2021 challenge.
Tune It or Don't Use It: Benchmarking Data-Efficient Image Classification
Aug 30, 2021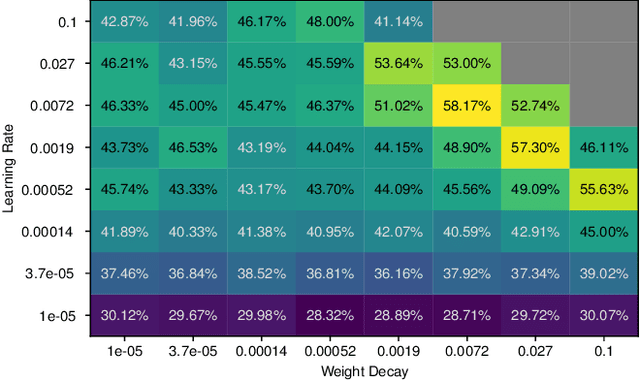

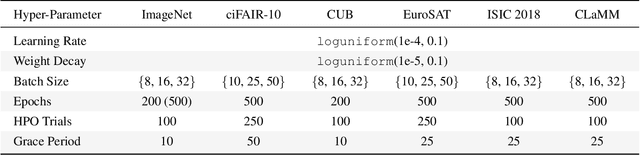
Data-efficient image classification using deep neural networks in settings, where only small amounts of labeled data are available, has been an active research area in the recent past. However, an objective comparison between published methods is difficult, since existing works use different datasets for evaluation and often compare against untuned baselines with default hyper-parameters. We design a benchmark for data-efficient image classification consisting of six diverse datasets spanning various domains (e.g., natural images, medical imagery, satellite data) and data types (RGB, grayscale, multispectral). Using this benchmark, we re-evaluate the standard cross-entropy baseline and eight methods for data-efficient deep learning published between 2017 and 2021 at renowned venues. For a fair and realistic comparison, we carefully tune the hyper-parameters of all methods on each dataset. Surprisingly, we find that tuning learning rate, weight decay, and batch size on a separate validation split results in a highly competitive baseline, which outperforms all but one specialized method and performs competitively to the remaining one.
A Reinforcement Learning Environment for Multi-Service UAV-enabled Wireless Systems
May 11, 2021
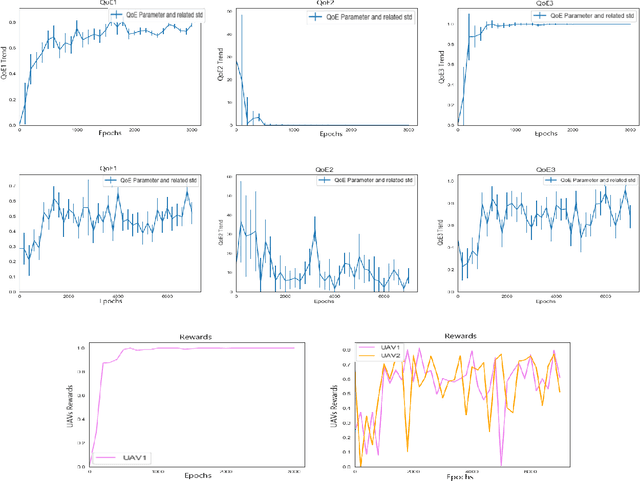


We design a multi-purpose environment for autonomous UAVs offering different communication services in a variety of application contexts (e.g., wireless mobile connectivity services, edge computing, data gathering). We develop the environment, based on OpenAI Gym framework, in order to simulate different characteristics of real operational environments and we adopt the Reinforcement Learning to generate policies that maximize some desired performance.The quality of the resulting policies are compared with a simple baseline to evaluate the system and derive guidelines to adopt this technique in different use cases. The main contribution of this paper is a flexible and extensible OpenAI Gym environment, which allows to generate, evaluate, and compare policies for autonomous multi-drone systems in multi-service applications. This environment allows for comparative evaluation and benchmarking of different approaches in a variety of application contexts.
Proceedings of the AI-HRI Symposium at AAAI-FSS 2019
Sep 19, 2019The past few years have seen rapid progress in the development of service robots. Universities and companies alike have launched major research efforts toward the deployment of ambitious systems designed to aid human operators performing a variety of tasks. These robots are intended to make those who may otherwise need to live in assisted care facilities more independent, to help workers perform their jobs, or simply to make life more convenient. Service robots provide a powerful platform on which to study Artificial Intelligence (AI) and Human-Robot Interaction (HRI) in the real world. Research sitting at the intersection of AI and HRI is crucial to the success of service robots if they are to fulfill their mission. This symposium seeks to highlight research enabling robots to effectively interact with people autonomously while modeling, planning, and reasoning about the environment that the robot operates in and the tasks that it must perform. AI-HRI deals with the challenge of interacting with humans in environments that are relatively unstructured or which are structured around people rather than machines, as well as the possibility that the robot may need to interact naturally with people rather than through teach pendants, programming, or similar interfaces.
Proceedings of the AI-HRI Symposium at AAAI-FSS 2018
Sep 18, 2018The goal of the Interactive Learning for Artificial Intelligence (AI) for Human-Robot Interaction (HRI) symposium is to bring together the large community of researchers working on interactive learning scenarios for interactive robotics. While current HRI research involves investigating ways for robots to effectively interact with people, HRI's overarching goal is to develop robots that are autonomous while intelligently modeling and learning from humans. These goals greatly overlap with some central goals of AI and interactive machine learning, such that HRI is an extremely challenging problem domain for interactive learning and will elicit fresh problem areas for robotics research. Present-day AI research still does not widely consider situations for interacting directly with humans and within human-populated environments, which present inherent uncertainty in dynamics, structure, and interaction. We believe that the HRI community already offers a rich set of principles and observations that can be used to structure new models of interaction. The human-aware AI initiative has primarily been approached through human-in-the-loop methods that use people's data and feedback to improve refinement and performance of the algorithms, learned functions, and personalization. We thus believe that HRI is an important component to furthering AI and robotics research.
Reinforcement Learning for LTLf/LDLf Goals
Jul 17, 2018



MDPs extended with LTLf/LDLf non-Markovian rewards have recently attracted interest as a way to specify rewards declaratively. In this paper, we discuss how a reinforcement learning agent can learn policies fulfilling LTLf/LDLf goals. In particular we focus on the case where we have two separate representations of the world: one for the agent, using the (predefined, possibly low-level) features available to it, and one for the goal, expressed in terms of high-level (human-understandable) fluents. We formally define the problem and show how it can be solved. Moreover, we provide experimental evidence that keeping the RL agent feature space separated from the goal's can work in practice, showing interesting cases where the agent can indeed learn a policy that fulfills the LTLf/LDLf goal using only its features (augmented with additional memory).