 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Population-Level Analysis of Neural Dynamics in Robust Legged Robots
Jun 27, 2023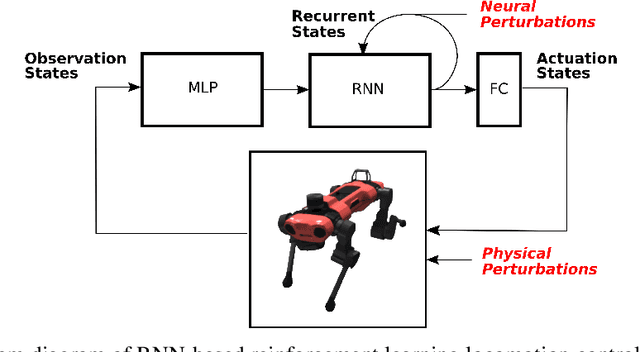
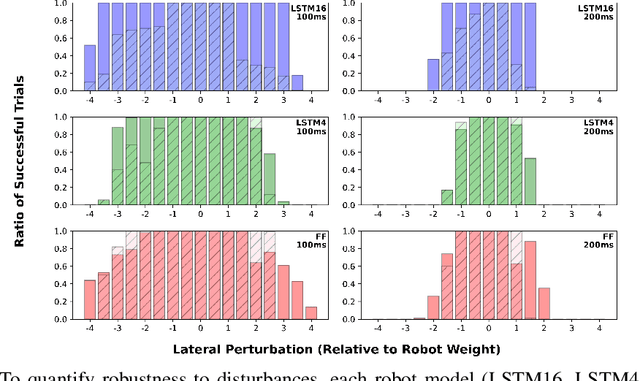
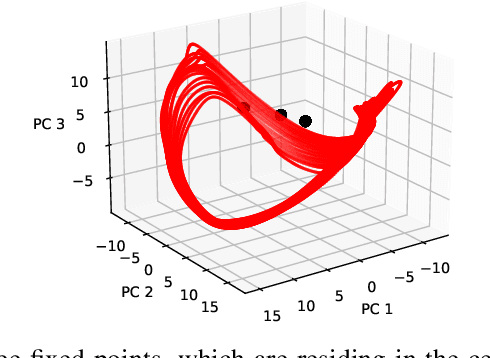
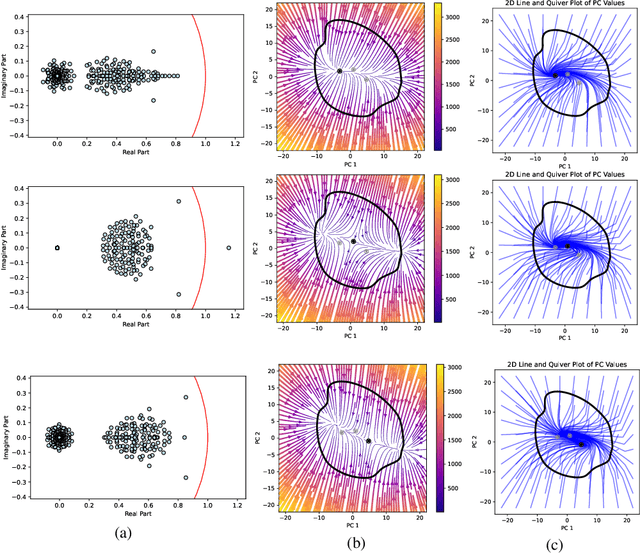
Recurrent neural network-based reinforcement learning systems are capable of complex motor control tasks such as locomotion and manipulation, however, much of their underlying mechanisms still remain difficult to interpret. Our aim is to leverage computational neuroscience methodologies to understanding the population-level activity of robust robot locomotion controllers. Our investigation begins by analyzing topological structure, discovering that fragile controllers have a higher number of fixed points with unstable directions, resulting in poorer balance when instructed to stand in place. Next, we analyze the forced response of the system by applying targeted neural perturbations along directions of dominant population-level activity. We find evidence that recurrent state dynamics are structured and low-dimensional during walking, which aligns with primate studies. Additionally, when recurrent states are perturbed to zero, fragile agents continue to walk, which is indicative of a stronger reliance on sensory input and weaker recurrence.
From Data-Fitting to Discovery: Interpreting the Neural Dynamics of Motor Control through Reinforcement Learning
May 18, 2023



In motor neuroscience, artificial recurrent neural networks models often complement animal studies. However, most modeling efforts are limited to data-fitting, and the few that examine virtual embodied agents in a reinforcement learning context, do not draw direct comparisons to their biological counterparts. Our study addressing this gap, by uncovering structured neural activity of a virtual robot performing legged locomotion that directly support experimental findings of primate walking and cycling. We find that embodied agents trained to walk exhibit smooth dynamics that avoid tangling -- or opposing neural trajectories in neighboring neural space -- a core principle in computational neuroscience. Specifically, across a wide suite of gaits, the agent displays neural trajectories in the recurrent layers are less tangled than those in the input-driven actuation layers. To better interpret the neural separation of these elliptical-shaped trajectories, we identify speed axes that maximizes variance of mean activity across different forward, lateral, and rotational speed conditions.
Flexible Supervised Autonomy for Exploration in Subterranean Environments
Jan 02, 2023



While the capabilities of autonomous systems have been steadily improving in recent years, these systems still struggle to rapidly explore previously unknown environments without the aid of GPS-assisted navigation. The DARPA Subterranean (SubT) Challenge aimed to fast track the development of autonomous exploration systems by evaluating their performance in real-world underground search-and-rescue scenarios. Subterranean environments present a plethora of challenges for robotic systems, such as limited communications, complex topology, visually-degraded sensing, and harsh terrain. The presented solution enables long-term autonomy with minimal human supervision by combining a powerful and independent single-agent autonomy stack, with higher level mission management operating over a flexible mesh network. The autonomy suite deployed on quadruped and wheeled robots was fully independent, freeing the human supervision to loosely supervise the mission and make high-impact strategic decisions. We also discuss lessons learned from fielding our system at the SubT Final Event, relating to vehicle versatility, system adaptability, and re-configurable communications.
Multi-Agent Autonomy: Advancements and Challenges in Subterranean Exploration
Oct 08, 2021
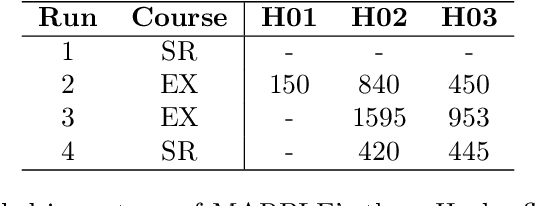
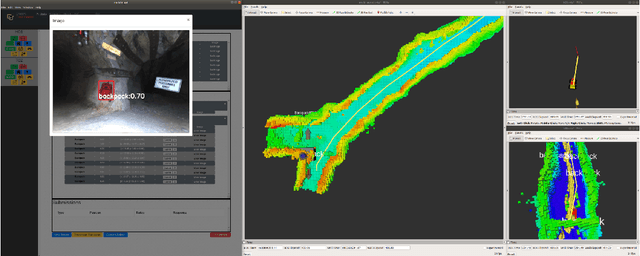
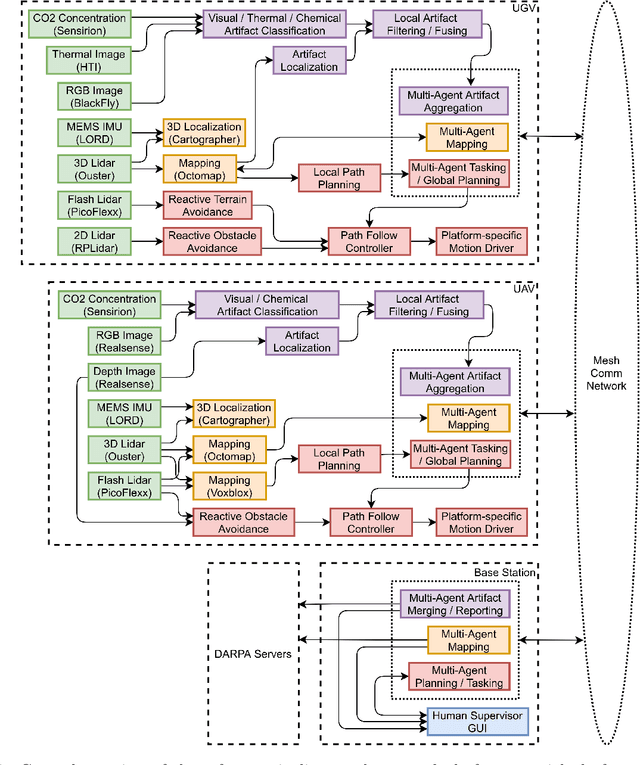
Artificial intelligence has undergone immense growth and maturation in recent years, though autonomous systems have traditionally struggled when fielded in diverse and previously unknown environments. DARPA is seeking to change that with the Subterranean Challenge, by providing roboticists the opportunity to support civilian and military first responders in complex and high-risk underground scenarios. The subterranean domain presents a handful of challenges, such as limited communication, diverse topology and terrain, and degraded sensing. Team MARBLE proposes a solution for autonomous exploration of unknown subterranean environments in which coordinated agents search for artifacts of interest. The team presents two navigation algorithms in the form of a metric-topological graph-based planner and a continuous frontier-based planner. To facilitate multi-agent coordination, agents share and merge new map information and candidate goal-points. Agents deploy communication beacons at different points in the environment, extending the range at which maps and other information can be shared. Onboard autonomy reduces the load on human supervisors, allowing agents to detect and localize artifacts and explore autonomously outside established communication networks. Given the scale, complexity, and tempo of this challenge, a range of lessons were learned, most importantly, that frequent and comprehensive field testing in representative environments is key to rapidly refining system performance.
3D Reactive Control and Frontier-Based Exploration for Unstructured Environments
Aug 01, 2021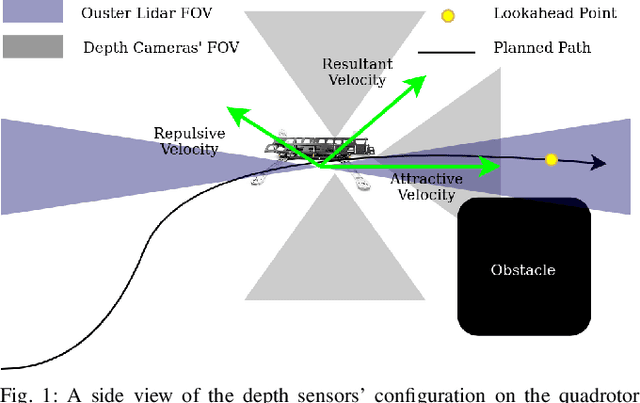
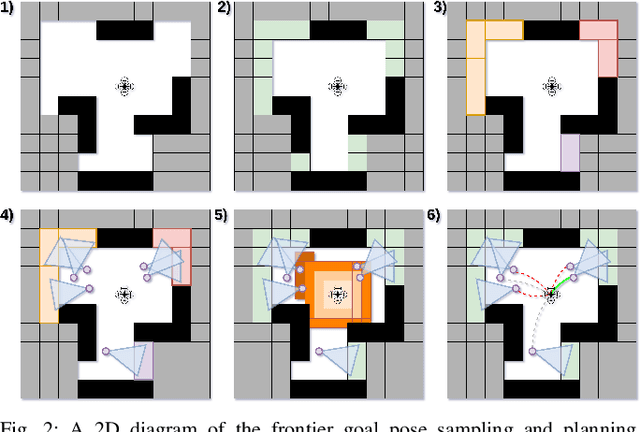
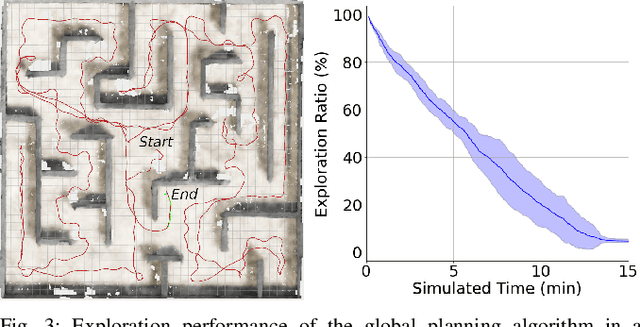

The paper proposes a reliable and robust planning solution to the long range robotic navigation problem in extremely cluttered environments. A two-layer planning architecture is proposed that leverages both the environment map and the direct depth sensor information to ensure maximal information gain out of the onboard sensors. A frontier-based pose sampling technique is used with a fast marching cost-to-go calculation to select a goal pose and plan a path to maximize robot exploration rate. An artificial potential function approach, relying on direct depth measurements, enables the robot to follow the path while simultaneously avoiding small scene obstacles that are not captured in the map due to mapping and localization uncertainties. We demonstrate the feasibility and robustness of the proposed approach through field deployments in a structurally complex warehouse using a micro-aerial vehicle (MAV) with all the sensing and computations performed onboard.