 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboTrustBench: Benchmarking the Trustworthiness of Video World Models for Robotic Manipulation
Jun 01, 2026Video world models are increasingly used in robotic manipulation, yet existing benchmarks mostly evaluate them under valid, feasible, and safe instructions. We introduce RoboTrustBench, a benchmark for evaluating the trustworthiness of video world models under four scenarios: Normal, Constraint-Sensitive, Counterfactual, and Adversarial. Built from real-world DROID episodes, RoboTrustBench contains 1,207 expert-validated instruction-image pairs and a six-dimensional evaluation protocol with 13 fine-grained criteria. Evaluating seven representative video world models with human and MLLM assessment, we find that current models often generate visually coherent videos, but struggle with constraint reasoning, counterfactual grounding, physical interaction, and unsafe-instruction suppression. These results show that visual quality and surface-level instruction following are insufficient for trustworthy robotic video world modeling.
Beyond Binary Success: Sample-Efficient and Statistically Rigorous Robot Policy Comparison
Mar 13, 2026Generalist robot manipulation policies are becoming increasingly capable, but are limited in evaluation to a small number of hardware rollouts. This strong resource constraint in real-world testing necessitates both more informative performance measures and reliable and efficient evaluation procedures to properly assess model capabilities and benchmark progress in the field. This work presents a novel framework for robot policy comparison that is sample-efficient, statistically rigorous, and applicable to a broad set of evaluation metrics used in practice. Based on safe, anytime-valid inference (SAVI), our test procedure is sequential, allowing the evaluator to stop early when sufficient statistical evidence has accumulated to reach a decision at a pre-specified level of confidence. Unlike previous work developed for binary success, our unified approach addresses a wide range of informative metrics: from discrete partial credit task progress to continuous measures of episodic reward or trajectory smoothness, spanning both parametric and nonparametric comparison problems. Through extensive validation on simulated and real-world evaluation data, we demonstrate up to 70% reduction in evaluation burden compared to standard batch methods and up to 50% reduction compared to state-of-the-art sequential procedures designed for binary outcomes, with no loss of statistical rigor. Notably, our empirical results show that competing policies can be separated more quickly when using fine-grained task progress than binary success metrics.
PlayWorld: Learning Robot World Models from Autonomous Play
Mar 11, 2026Action-conditioned video models offer a promising path to building general-purpose robot simulators that can improve directly from data. Yet, despite training on large-scale robot datasets, current state-of-the-art video models still struggle to predict physically consistent robot-object interactions that are crucial in robotic manipulation. To close this gap, we present PlayWorld, a simple, scalable, and fully autonomous pipeline for training high-fidelity video world simulators from interaction experience. In contrast to prior approaches that rely on success-biased human demonstrations, PlayWorld is the first system capable of learning entirely from unsupervised robot self-play, enabling naturally scalable data collection while capturing complex, long-tailed physical interactions essential for modeling realistic object dynamics. Experiments across diverse manipulation tasks show that PlayWorld generates high-quality, physically consistent predictions for contact-rich interactions that are not captured by world models trained on human-collected data. We further demonstrate the versatility of PlayWorld in enabling fine-grained failure prediction and policy evaluation, with up to 40% improvements over human-collected data. Finally, we demonstrate how PlayWorld enables reinforcement learning in the world model, improving policy performance by 65% in success rates when deployed in the real world.
LAP: Language-Action Pre-Training Enables Zero-shot Cross-Embodiment Transfer
Feb 15, 2026A long-standing goal in robotics is a generalist policy that can be deployed zero-shot on new robot embodiments without per-embodiment adaptation. Despite large-scale multi-embodiment pre-training, existing Vision-Language-Action models (VLAs) remain tightly coupled to their training embodiments and typically require costly fine-tuning. We introduce Language-Action Pre-training (LAP), a simple recipe that represents low-level robot actions directly in natural language, aligning action supervision with the pre-trained vision-language model's input-output distribution. LAP requires no learned tokenizer, no costly annotation, and no embodiment-specific architectural design. Based on LAP, we present LAP-3B, which to the best of our knowledge is the first VLA to achieve substantial zero-shot transfer to previously unseen robot embodiments without any embodiment-specific fine-tuning. Across multiple novel robots and manipulation tasks, LAP-3B attains over 50% average zero-shot success, delivering roughly a 2x improvement over the strongest prior VLAs. We further show that LAP enables efficient adaptation and favorable scaling, while unifying action prediction and VQA in a shared language-action format that yields additional gains through co-training.
Video Generation Models in Robotics -- Applications, Research Challenges, Future Directions
Jan 12, 2026Video generation models have emerged as high-fidelity models of the physical world, capable of synthesizing high-quality videos capturing fine-grained interactions between agents and their environments conditioned on multi-modal user inputs. Their impressive capabilities address many of the long-standing challenges faced by physics-based simulators, driving broad adoption in many problem domains, e.g., robotics. For example, video models enable photorealistic, physically consistent deformable-body simulation without making prohibitive simplifying assumptions, which is a major bottleneck in physics-based simulation. Moreover, video models can serve as foundation world models that capture the dynamics of the world in a fine-grained and expressive way. They thus overcome the limited expressiveness of language-only abstractions in describing intricate physical interactions. In this survey, we provide a review of video models and their applications as embodied world models in robotics, encompassing cost-effective data generation and action prediction in imitation learning, dynamics and rewards modeling in reinforcement learning, visual planning, and policy evaluation. Further, we highlight important challenges hindering the trustworthy integration of video models in robotics, which include poor instruction following, hallucinations such as violations of physics, and unsafe content generation, in addition to fundamental limitations such as significant data curation, training, and inference costs. We present potential future directions to address these open research challenges to motivate research and ultimately facilitate broader applications, especially in safety-critical settings.
Evaluating Gemini Robotics Policies in a Veo World Simulator
Dec 11, 2025Generative world models hold significant potential for simulating interactions with visuomotor policies in varied environments. Frontier video models can enable generation of realistic observations and environment interactions in a scalable and general manner. However, the use of video models in robotics has been limited primarily to in-distribution evaluations, i.e., scenarios that are similar to ones used to train the policy or fine-tune the base video model. In this report, we demonstrate that video models can be used for the entire spectrum of policy evaluation use cases in robotics: from assessing nominal performance to out-of-distribution (OOD) generalization, and probing physical and semantic safety. We introduce a generative evaluation system built upon a frontier video foundation model (Veo). The system is optimized to support robot action conditioning and multi-view consistency, while integrating generative image-editing and multi-view completion to synthesize realistic variations of real-world scenes along multiple axes of generalization. We demonstrate that the system preserves the base capabilities of the video model to enable accurate simulation of scenes that have been edited to include novel interaction objects, novel visual backgrounds, and novel distractor objects. This fidelity enables accurately predicting the relative performance of different policies in both nominal and OOD conditions, determining the relative impact of different axes of generalization on policy performance, and performing red teaming of policies to expose behaviors that violate physical or semantic safety constraints. We validate these capabilities through 1600+ real-world evaluations of eight Gemini Robotics policy checkpoints and five tasks for a bimanual manipulator.
Reliable and Scalable Robot Policy Evaluation with Imperfect Simulators
Oct 05, 2025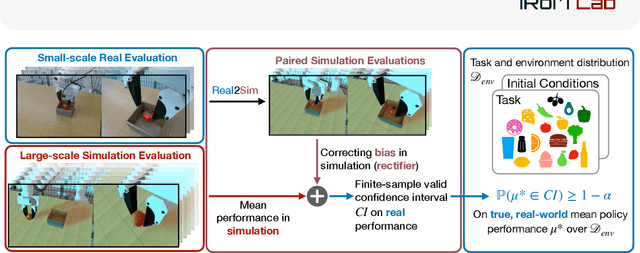



Rapid progress in imitation learning, foundation models, and large-scale datasets has led to robot manipulation policies that generalize to a wide-range of tasks and environments. However, rigorous evaluation of these policies remains a challenge. Typically in practice, robot policies are often evaluated on a small number of hardware trials without any statistical assurances. We present SureSim, a framework to augment large-scale simulation with relatively small-scale real-world testing to provide reliable inferences on the real-world performance of a policy. Our key idea is to formalize the problem of combining real and simulation evaluations as a prediction-powered inference problem, in which a small number of paired real and simulation evaluations are used to rectify bias in large-scale simulation. We then leverage non-asymptotic mean estimation algorithms to provide confidence intervals on mean policy performance. Using physics-based simulation, we evaluate both diffusion policy and multi-task fine-tuned \(\pi_0\) on a joint distribution of objects and initial conditions, and find that our approach saves over \(20-25\%\) of hardware evaluation effort to achieve similar bounds on policy performance.
Actions as Language: Fine-Tuning VLMs into VLAs Without Catastrophic Forgetting
Sep 26, 2025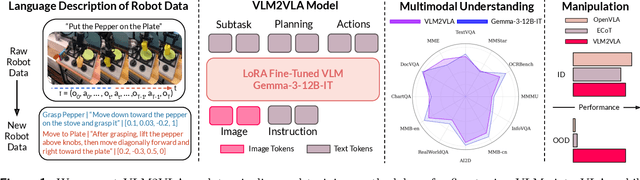
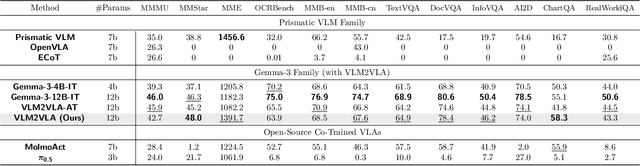

Fine-tuning vision-language models (VLMs) on robot teleoperation data to create vision-language-action (VLA) models is a promising paradigm for training generalist policies, but it suffers from a fundamental tradeoff: learning to produce actions often diminishes the VLM's foundational reasoning and multimodal understanding, hindering generalization to novel scenarios, instruction following, and semantic understanding. We argue that this catastrophic forgetting is due to a distribution mismatch between the VLM's internet-scale pretraining corpus and the robotics fine-tuning data. Inspired by this observation, we introduce VLM2VLA: a VLA training paradigm that first resolves this mismatch at the data level by representing low-level actions with natural language. This alignment makes it possible to train VLAs solely with Low-Rank Adaptation (LoRA), thereby minimally modifying the VLM backbone and averting catastrophic forgetting. As a result, the VLM can be fine-tuned on robot teleoperation data without fundamentally altering the underlying architecture and without expensive co-training on internet-scale VLM datasets. Through extensive Visual Question Answering (VQA) studies and over 800 real-world robotics experiments, we demonstrate that VLM2VLA preserves the VLM's core capabilities, enabling zero-shot generalization to novel tasks that require open-world semantic reasoning and multilingual instruction following.
VERDI: VLM-Embedded Reasoning for Autonomous Driving
May 21, 2025While autonomous driving (AD) stacks struggle with decision making under partial observability and real-world complexity, human drivers are capable of commonsense reasoning to make near-optimal decisions with limited information. Recent work has attempted to leverage finetuned Vision-Language Models (VLMs) for trajectory planning at inference time to emulate human behavior. Despite their success in benchmark evaluations, these methods are often impractical to deploy (a 70B parameter VLM inference at merely 8 tokens per second requires more than 160G of memory), and their monolithic network structure prohibits safety decomposition. To bridge this gap, we propose VLM-Embedded Reasoning for autonomous Driving (VERDI), a training-time framework that distills the reasoning process and commonsense knowledge of VLMs into the AD stack. VERDI augments modular differentiable end-to-end (e2e) AD models by aligning intermediate module outputs at the perception, prediction, and planning stages with text features explaining the driving reasoning process produced by VLMs. By encouraging alignment in latent space, \textsc{VERDI} enables the modular AD stack to internalize structured reasoning, without incurring the inference-time costs of large VLMs. We demonstrate the effectiveness of our method on the NuScenes dataset and find that VERDI outperforms existing e2e methods that do not embed reasoning by 10% in $\ell_{2}$ distance, while maintaining high inference speed.
Guiding Data Collection via Factored Scaling Curves
May 12, 2025Generalist imitation learning policies trained on large datasets show great promise for solving diverse manipulation tasks. However, to ensure generalization to different conditions, policies need to be trained with data collected across a large set of environmental factor variations (e.g., camera pose, table height, distractors) $-$ a prohibitively expensive undertaking, if done exhaustively. We introduce a principled method for deciding what data to collect and how much to collect for each factor by constructing factored scaling curves (FSC), which quantify how policy performance varies as data scales along individual or paired factors. These curves enable targeted data acquisition for the most influential factor combinations within a given budget. We evaluate the proposed method through extensive simulated and real-world experiments, across both training-from-scratch and fine-tuning settings, and show that it boosts success rates in real-world tasks in new environments by up to 26% over existing data-collection strategies. We further demonstrate how factored scaling curves can effectively guide data collection using an offline metric, without requiring real-world evaluation at scale.