 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonotonicity as an Architectural Bias for Robust Language Models
Feb 02, 2026Large language models (LLMs) are known to exhibit brittle behavior under adversarial prompts and jailbreak attacks, even after extensive alignment and fine-tuning. This fragility reflects a broader challenge of modern neural language models: small, carefully structured perturbations in high-dimensional input spaces can induce large and unpredictable changes in internal semantic representations and output. We investigate monotonicity as an architectural inductive bias for improving the robustness of Transformer-based language models. Monotonicity constrains semantic transformations so that strengthening information, evidence, or constraints cannot lead to regressions in the corresponding internal representations. Such order-preserving behavior has long been exploited in control and safety-critical systems to simplify reasoning and improve robustness, but has traditionally been viewed as incompatible with the expressivity required by neural language models. We show that this trade-off is not inherent. By enforcing monotonicity selectively in the feed-forward sublayers of sequence-to-sequence Transformers -- while leaving attention mechanisms unconstrained -- we obtain monotone language models that preserve the performance of their pretrained counterparts. This architectural separation allows negation, contradiction, and contextual interactions to be introduced explicitly through attention, while ensuring that subsequent semantic refinement is order-preserving. Empirically, monotonicity substantially improves robustness: adversarial attack success rates drop from approximately 69% to 19%, while standard summarization performance degrades only marginally.
Active Causal Experimentalist (ACE): Learning Intervention Strategies via Direct Preference Optimization
Feb 02, 2026Discovering causal relationships requires controlled experiments, but experimentalists face a sequential decision problem: each intervention reveals information that should inform what to try next. Traditional approaches such as random sampling, greedy information maximization, and round-robin coverage treat each decision in isolation, unable to learn adaptive strategies from experience. We propose Active Causal Experimentalist (ACE), which learns experimental design as a sequential policy. Our key insight is that while absolute information gains diminish as knowledge accumulates (making value-based RL unstable), relative comparisons between candidate interventions remain meaningful throughout. ACE exploits this via Direct Preference Optimization, learning from pairwise intervention comparisons rather than non-stationary reward magnitudes. Across synthetic benchmarks, physics simulations, and economic data, ACE achieves 70-71% improvement over baselines at equal intervention budgets (p < 0.001, Cohen's d ~ 2). Notably, the learned policy autonomously discovers that collider mechanisms require concentrated interventions on parent variables, a theoretically-grounded strategy that emerges purely from experience. This suggests preference-based learning can recover principled experimental strategies, complementing theory with learned domain adaptation.
CogExplore: Contextual Exploration with Language-Encoded Environment Representations
Jun 24, 2024
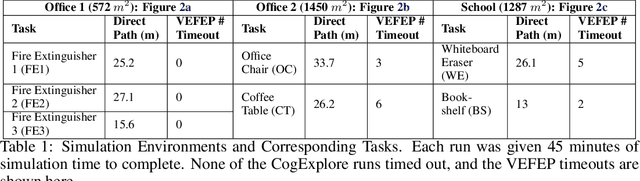

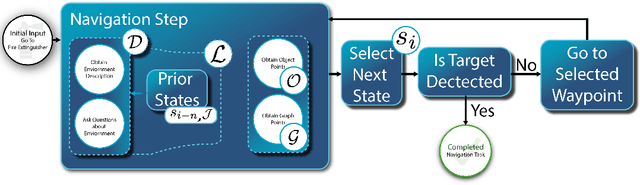
Integrating language models into robotic exploration frameworks improves performance in unmapped environments by providing the ability to reason over semantic groundings, contextual cues, and temporal states. The proposed method employs large language models (GPT-3.5 and Claude Haiku) to reason over these cues and express that reasoning in terms of natural language, which can be used to inform future states. We are motivated by the context of search-and-rescue applications where efficient exploration is critical. We find that by leveraging natural language, semantics, and tracking temporal states, the proposed method greatly reduces exploration path distance and further exposes the need for environment-dependent heuristics. Moreover, the method is highly robust to a variety of environments and noisy vision detections, as shown with a 100% success rate in a series of comprehensive experiments across three different environments conducted in a custom simulation pipeline operating in Unreal Engine.