 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAP: Language-Action Pre-Training Enables Zero-shot Cross-Embodiment Transfer
Feb 15, 2026A long-standing goal in robotics is a generalist policy that can be deployed zero-shot on new robot embodiments without per-embodiment adaptation. Despite large-scale multi-embodiment pre-training, existing Vision-Language-Action models (VLAs) remain tightly coupled to their training embodiments and typically require costly fine-tuning. We introduce Language-Action Pre-training (LAP), a simple recipe that represents low-level robot actions directly in natural language, aligning action supervision with the pre-trained vision-language model's input-output distribution. LAP requires no learned tokenizer, no costly annotation, and no embodiment-specific architectural design. Based on LAP, we present LAP-3B, which to the best of our knowledge is the first VLA to achieve substantial zero-shot transfer to previously unseen robot embodiments without any embodiment-specific fine-tuning. Across multiple novel robots and manipulation tasks, LAP-3B attains over 50% average zero-shot success, delivering roughly a 2x improvement over the strongest prior VLAs. We further show that LAP enables efficient adaptation and favorable scaling, while unifying action prediction and VQA in a shared language-action format that yields additional gains through co-training.
Actions as Language: Fine-Tuning VLMs into VLAs Without Catastrophic Forgetting
Sep 26, 2025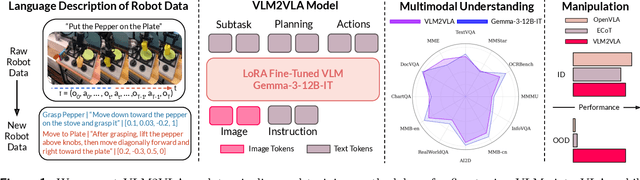
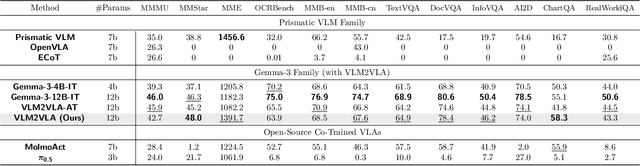

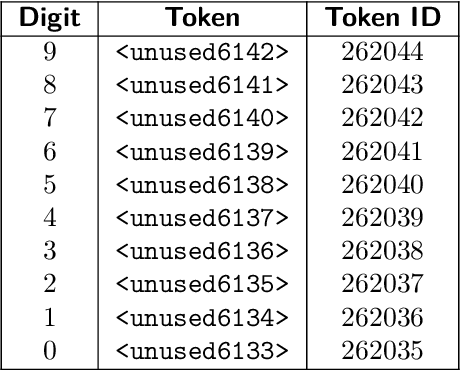
Fine-tuning vision-language models (VLMs) on robot teleoperation data to create vision-language-action (VLA) models is a promising paradigm for training generalist policies, but it suffers from a fundamental tradeoff: learning to produce actions often diminishes the VLM's foundational reasoning and multimodal understanding, hindering generalization to novel scenarios, instruction following, and semantic understanding. We argue that this catastrophic forgetting is due to a distribution mismatch between the VLM's internet-scale pretraining corpus and the robotics fine-tuning data. Inspired by this observation, we introduce VLM2VLA: a VLA training paradigm that first resolves this mismatch at the data level by representing low-level actions with natural language. This alignment makes it possible to train VLAs solely with Low-Rank Adaptation (LoRA), thereby minimally modifying the VLM backbone and averting catastrophic forgetting. As a result, the VLM can be fine-tuned on robot teleoperation data without fundamentally altering the underlying architecture and without expensive co-training on internet-scale VLM datasets. Through extensive Visual Question Answering (VQA) studies and over 800 real-world robotics experiments, we demonstrate that VLM2VLA preserves the VLM's core capabilities, enabling zero-shot generalization to novel tasks that require open-world semantic reasoning and multilingual instruction following.
Run-time Observation Interventions Make Vision-Language-Action Models More Visually Robust
Oct 02, 2024



Vision-language-action (VLA) models trained on large-scale internet data and robot demonstrations have the potential to serve as generalist robot policies. However, despite their large-scale training, VLAs are often brittle to task-irrelevant visual details such as distractor objects or background colors. We introduce Bring Your Own VLA (BYOVLA): a run-time intervention scheme that (1) dynamically identifies regions of the input image that the model is sensitive to, and (2) minimally alters task-irrelevant regions to reduce the model's sensitivity using automated image editing tools. Our approach is compatible with any off the shelf VLA without model fine-tuning or access to the model's weights. Hardware experiments on language-instructed manipulation tasks demonstrate that BYOVLA enables state-of-the-art VLA models to nearly retain their nominal performance in the presence of distractor objects and backgrounds, which otherwise degrade task success rates by up to 40%. Website with additional information, videos, and code: https://aasherh.github.io/byovla/ .