 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Diffusion-Based 3D Occupancy Prediction at the Frontier with Probabilistic Map Reconciliation
Sep 16, 2024
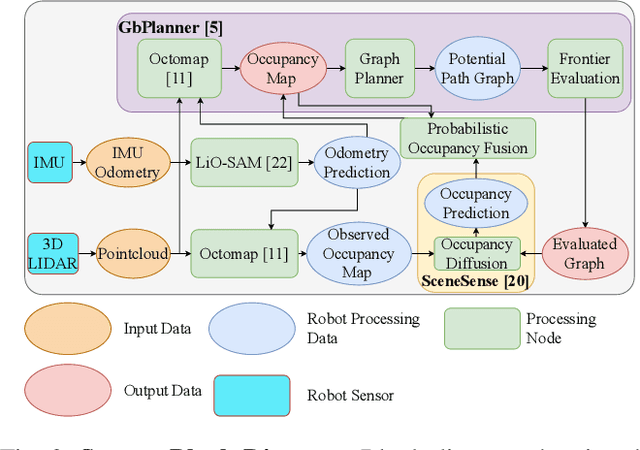
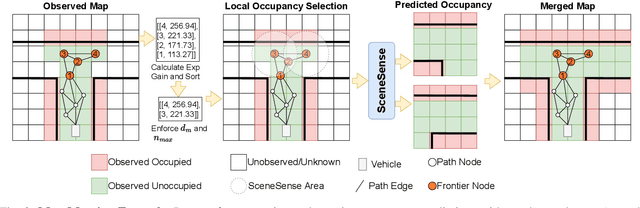
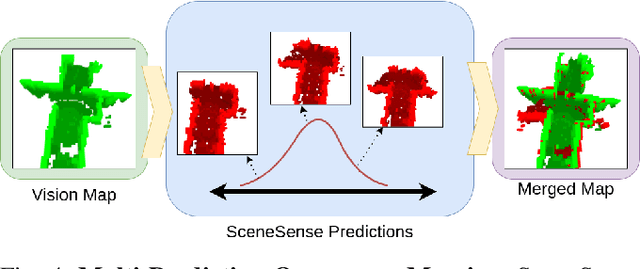
Autonomous navigation and exploration in unmapped environments remains a significant challenge in robotics due to the difficulty robots face in making commonsense inference of unobserved geometries. Recent advancements have demonstrated that generative modeling techniques, particularly diffusion models, can enable systems to infer these geometries from partial observation. In this work, we present implementation details and results for real-time, online occupancy prediction using a modified diffusion model. By removing attention-based visual conditioning and visual feature extraction components, we achieve a 73$\%$ reduction in runtime with minimal accuracy reduction. These modifications enable occupancy prediction across the entire map, rather than being limited to the area around the robot where camera data can be collected. We introduce a probabilistic update method for merging predicted occupancy data into running occupancy maps, resulting in a 71$\%$ improvement in predicting occupancy at map frontiers compared to previous methods. Finally, we release our code and a ROS node for on-robot operation <upon publication> at github.com/arpg/sceneSense_ws.
SceneSense: Diffusion Models for 3D Occupancy Synthesis from Partial Observation
Mar 18, 2024
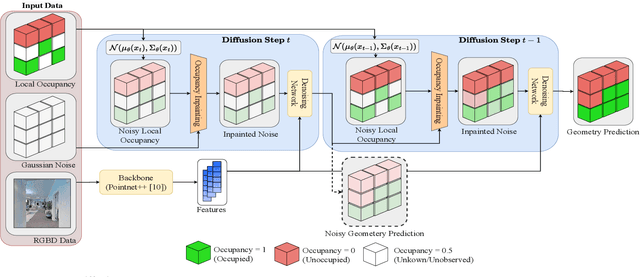
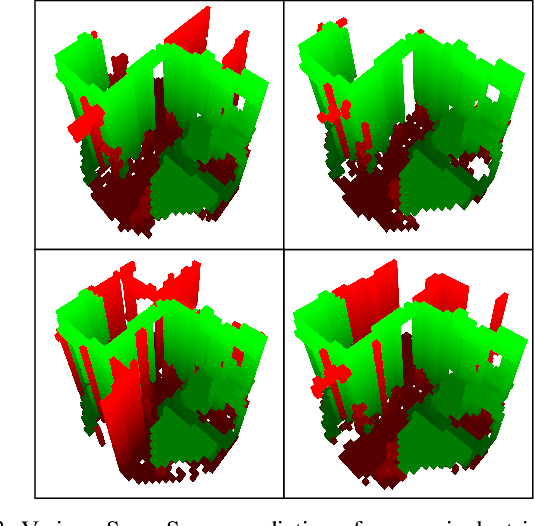

When exploring new areas, robotic systems generally exclusively plan and execute controls over geometry that has been directly measured. When entering space that was previously obstructed from view such as turning corners in hallways or entering new rooms, robots often pause to plan over the newly observed space. To address this we present SceneScene, a real-time 3D diffusion model for synthesizing 3D occupancy information from partial observations that effectively predicts these occluded or out of view geometries for use in future planning and control frameworks. SceneSense uses a running occupancy map and a single RGB-D camera to generate predicted geometry around the platform at runtime, even when the geometry is occluded or out of view. Our architecture ensures that SceneSense never overwrites observed free or occupied space. By preserving the integrity of the observed map, SceneSense mitigates the risk of corrupting the observed space with generative predictions. While SceneSense is shown to operate well using a single RGB-D camera, the framework is flexible enough to extend to additional modalities. SceneSense operates as part of any system that generates a running occupancy map `out of the box', removing conditioning from the framework. Alternatively, for maximum performance in new modalities, the perception backbone can be replaced and the model retrained for inference in new applications. Unlike existing models that necessitate multiple views and offline scene synthesis, or are focused on filling gaps in observed data, our findings demonstrate that SceneSense is an effective approach to estimating unobserved local occupancy information at runtime. Local occupancy predictions from SceneSense are shown to better represent the ground truth occupancy distribution during the test exploration trajectories than the running occupancy map.
Looking Around Corners: Generative Methods in Terrain Extension
Jun 12, 2023

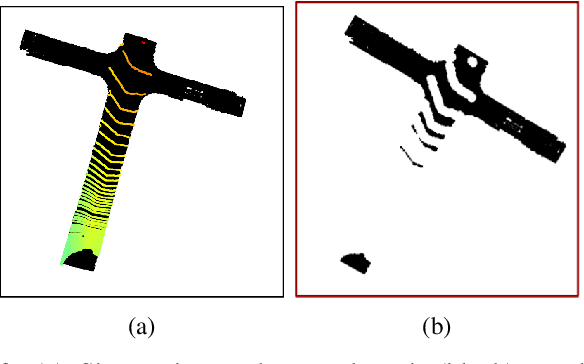
In this paper, we provide an early look at our model for generating terrain that is occluded in the initial lidar scan or out of range of the sensor. As a proof of concept, we show that a transformer based framework is able to be overfit to predict the geometries of unobserved roads around intersections or corners. We discuss our method for generating training data, as well as a unique loss function for training our terrain extension network. The framework is tested on data from the SemanticKitti [1] dataset. Unlabeled point clouds measured from an onboard lidar are used as input data to generate predicted road points that are out of range or occluded in the original point-cloud scan. Then the input pointcloud and predicted terrain are concatenated to the terrain-extended pointcloud. We show promising qualitative results from these methods, as well as discussion for potential quantitative metrics to evaluate the overall success of our framework. Finally, we discuss improvements that can be made to the framework for successful generalization to test sets.