 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-Robot Motion Planning with Precomputed Translation-Invariant Edge Bundles
May 10, 2026Solving multi-robot motion planning (MRMP) requires generating collision-free kinodynamically feasible trajectories for multiple interacting robots. We introduce Kinodynamic Translation-Invariant Edge Bundles or KiTE-Extend, a planner-agnostic action selection mechanism for sampling-based kinodynamic motion planning. KiTE-Extend uses a library of trajectory segments computed offline to guide action selection during online planning, improving the ability of existing planners to identify feasible motion segments without altering state propagation, collision checking, or cost evaluation, and without changing their theoretical guarantees. While KiTE-Extend can modestly improve single-agent planners, its benefits are most clear in the multi-agent setting, where it is able to explore more effectively and significantly improve planning through the dense spatiotemporal constraints introduced by robot-robot interaction. Through experiments on multiple kinodynamic systems and environments, we show that KiTE-Extend reduces planning time and improves scalability across the three most common MRMP paradigms: centralized, prioritized, and conflict-based.
CRED: Counterfactual Reasoning and Environment Design for Active Preference Learning
Mar 09, 2026As a robot's operational environment and tasks to perform within it grow in complexity, the explicit specification and balancing of optimization objectives to achieve a preferred behavior profile moves increasingly farther out of reach. These systems benefit strongly by being able to align their behavior to reflect human preferences and respond to corrections, but manually encoding this feedback is infeasible. Active preference learning (APL) learns human reward functions by presenting trajectories for ranking. However, existing methods sample from fixed trajectory sets or replay buffers that limit query diversity and often fail to identify informative comparisons. We propose CRED, a novel trajectory generation method for APL that improves reward inference by jointly optimizing environment design and trajectory selection to efficiently query and extract preferences from users. CRED "imagines" new scenarios through environment design and leverages counterfactual reasoning -- by sampling possible rewards from its current belief and asking "What if this were the true preference?" -- to generate trajectory pairs that expose differences between competing reward functions. Comprehensive experiments and a user study show that CRED significantly outperforms state-of-the-art methods in reward accuracy and sample efficiency and receives higher user ratings.
RF-Modulated Adaptive Communication Improves Multi-Agent Robotic Exploration
Feb 12, 2026Reliable coordination and efficient communication are critical challenges for multi-agent robotic exploration of environments where communication is limited. This work introduces Adaptive-RF Transmission (ART), a novel communication-aware planning algorithm that dynamically modulates transmission location based on signal strength and data payload size, enabling heterogeneous robot teams to share information efficiently without unnecessary backtracking. We further explore an extension to this approach called ART-SST, which enforces signal strength thresholds for high-fidelity data delivery. Through over 480 simulations across three cave-inspired environments, ART consistently outperforms existing strategies, including full rendezvous and minimum-signal heuristic approaches, achieving up to a 58% reduction in distance traveled and up to 52% faster exploration times compared to baseline methods. These results demonstrate that adaptive, payload-aware communication significantly improves coverage efficiency and mission speed in complex, communication-constrained environments, offering a promising foundation for future planetary exploration and search-and-rescue missions.
ShelfAware: Real-Time Visual-Inertial Semantic Localization in Quasi-Static Environments with Low-Cost Sensors
Dec 09, 2025Many indoor workspaces are quasi-static: global layout is stable but local semantics change continually, producing repetitive geometry, dynamic clutter, and perceptual noise that defeat vision-based localization. We present ShelfAware, a semantic particle filter for robust global localization that treats scene semantics as statistical evidence over object categories rather than fixed landmarks. ShelfAware fuses a depth likelihood with a category-centric semantic similarity and uses a precomputed bank of semantic viewpoints to perform inverse semantic proposals inside MCL, yielding fast, targeted hypothesis generation on low-cost, vision-only hardware. Across 100 global-localization trials spanning four conditions (cart-mounted, wearable, dynamic obstacles, and sparse semantics) in a semantically dense, retail environment, ShelfAware achieves a 96% success rate (vs. 22% MCL and 10% AMCL) with a mean time-to-convergence of 1.91s, attains the lowest translational RMSE in all conditions, and maintains stable tracking in 80% of tested sequences, all while running in real time on a consumer laptop-class platform. By modeling semantics distributionally at the category level and leveraging inverse proposals, ShelfAware resolves geometric aliasing and semantic drift common to quasi-static domains. Because the method requires only vision sensors and VIO, it integrates as an infrastructure-free building block for mobile robots in warehouses, labs, and retail settings; as a representative application, it also supports the creation of assistive devices providing start-anytime, shared-control assistive navigation for people with visual impairments.
Employing Laban Shape for Generating Emotionally and Functionally Expressive Trajectories in Robotic Manipulators
May 16, 2025Successful human-robot collaboration depends on cohesive communication and a precise understanding of the robot's abilities, goals, and constraints. While robotic manipulators offer high precision, versatility, and productivity, they exhibit expressionless and monotonous motions that conceal the robot's intention, resulting in a lack of efficiency and transparency with humans. In this work, we use Laban notation, a dance annotation language, to enable robotic manipulators to generate trajectories with functional expressivity, where the robot uses nonverbal cues to communicate its abilities and the likelihood of succeeding at its task. We achieve this by introducing two novel variants of Hesitant expressive motion (Spoke-Like and Arc-Like). We also enhance the emotional expressivity of four existing emotive trajectories (Happy, Sad, Shy, and Angry) by augmenting Laban Effort usage with Laban Shape. The functionally expressive motions are validated via a human-subjects study, where participants equate both variants of Hesitant motion with reduced robot competency. The enhanced emotive trajectories are shown to be viewed as distinct emotions using the Valence-Arousal-Dominance (VAD) spectrum, corroborating the usage of Laban Shape.
Online Diffusion-Based 3D Occupancy Prediction at the Frontier with Probabilistic Map Reconciliation
Sep 16, 2024
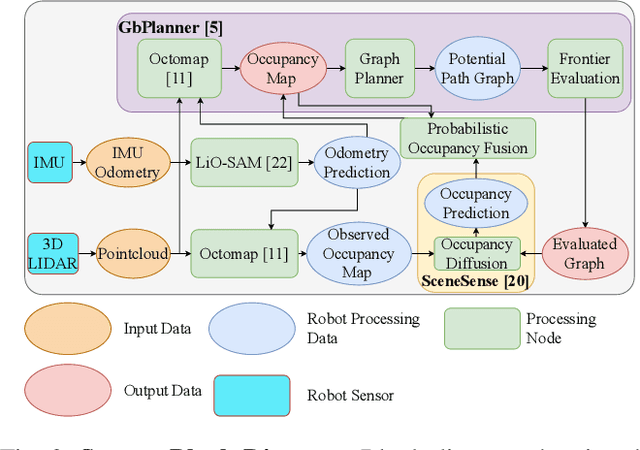
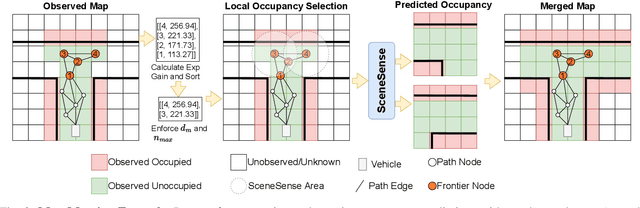
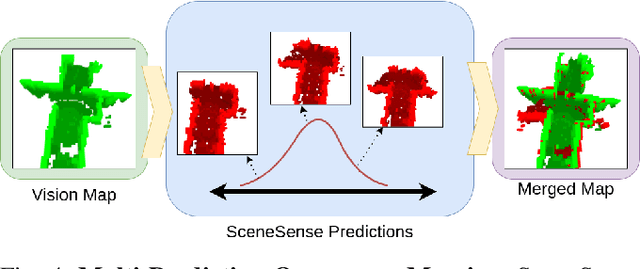
Autonomous navigation and exploration in unmapped environments remains a significant challenge in robotics due to the difficulty robots face in making commonsense inference of unobserved geometries. Recent advancements have demonstrated that generative modeling techniques, particularly diffusion models, can enable systems to infer these geometries from partial observation. In this work, we present implementation details and results for real-time, online occupancy prediction using a modified diffusion model. By removing attention-based visual conditioning and visual feature extraction components, we achieve a 73$\%$ reduction in runtime with minimal accuracy reduction. These modifications enable occupancy prediction across the entire map, rather than being limited to the area around the robot where camera data can be collected. We introduce a probabilistic update method for merging predicted occupancy data into running occupancy maps, resulting in a 71$\%$ improvement in predicting occupancy at map frontiers compared to previous methods. Finally, we release our code and a ROS node for on-robot operation <upon publication> at github.com/arpg/sceneSense_ws.
ShelfHelp: Empowering Humans to Perform Vision-Independent Manipulation Tasks with a Socially Assistive Robotic Cane
May 30, 2024The ability to shop independently, especially in grocery stores, is important for maintaining a high quality of life. This can be particularly challenging for people with visual impairments (PVI). Stores carry thousands of products, with approximately 30,000 new products introduced each year in the US market alone, presenting a challenge even for modern computer vision solutions. Through this work, we present a proof-of-concept socially assistive robotic system we call ShelfHelp, and propose novel technical solutions for enhancing instrumented canes traditionally meant for navigation tasks with additional capability within the domain of shopping. ShelfHelp includes a novel visual product locator algorithm designed for use in grocery stores and a novel planner that autonomously issues verbal manipulation guidance commands to guide the user during product retrieval. Through a human subjects study, we show the system's success in locating and providing effective manipulation guidance to retrieve desired products with novice users. We compare two autonomous verbal guidance modes achieving comparable performance to a human assistance baseline and present encouraging findings that validate our system's efficiency and effectiveness and through positive subjective metrics including competence, intelligence, and ease of use.
* 8 pages, 14 figures and charts
Large Language Models Enable Automated Formative Feedback in Human-Robot Interaction Tasks
May 25, 2024We claim that LLMs can be paired with formal analysis methods to provide accessible, relevant feedback for HRI tasks. While logic specifications are useful for defining and assessing a task, these representations are not easily interpreted by non-experts. Luckily, LLMs are adept at generating easy-to-understand text that explains difficult concepts. By integrating task assessment outcomes and other contextual information into an LLM prompt, we can effectively synthesize a useful set of recommendations for the learner to improve their performance.
Automated Assessment and Adaptive Multimodal Formative Feedback Improves Psychomotor Skills Training Outcomes in Quadrotor Teleoperation
May 24, 2024The workforce will need to continually upskill in order to meet the evolving demands of industry, especially working with robotic and autonomous systems. Current training methods are not scalable and do not adapt to the skills that learners already possess. In this work, we develop a system that automatically assesses learner skill in a quadrotor teleoperation task using temporal logic task specifications. This assessment is used to generate multimodal feedback based on the principles of effective formative feedback. Participants perceived the feedback positively. Those receiving formative feedback viewed the feedback as more actionable compared to receiving summary statistics. Participants in the multimodal feedback condition were more likely to achieve a safe landing and increased their safe landings more over the experiment compared to other feedback conditions. Finally, we identify themes to improve adaptive feedback and discuss and how training for complex psychomotor tasks can be integrated with learning theories.
SceneSense: Diffusion Models for 3D Occupancy Synthesis from Partial Observation
Mar 18, 2024
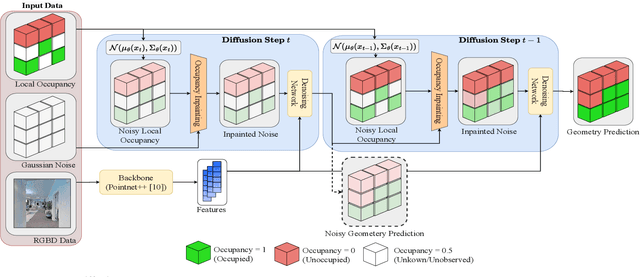
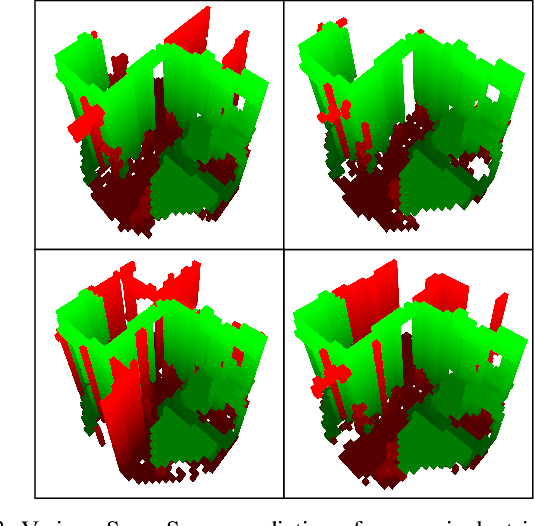

When exploring new areas, robotic systems generally exclusively plan and execute controls over geometry that has been directly measured. When entering space that was previously obstructed from view such as turning corners in hallways or entering new rooms, robots often pause to plan over the newly observed space. To address this we present SceneScene, a real-time 3D diffusion model for synthesizing 3D occupancy information from partial observations that effectively predicts these occluded or out of view geometries for use in future planning and control frameworks. SceneSense uses a running occupancy map and a single RGB-D camera to generate predicted geometry around the platform at runtime, even when the geometry is occluded or out of view. Our architecture ensures that SceneSense never overwrites observed free or occupied space. By preserving the integrity of the observed map, SceneSense mitigates the risk of corrupting the observed space with generative predictions. While SceneSense is shown to operate well using a single RGB-D camera, the framework is flexible enough to extend to additional modalities. SceneSense operates as part of any system that generates a running occupancy map `out of the box', removing conditioning from the framework. Alternatively, for maximum performance in new modalities, the perception backbone can be replaced and the model retrained for inference in new applications. Unlike existing models that necessitate multiple views and offline scene synthesis, or are focused on filling gaps in observed data, our findings demonstrate that SceneSense is an effective approach to estimating unobserved local occupancy information at runtime. Local occupancy predictions from SceneSense are shown to better represent the ground truth occupancy distribution during the test exploration trajectories than the running occupancy map.