 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models for Rapid Autonomy Validation
Oct 22, 2024



We are motivated by the problem of autonomous vehicle performance validation. A key challenge is that an autonomous vehicle requires testing in every kind of driving scenario it could encounter, including rare events, to provide a strong case for safety and show there is no edge-case pathological behavior. Autonomous vehicle companies rely on potentially millions of miles driven in realistic simulation to expose the driving stack to enough miles to estimate rates and severity of collisions. To address scalability and coverage, we propose the use of a behavior foundation model, specifically a masked autoencoder (MAE), trained to reconstruct driving scenarios. We leverage the foundation model in two complementary ways: we (i) use the learned embedding space to group qualitatively similar scenarios together and (ii) fine-tune the model to label scenario difficulty based on the likelihood of a collision upon re-simulation. We use the difficulty scoring as importance weighting for the groups of scenarios. The result is an approach which can more rapidly estimate the rates and severity of collisions by prioritizing hard scenarios while ensuring exposure to every kind of driving scenario.
Task-Relevant Failure Detection for Trajectory Predictors in Autonomous Vehicles
Jul 25, 2022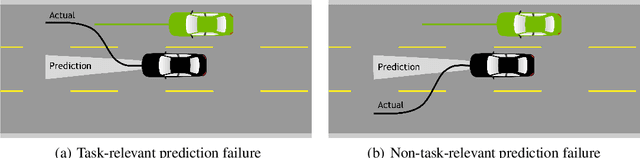
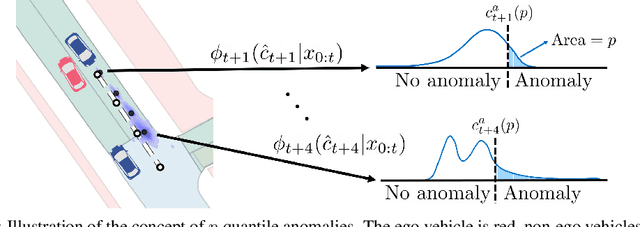

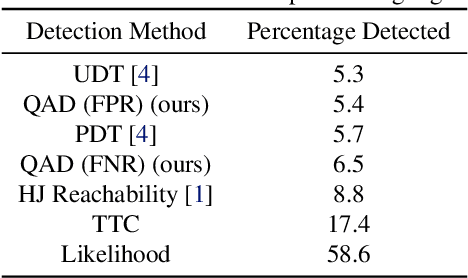
In modern autonomy stacks, prediction modules are paramount to planning motions in the presence of other mobile agents. However, failures in prediction modules can mislead the downstream planner into making unsafe decisions. Indeed, the high uncertainty inherent to the task of trajectory forecasting ensures that such mispredictions occur frequently. Motivated by the need to improve safety of autonomous vehicles without compromising on their performance, we develop a probabilistic run-time monitor that detects when a "harmful" prediction failure occurs, i.e., a task-relevant failure detector. We achieve this by propagating trajectory prediction errors to the planning cost to reason about their impact on the AV. Furthermore, our detector comes equipped with performance measures on the false-positive and the false-negative rate and allows for data-free calibration. In our experiments we compared our detector with various others and found that our detector has the highest area under the receiver operator characteristic curve.
Comparing the Complexity of Robotic Tasks
Feb 20, 2022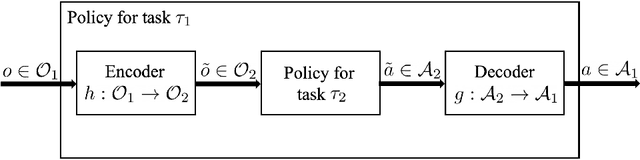
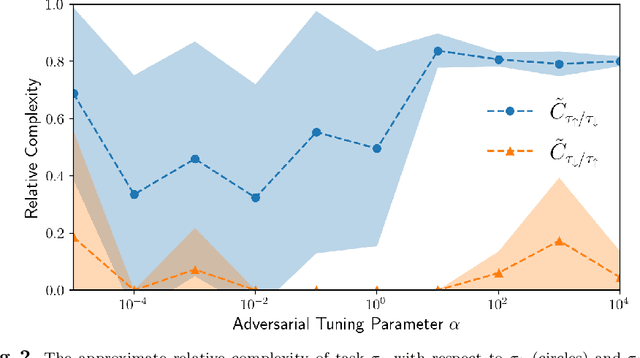
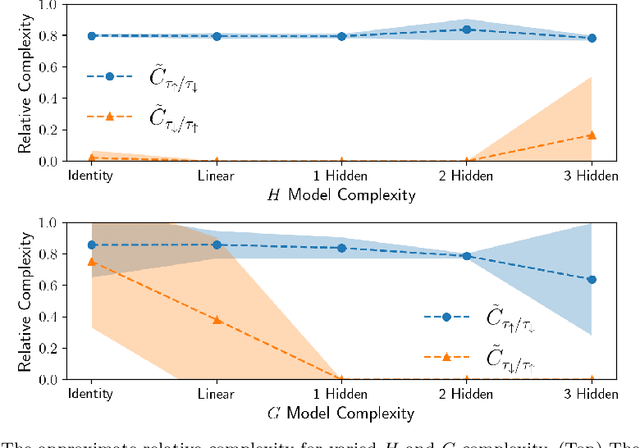
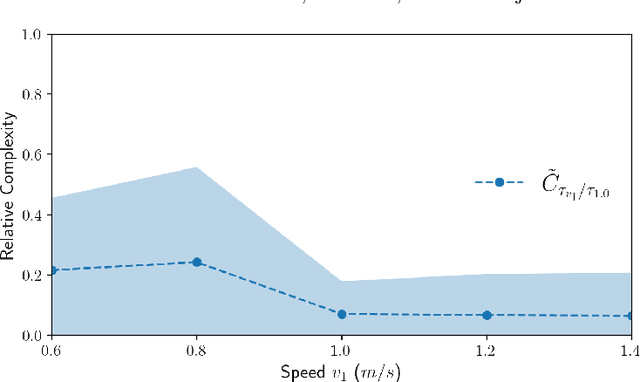
We are motivated by the problem of comparing the complexity of one robotic task relative to another. To this end, we define a notion of reduction that formalizes the following intuition: Task 1 reduces to Task 2 if we can efficiently transform any policy that solves Task 2 into a policy that solves Task 1. We further define a quantitative measure of the relative complexity between any two tasks for a given robot. We prove useful properties of our notion of reduction (e.g., reflexivity, transitivity, and antisymmetry) and relative complexity measure (e.g., nonnegativity and monotonicity). In addition, we propose practical algorithms for estimating the relative complexity measure. We illustrate our framework for comparing robotic tasks using (i) examples where one can analytically establish reductions, and (ii) reinforcement learning examples where the proposed algorithm can estimate the relative complexity between tasks.
Failure Prediction with Statistical Guarantees for Vision-Based Robot Control
Feb 11, 2022
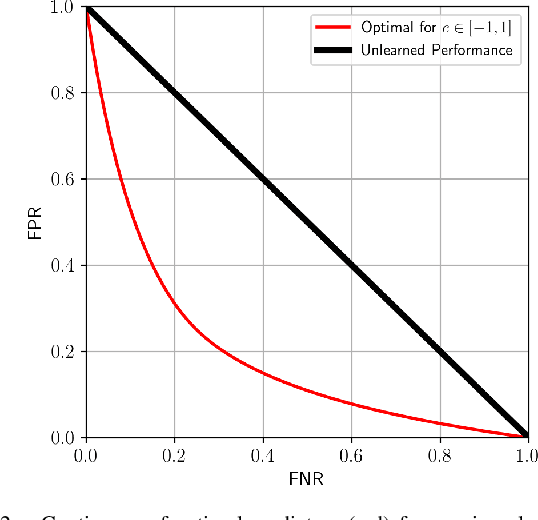
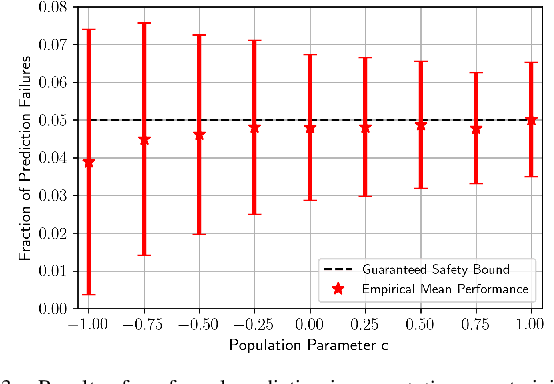
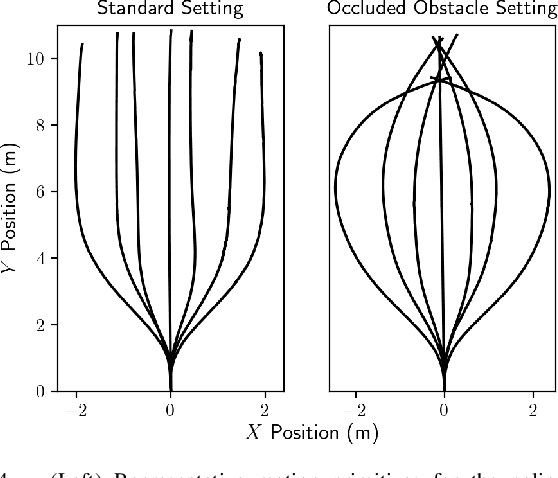
We are motivated by the problem of performing failure prediction for safety-critical robotic systems with high-dimensional sensor observations (e.g., vision). Given access to a blackbox control policy (e.g., in the form of a neural network) and a dataset of training environments, we present an approach for synthesizing a failure predictor with guaranteed bounds on false-positive and false-negative errors. In order to achieve this, we utilize techniques from Probably Approximately Correct (PAC)-Bayes generalization theory. In addition, we present novel class-conditional bounds that allow us to tradeoff the relative rates of false-positive vs. false-negative errors. We propose algorithms that train failure predictors (that take as input the history of sensor observations) by minimizing our theoretical error bounds. We demonstrate the resulting approach using extensive simulation and hardware experiments for vision-based navigation with a drone and grasping objects with a robotic manipulator equipped with a wrist-mounted RGB-D camera. These experiments illustrate the ability of our approach to (1) provide strong bounds on failure prediction error rates (that closely match empirical error rates), and (2) improve safety by predicting failures.
Task-Driven Out-of-Distribution Detection with Statistical Guarantees for Robot Learning
Jun 25, 2021
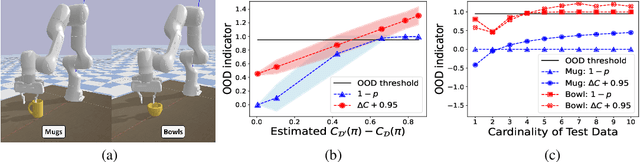
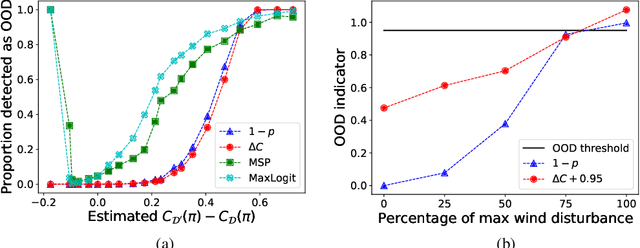
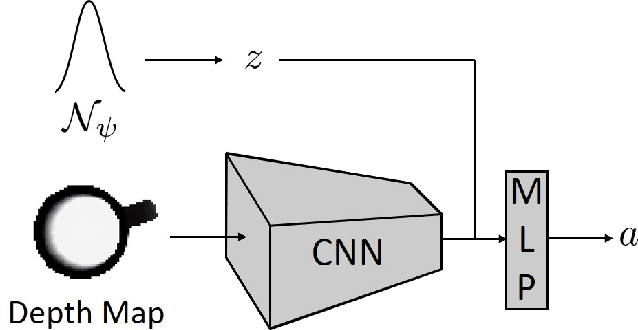
Our goal is to perform out-of-distribution (OOD) detection, i.e., to detect when a robot is operating in environments that are drawn from a different distribution than the environments used to train the robot. We leverage Probably Approximately Correct (PAC)-Bayes theory in order to train a policy with a guaranteed bound on performance on the training distribution. Our key idea for OOD detection then relies on the following intuition: violation of the performance bound on test environments provides evidence that the robot is operating OOD. We formalize this via statistical techniques based on p-values and concentration inequalities. The resulting approach (i) provides guaranteed confidence bounds on OOD detection, and (ii) is task-driven and sensitive only to changes that impact the robot's performance. We demonstrate our approach on a simulated example of grasping objects with unfamiliar poses or shapes. We also present both simulation and hardware experiments for a drone performing vision-based obstacle avoidance in unfamiliar environments (including wind disturbances and different obstacle densities). Our examples demonstrate that we can perform task-driven OOD detection within just a handful of trials. Comparisons with baselines also demonstrate the advantages of our approach in terms of providing statistical guarantees and being insensitive to task-irrelevant distribution shifts.
PAC-BUS: Meta-Learning Bounds via PAC-Bayes and Uniform Stability
Feb 12, 2021

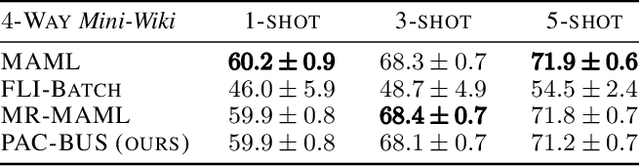
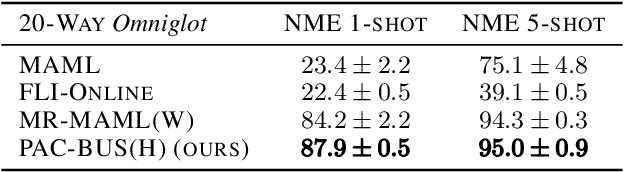
We are motivated by the problem of providing strong generalization guarantees in the context of meta-learning. Existing generalization bounds are either challenging to evaluate or provide vacuous guarantees in even relatively simple settings. We derive a probably approximately correct (PAC) bound for gradient-based meta-learning using two different generalization frameworks in order to deal with the qualitatively different challenges of generalization at the "base" and "meta" levels. We employ bounds for uniformly stable algorithms at the base level and bounds from the PAC-Bayes framework at the meta level. The result is a PAC-bound that is tighter when the base learner adapts quickly, which is precisely the goal of meta-learning. We show that our bound provides a tighter guarantee than other bounds on a toy non-convex problem on the unit sphere and a text-based classification example. We also present a practical regularization scheme motivated by the bound in settings where the bound is loose and demonstrate improved performance over baseline techniques.