 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Generative Models for Contextual Debiasing
May 25, 2026Different visual patterns appear with different frequencies in the world: e.g., beach balls appear on sand more often than they do on a road. These statistics are reflected in vision datasets, and as a result trained models more easily recognize objects in common scenarios. However, recognizing a beach ball on a road may arguably be even more important than recognizing it on sand. We study how to mitigate this discrepancy. Since collecting uncommon images in the real world may be difficult, we explore whether generating images with less frequent contexts can serve as effective training augmentation. A key challenge is guiding generations to remain close to the original dataset distribution while creating diverse images with uncommon contexts. We introduce Decoupling Contextual Patterns with Generations (DecoupleGen), a method that personalizes text-to-image diffusion models to facilitate coherent synthesis of images with rare contexts while preserving original visual details. The generated images contain semantically meaningful content and remain visually aligned with the original datasets. We further apply verification constraints to ensure relevance of the augmented data. We evaluate our approach on object classification and recognition tasks on complex scene datasets. Our experiments demonstrate consistent improvements over previous approaches, and our analyses identify factors underlying these improvements.
Bias at the End of the Score
Apr 14, 2026Reward models (RMs) are inherently non-neutral value functions designed and trained to encode specific objectives, such as human preferences or text-image alignment. RMs have become crucial components of text-to-image (T2I) generation systems where they are used at various stages for dataset filtering, as evaluation metrics, as a supervisory signal during optimization of parameters, and for post-generation safety and quality filtering of T2I outputs. While specific problems with the integration of RMs into the T2I pipeline have been studied (e.g. reward hacking or mode collapse), their robustness and fairness as scoring functions remains largely unknown. We conduct a large scale audit of RM robustness with respect to demographic biases during T2I model training and generation. We provide quantitative and qualitative evidence that while originally developed as quality measures, RMs encode demographic biases, which cause reward-guided optimization to disproportionately sexualize female image subjects reinforce gender/racial stereotypes, and collapse demographic diversity. These findings highlight shortcomings in current reward models, challenge their reliability as quality metrics, and underscore the need for improved data collection and training procedures to enable more robust scoring.
Video Models Reason Early: Exploiting Plan Commitment for Maze Solving
Mar 31, 2026Video diffusion models exhibit emergent reasoning capabilities like solving mazes and puzzles, yet little is understood about how they reason during generation. We take a first step towards understanding this and study the internal planning dynamics of video models using 2D maze solving as a controlled testbed. Our investigations reveal two findings. Our first finding is early plan commitment: video diffusion models commit to a high-level motion plan within the first few denoising steps, after which further denoising alters visual details but not the underlying trajectory. Our second finding is that path length, not obstacle density, is the dominant predictor of maze difficulty, with a sharp failure threshold at 12 steps. This means video models can only reason over long mazes by chaining together multiple sequential generations. To demonstrate the practical benefits of our findings, we introduce Chaining with Early Planning, or ChEaP, which only spends compute on seeds with promising early plans and chains them together to tackle complex mazes. This improves accuracy from 7% to 67% on long-horizon mazes and by 2.5x overall on hard tasks in Frozen Lake and VR-Bench across Wan2.2-14B and HunyuanVideo-1.5. Our analysis reveals that current video models possess deeper reasoning capabilities than previously recognized, which can be elicited more reliably with better inference-time scaling.
GASS: Geometry-Aware Spherical Sampling for Disentangled Diversity Enhancement in Text-to-Image Generation
Feb 19, 2026Despite high semantic alignment, modern text-to-image (T2I) generative models still struggle to synthesize diverse images from a given prompt. This lack of diversity not only restricts user choice, but also risks amplifying societal biases. In this work, we enhance the T2I diversity through a geometric lens. Unlike most existing methods that rely primarily on entropy-based guidance to increase sample dissimilarity, we introduce Geometry-Aware Spherical Sampling (GASS) to enhance diversity by explicitly controlling both prompt-dependent and prompt-independent sources of variation. Specifically, we decompose the diversity measure in CLIP embeddings using two orthogonal directions: the text embedding, which captures semantic variation related to the prompt, and an identified orthogonal direction that captures prompt-independent variation (e.g., backgrounds). Based on this decomposition, GASS increases the geometric projection spread of generated image embeddings along both axes and guides the T2I sampling process via expanded predictions along the generation trajectory. Our experiments on different frozen T2I backbones (U-Net and DiT, diffusion and flow) and benchmarks demonstrate the effectiveness of disentangled diversity enhancement with minimal impact on image fidelity and semantic alignment.
Reinforced Fast Weights with Next-Sequence Prediction
Feb 18, 2026Fast weight architectures offer a promising alternative to attention-based transformers for long-context modeling by maintaining constant memory overhead regardless of context length. However, their potential is limited by the next-token prediction (NTP) training paradigm. NTP optimizes single-token predictions and ignores semantic coherence across multiple tokens following a prefix. Consequently, fast weight models, which dynamically update their parameters to store contextual information, learn suboptimal representations that fail to capture long-range dependencies. We introduce REFINE (Reinforced Fast weIghts with Next sEquence prediction), a reinforcement learning framework that trains fast weight models under the next-sequence prediction (NSP) objective. REFINE selects informative token positions based on prediction entropy, generates multi-token rollouts, assigns self-supervised sequence-level rewards, and optimizes the model with group relative policy optimization (GRPO). REFINE is applicable throughout the training lifecycle of pre-trained language models: mid-training, post-training, and test-time training. Our experiments on LaCT-760M and DeltaNet-1.3B demonstrate that REFINE consistently outperforms supervised fine-tuning with NTP across needle-in-a-haystack retrieval, long-context question answering, and diverse tasks in LongBench. REFINE provides an effective and versatile framework for improving long-context modeling in fast weight architectures.
Motion Attribution for Video Generation
Jan 13, 2026Despite the rapid progress of video generation models, the role of data in influencing motion is poorly understood. We present Motive (MOTIon attribution for Video gEneration), a motion-centric, gradient-based data attribution framework that scales to modern, large, high-quality video datasets and models. We use this to study which fine-tuning clips improve or degrade temporal dynamics. Motive isolates temporal dynamics from static appearance via motion-weighted loss masks, yielding efficient and scalable motion-specific influence computation. On text-to-video models, Motive identifies clips that strongly affect motion and guides data curation that improves temporal consistency and physical plausibility. With Motive-selected high-influence data, our method improves both motion smoothness and dynamic degree on VBench, achieving a 74.1% human preference win rate compared with the pretrained base model. To our knowledge, this is the first framework to attribute motion rather than visual appearance in video generative models and to use it to curate fine-tuning data.
Seeing Beyond the Scene: Analyzing and Mitigating Background Bias in Action Recognition
Dec 17, 2025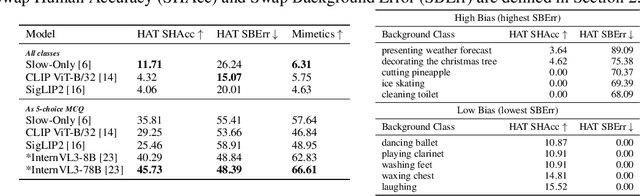
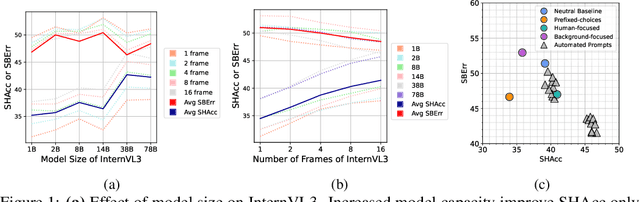


Human action recognition models often rely on background cues rather than human movement and pose to make predictions, a behavior known as background bias. We present a systematic analysis of background bias across classification models, contrastive text-image pretrained models, and Video Large Language Models (VLLM) and find that all exhibit a strong tendency to default to background reasoning. Next, we propose mitigation strategies for classification models and show that incorporating segmented human input effectively decreases background bias by 3.78%. Finally, we explore manual and automated prompt tuning for VLLMs, demonstrating that prompt design can steer predictions towards human-focused reasoning by 9.85%.
D2D: Detector-to-Differentiable Critic for Improved Numeracy in Text-to-Image Generation
Oct 22, 2025
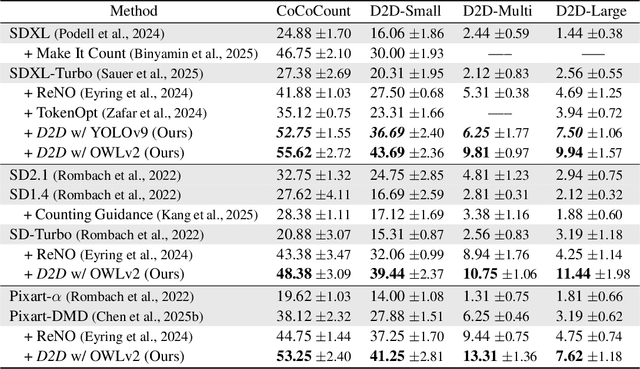
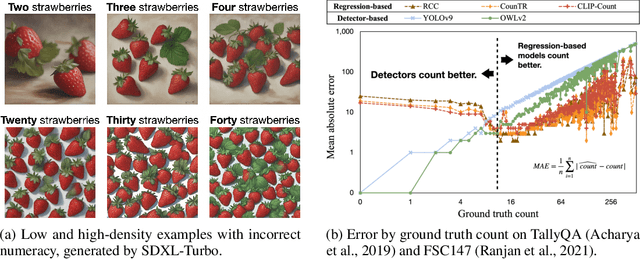
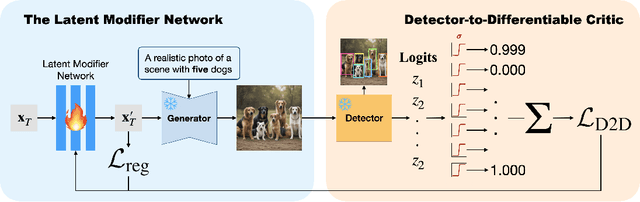
Text-to-image (T2I) diffusion models have achieved strong performance in semantic alignment, yet they still struggle with generating the correct number of objects specified in prompts. Existing approaches typically incorporate auxiliary counting networks as external critics to enhance numeracy. However, since these critics must provide gradient guidance during generation, they are restricted to regression-based models that are inherently differentiable, thus excluding detector-based models with superior counting ability, whose count-via-enumeration nature is non-differentiable. To overcome this limitation, we propose Detector-to-Differentiable (D2D), a novel framework that transforms non-differentiable detection models into differentiable critics, thereby leveraging their superior counting ability to guide numeracy generation. Specifically, we design custom activation functions to convert detector logits into soft binary indicators, which are then used to optimize the noise prior at inference time with pre-trained T2I models. Our extensive experiments on SDXL-Turbo, SD-Turbo, and Pixart-DMD across four benchmarks of varying complexity (low-density, high-density, and multi-object scenarios) demonstrate consistent and substantial improvements in object counting accuracy (e.g., boosting up to 13.7% on D2D-Small, a 400-prompt, low-density benchmark), with minimal degradation in overall image quality and computational overhead.
Actions as Language: Fine-Tuning VLMs into VLAs Without Catastrophic Forgetting
Sep 26, 2025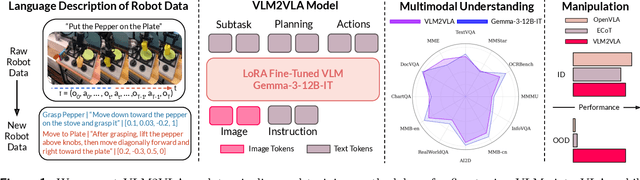
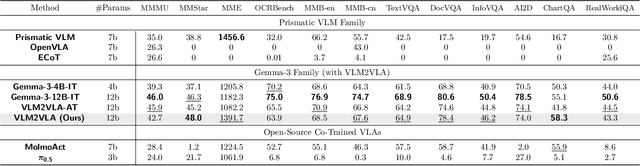

Fine-tuning vision-language models (VLMs) on robot teleoperation data to create vision-language-action (VLA) models is a promising paradigm for training generalist policies, but it suffers from a fundamental tradeoff: learning to produce actions often diminishes the VLM's foundational reasoning and multimodal understanding, hindering generalization to novel scenarios, instruction following, and semantic understanding. We argue that this catastrophic forgetting is due to a distribution mismatch between the VLM's internet-scale pretraining corpus and the robotics fine-tuning data. Inspired by this observation, we introduce VLM2VLA: a VLA training paradigm that first resolves this mismatch at the data level by representing low-level actions with natural language. This alignment makes it possible to train VLAs solely with Low-Rank Adaptation (LoRA), thereby minimally modifying the VLM backbone and averting catastrophic forgetting. As a result, the VLM can be fine-tuned on robot teleoperation data without fundamentally altering the underlying architecture and without expensive co-training on internet-scale VLM datasets. Through extensive Visual Question Answering (VQA) studies and over 800 real-world robotics experiments, we demonstrate that VLM2VLA preserves the VLM's core capabilities, enabling zero-shot generalization to novel tasks that require open-world semantic reasoning and multilingual instruction following.
The Impact of Coreset Selection on Spurious Correlations and Group Robustness
Jul 15, 2025
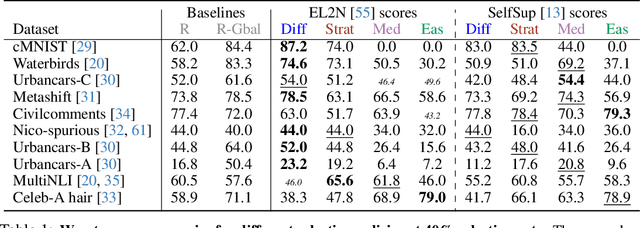

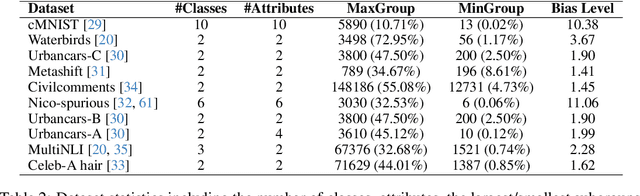
Coreset selection methods have shown promise in reducing the training data size while maintaining model performance for data-efficient machine learning. However, as many datasets suffer from biases that cause models to learn spurious correlations instead of causal features, it is important to understand whether and how dataset reduction methods may perpetuate, amplify, or mitigate these biases. In this work, we conduct the first comprehensive analysis of the implications of data selection on the spurious bias levels of the selected coresets and the robustness of downstream models trained on them. We use an extensive experimental setting spanning ten different spurious correlations benchmarks, five score metrics to characterize sample importance/ difficulty, and five data selection policies across a broad range of coreset sizes. Thereby, we unravel a series of nontrivial nuances in interactions between sample difficulty and bias alignment, as well as dataset bias and resultant model robustness. For example, we find that selecting coresets using embedding-based sample characterization scores runs a comparatively lower risk of inadvertently exacerbating bias than selecting using characterizations based on learning dynamics. Most importantly, our analysis reveals that although some coreset selection methods could achieve lower bias levels by prioritizing difficult samples, they do not reliably guarantee downstream robustness.