 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBelief Consistency Between Foundation-Model Evidence and Geometric Perception in Persistent Robotic Maps
May 29, 2026Persistent maps used by autonomous robots increasingly fuse a geometric perception stack whose assertions are well-characterized with a foundation-model channel that produces semantic claims without calibrated reliability about the same scene. Contemporary mapping systems integrate the two channels by treating the foundation-model channel as an additional voter into a per-element posterior, uncalibrated for its own per-class reliability and without machinery to flag when the two channels contradict each other at a given moment. We propose an update operator with two cooperating mechanisms: a per-class calibrated commit gate, and a per-event conflict-drop window that refuses to commit foundation-model claims contradicted by the geometric channel at the moment of the claim. We evaluate on KITTI-360 and ScanNet, with an oracle geometric channel (panoptic ground truth) and an off-the-shelf online semantic segmenter (Mask2Former) to demonstrate real-world performance. The operator produces substantially more accurate committed maps (KITTI is car commit precision 99.7% vs. 43.9% for the calibration-only operator; mean per-class IoU 0.522 vs. 0.180), retains more compositional true positives at higher precision than a monolithic compositional VLM prompt. The framework operates at deployment quality across both oracle and off-the-shelf-segmenter geometric channels, and is invariant under foundation-model substitution.
SceneGraphGrounder: Zero-Shot 3D Visual Grounding via Structured Scene Graph Matching
May 20, 2026Zero-shot 3D visual grounding requires localizing objects in unstructured environments from free-form natural language. Recent vision-language model (VLM) approaches achieve promising results but rely on view-dependent reasoning or implicit representations, limiting spatial consistency and interpretability for compositional queries. We propose SceneGraphGrounder, a framework that reformulates 3D grounding as structured graph matching over a reconstructed 3D scene graph. To enable this formulation, we introduce a visual marker prompting strategy that enables a VLM to infer object-object relationships from 2D views, which are subsequently lifted into a persistent 3D scene graph encoding both spatial and semantic relations. Given a query, we construct a query graph and perform constrained alignment with the scene graph, ensuring multi-view consistency and interpretable reasoning. Experiments on the ScanRefer benchmark demonstrate that our method achieves competitive performance among zero-shot approaches, using only RGB-D inputs. We further validate our framework through real-world deployment on a mobile robot, demonstrating robust spatial reasoning in long-horizon physical environments. We will make our code publicly available upon acceptance.
RF-Modulated Adaptive Communication Improves Multi-Agent Robotic Exploration
Feb 12, 2026Reliable coordination and efficient communication are critical challenges for multi-agent robotic exploration of environments where communication is limited. This work introduces Adaptive-RF Transmission (ART), a novel communication-aware planning algorithm that dynamically modulates transmission location based on signal strength and data payload size, enabling heterogeneous robot teams to share information efficiently without unnecessary backtracking. We further explore an extension to this approach called ART-SST, which enforces signal strength thresholds for high-fidelity data delivery. Through over 480 simulations across three cave-inspired environments, ART consistently outperforms existing strategies, including full rendezvous and minimum-signal heuristic approaches, achieving up to a 58% reduction in distance traveled and up to 52% faster exploration times compared to baseline methods. These results demonstrate that adaptive, payload-aware communication significantly improves coverage efficiency and mission speed in complex, communication-constrained environments, offering a promising foundation for future planetary exploration and search-and-rescue missions.
Cost-Effective Radar Sensors for Field-Based Water Level Monitoring with Sub-Centimeter Accuracy
Jan 06, 2026Water level monitoring is critical for flood management, water resource allocation, and ecological assessment, yet traditional methods remain costly and limited in coverage. This work explores radar-based sensing as a low-cost alternative for water level estimation, leveraging its non-contact nature and robustness to environmental conditions. Commercial radar sensors are evaluated in real-world field tests, applying statistical filtering techniques to improve accuracy. Results show that a single radar sensor can achieve centimeter-scale precision with minimal calibration, making it a practical solution for autonomous water monitoring using drones and robotic platforms.
CU-Multi: A Dataset for Multi-Robot Data Association
May 23, 2025



Multi-robot systems (MRSs) are valuable for tasks such as search and rescue due to their ability to coordinate over shared observations. A central challenge in these systems is aligning independently collected perception data across space and time, i.e., multi-robot data association. While recent advances in collaborative SLAM (C-SLAM), map merging, and inter-robot loop closure detection have significantly progressed the field, evaluation strategies still predominantly rely on splitting a single trajectory from single-robot SLAM datasets into multiple segments to simulate multiple robots. Without careful consideration to how a single trajectory is split, this approach will fail to capture realistic pose-dependent variation in observations of a scene inherent to multi-robot systems. To address this gap, we present CU-Multi, a multi-robot dataset collected over multiple days at two locations on the University of Colorado Boulder campus. Using a single robotic platform, we generate four synchronized runs with aligned start times and deliberate percentages of trajectory overlap. CU-Multi includes RGB-D, GPS with accurate geospatial heading, and semantically annotated LiDAR data. By introducing controlled variations in trajectory overlap and dense lidar annotations, CU-Multi offers a compelling alternative for evaluating methods in multi-robot data association. Instructions on accessing the dataset, support code, and the latest updates are publicly available at https://arpg.github.io/cumulti
Spatial-LLaVA: Enhancing Large Language Models with Spatial Referring Expressions for Visual Understanding
May 18, 2025Multimodal large language models (MLLMs) have demonstrated remarkable abilities in comprehending visual input alongside text input. Typically, these models are trained on extensive data sourced from the internet, which are sufficient for general tasks such as scene understanding and question answering. However, they often underperform on specialized tasks where online data is scarce, such as determining spatial relationships between objects or localizing unique target objects within a group of objects sharing similar features. In response to this challenge, we introduce the SUN-Spot v2.0 dataset1, now comprising a total of 90k image-caption pairs and additional annotations on the landmark objects. Each image-caption pair utilizes Set-of-Marks prompting as an additional indicator, mapping each landmark object in the image to the corresponding object mentioned in the caption. Furthermore, we present Spatial-LLaVA, an MLLM trained on conversational data generated by a state-of-the-art language model using the SUNSpot v2.0 dataset. Our approach ensures a robust alignment between the objects in the images and their corresponding object mentions in the captions, enabling our model to learn spatial referring expressions without bias from the semantic information of the objects. Spatial-LLaVA outperforms previous methods by 3.15% on the zero-shot Visual Spatial Reasoning benchmark dataset. Spatial-LLaVA is specifically designed to precisely understand spatial referring expressions, making it highly applicable for tasks in real-world scenarios such as autonomous navigation and interactive robotics, where precise object recognition is critical.
Foundation Models for Rapid Autonomy Validation
Oct 22, 2024



We are motivated by the problem of autonomous vehicle performance validation. A key challenge is that an autonomous vehicle requires testing in every kind of driving scenario it could encounter, including rare events, to provide a strong case for safety and show there is no edge-case pathological behavior. Autonomous vehicle companies rely on potentially millions of miles driven in realistic simulation to expose the driving stack to enough miles to estimate rates and severity of collisions. To address scalability and coverage, we propose the use of a behavior foundation model, specifically a masked autoencoder (MAE), trained to reconstruct driving scenarios. We leverage the foundation model in two complementary ways: we (i) use the learned embedding space to group qualitatively similar scenarios together and (ii) fine-tune the model to label scenario difficulty based on the likelihood of a collision upon re-simulation. We use the difficulty scoring as importance weighting for the groups of scenarios. The result is an approach which can more rapidly estimate the rates and severity of collisions by prioritizing hard scenarios while ensuring exposure to every kind of driving scenario.
Online Diffusion-Based 3D Occupancy Prediction at the Frontier with Probabilistic Map Reconciliation
Sep 16, 2024
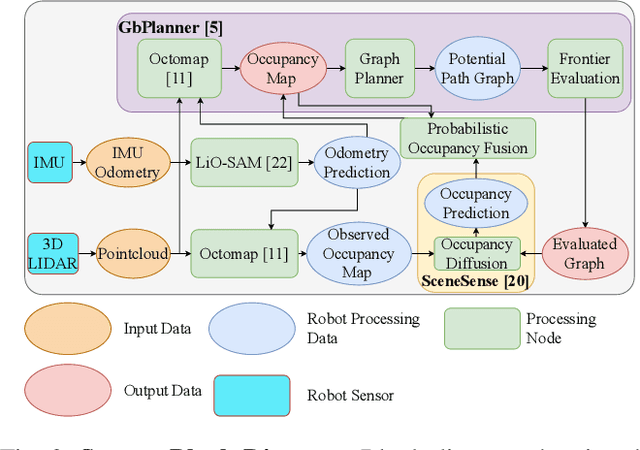
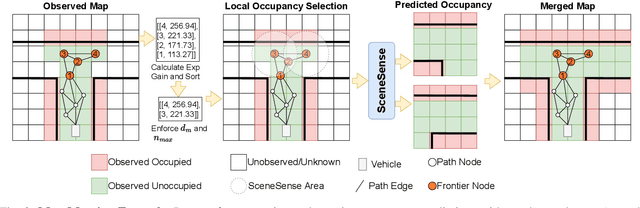
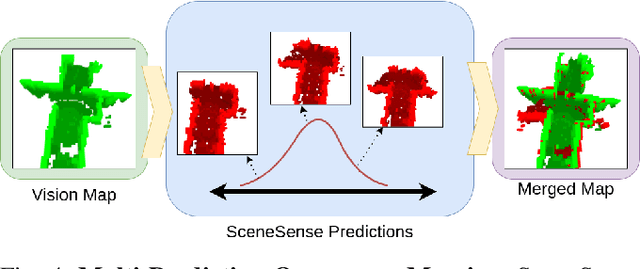
Autonomous navigation and exploration in unmapped environments remains a significant challenge in robotics due to the difficulty robots face in making commonsense inference of unobserved geometries. Recent advancements have demonstrated that generative modeling techniques, particularly diffusion models, can enable systems to infer these geometries from partial observation. In this work, we present implementation details and results for real-time, online occupancy prediction using a modified diffusion model. By removing attention-based visual conditioning and visual feature extraction components, we achieve a 73$\%$ reduction in runtime with minimal accuracy reduction. These modifications enable occupancy prediction across the entire map, rather than being limited to the area around the robot where camera data can be collected. We introduce a probabilistic update method for merging predicted occupancy data into running occupancy maps, resulting in a 71$\%$ improvement in predicting occupancy at map frontiers compared to previous methods. Finally, we release our code and a ROS node for on-robot operation <upon publication> at github.com/arpg/sceneSense_ws.
CogExplore: Contextual Exploration with Language-Encoded Environment Representations
Jun 24, 2024
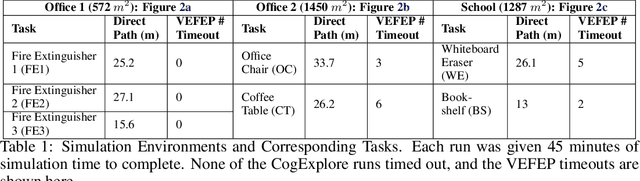

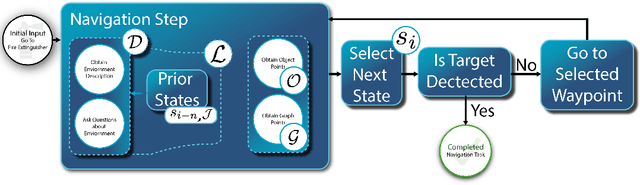
Integrating language models into robotic exploration frameworks improves performance in unmapped environments by providing the ability to reason over semantic groundings, contextual cues, and temporal states. The proposed method employs large language models (GPT-3.5 and Claude Haiku) to reason over these cues and express that reasoning in terms of natural language, which can be used to inform future states. We are motivated by the context of search-and-rescue applications where efficient exploration is critical. We find that by leveraging natural language, semantics, and tracking temporal states, the proposed method greatly reduces exploration path distance and further exposes the need for environment-dependent heuristics. Moreover, the method is highly robust to a variety of environments and noisy vision detections, as shown with a 100% success rate in a series of comprehensive experiments across three different environments conducted in a custom simulation pipeline operating in Unreal Engine.
Radar-Based Localization For Autonomous Ground Vehicles In Suburban Neighborhoods
May 01, 2024For autonomous ground vehicles (AGVs) deployed in suburban neighborhoods and other human-centric environments the problem of localization remains a fundamental challenge. There are well established methods for localization with GPS, lidar, and cameras. But even in ideal conditions these have limitations. GPS is not always available and is often not accurate enough on its own, visual methods have difficulty coping with appearance changes due to weather and other factors, and lidar methods are prone to defective solutions due to ambiguous scene geometry. Radar on the other hand is not highly susceptible to these problems, owing in part to its longer range. Further, radar is also robust to challenging conditions that interfere with vision and lidar including fog, smoke, rain, and darkness. We present a radar-based localization system that includes a novel method for highly-accurate radar odometry for smooth, high-frequency relative pose estimation and a novel method for radar-based place recognition and relocalization. We present experiments demonstrating our methods' accuracy and reliability, which are comparable with \new{other methods' published results for radar localization and we find outperform a similar method as ours applied to lidar measurements}. Further, we show our methods are lightweight enough to run on common low-power embedded hardware with ample headroom for other autonomy functions.