 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCU-Multi: A Dataset for Multi-Robot Data Association
May 23, 2025Multi-robot systems (MRSs) are valuable for tasks such as search and rescue due to their ability to coordinate over shared observations. A central challenge in these systems is aligning independently collected perception data across space and time, i.e., multi-robot data association. While recent advances in collaborative SLAM (C-SLAM), map merging, and inter-robot loop closure detection have significantly progressed the field, evaluation strategies still predominantly rely on splitting a single trajectory from single-robot SLAM datasets into multiple segments to simulate multiple robots. Without careful consideration to how a single trajectory is split, this approach will fail to capture realistic pose-dependent variation in observations of a scene inherent to multi-robot systems. To address this gap, we present CU-Multi, a multi-robot dataset collected over multiple days at two locations on the University of Colorado Boulder campus. Using a single robotic platform, we generate four synchronized runs with aligned start times and deliberate percentages of trajectory overlap. CU-Multi includes RGB-D, GPS with accurate geospatial heading, and semantically annotated LiDAR data. By introducing controlled variations in trajectory overlap and dense lidar annotations, CU-Multi offers a compelling alternative for evaluating methods in multi-robot data association. Instructions on accessing the dataset, support code, and the latest updates are publicly available at https://arpg.github.io/cumulti
Spatial-LLaVA: Enhancing Large Language Models with Spatial Referring Expressions for Visual Understanding
May 18, 2025Multimodal large language models (MLLMs) have demonstrated remarkable abilities in comprehending visual input alongside text input. Typically, these models are trained on extensive data sourced from the internet, which are sufficient for general tasks such as scene understanding and question answering. However, they often underperform on specialized tasks where online data is scarce, such as determining spatial relationships between objects or localizing unique target objects within a group of objects sharing similar features. In response to this challenge, we introduce the SUN-Spot v2.0 dataset1, now comprising a total of 90k image-caption pairs and additional annotations on the landmark objects. Each image-caption pair utilizes Set-of-Marks prompting as an additional indicator, mapping each landmark object in the image to the corresponding object mentioned in the caption. Furthermore, we present Spatial-LLaVA, an MLLM trained on conversational data generated by a state-of-the-art language model using the SUNSpot v2.0 dataset. Our approach ensures a robust alignment between the objects in the images and their corresponding object mentions in the captions, enabling our model to learn spatial referring expressions without bias from the semantic information of the objects. Spatial-LLaVA outperforms previous methods by 3.15% on the zero-shot Visual Spatial Reasoning benchmark dataset. Spatial-LLaVA is specifically designed to precisely understand spatial referring expressions, making it highly applicable for tasks in real-world scenarios such as autonomous navigation and interactive robotics, where precise object recognition is critical.
CogExplore: Contextual Exploration with Language-Encoded Environment Representations
Jun 24, 2024
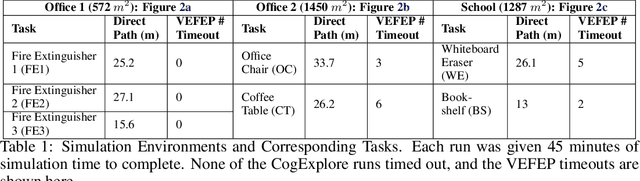

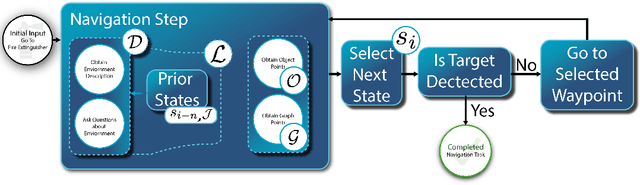
Integrating language models into robotic exploration frameworks improves performance in unmapped environments by providing the ability to reason over semantic groundings, contextual cues, and temporal states. The proposed method employs large language models (GPT-3.5 and Claude Haiku) to reason over these cues and express that reasoning in terms of natural language, which can be used to inform future states. We are motivated by the context of search-and-rescue applications where efficient exploration is critical. We find that by leveraging natural language, semantics, and tracking temporal states, the proposed method greatly reduces exploration path distance and further exposes the need for environment-dependent heuristics. Moreover, the method is highly robust to a variety of environments and noisy vision detections, as shown with a 100% success rate in a series of comprehensive experiments across three different environments conducted in a custom simulation pipeline operating in Unreal Engine.
SceneSense: Diffusion Models for 3D Occupancy Synthesis from Partial Observation
Mar 18, 2024
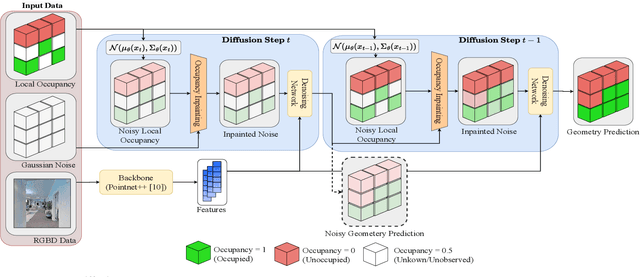
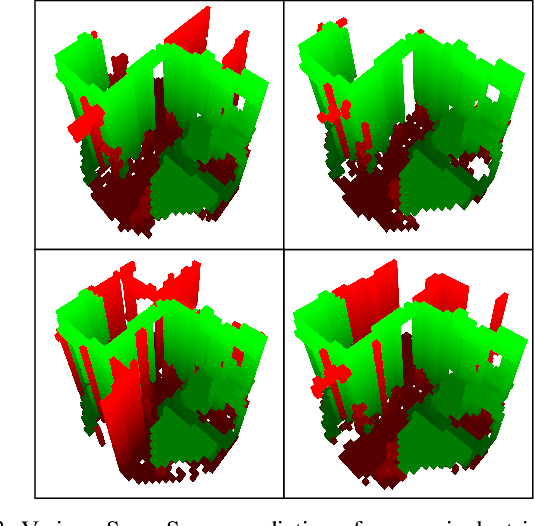

When exploring new areas, robotic systems generally exclusively plan and execute controls over geometry that has been directly measured. When entering space that was previously obstructed from view such as turning corners in hallways or entering new rooms, robots often pause to plan over the newly observed space. To address this we present SceneScene, a real-time 3D diffusion model for synthesizing 3D occupancy information from partial observations that effectively predicts these occluded or out of view geometries for use in future planning and control frameworks. SceneSense uses a running occupancy map and a single RGB-D camera to generate predicted geometry around the platform at runtime, even when the geometry is occluded or out of view. Our architecture ensures that SceneSense never overwrites observed free or occupied space. By preserving the integrity of the observed map, SceneSense mitigates the risk of corrupting the observed space with generative predictions. While SceneSense is shown to operate well using a single RGB-D camera, the framework is flexible enough to extend to additional modalities. SceneSense operates as part of any system that generates a running occupancy map `out of the box', removing conditioning from the framework. Alternatively, for maximum performance in new modalities, the perception backbone can be replaced and the model retrained for inference in new applications. Unlike existing models that necessitate multiple views and offline scene synthesis, or are focused on filling gaps in observed data, our findings demonstrate that SceneSense is an effective approach to estimating unobserved local occupancy information at runtime. Local occupancy predictions from SceneSense are shown to better represent the ground truth occupancy distribution during the test exploration trajectories than the running occupancy map.