 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Generative Models for Contextual Debiasing
May 25, 2026Different visual patterns appear with different frequencies in the world: e.g., beach balls appear on sand more often than they do on a road. These statistics are reflected in vision datasets, and as a result trained models more easily recognize objects in common scenarios. However, recognizing a beach ball on a road may arguably be even more important than recognizing it on sand. We study how to mitigate this discrepancy. Since collecting uncommon images in the real world may be difficult, we explore whether generating images with less frequent contexts can serve as effective training augmentation. A key challenge is guiding generations to remain close to the original dataset distribution while creating diverse images with uncommon contexts. We introduce Decoupling Contextual Patterns with Generations (DecoupleGen), a method that personalizes text-to-image diffusion models to facilitate coherent synthesis of images with rare contexts while preserving original visual details. The generated images contain semantically meaningful content and remain visually aligned with the original datasets. We further apply verification constraints to ensure relevance of the augmented data. We evaluate our approach on object classification and recognition tasks on complex scene datasets. Our experiments demonstrate consistent improvements over previous approaches, and our analyses identify factors underlying these improvements.
Bias at the End of the Score
Apr 14, 2026Reward models (RMs) are inherently non-neutral value functions designed and trained to encode specific objectives, such as human preferences or text-image alignment. RMs have become crucial components of text-to-image (T2I) generation systems where they are used at various stages for dataset filtering, as evaluation metrics, as a supervisory signal during optimization of parameters, and for post-generation safety and quality filtering of T2I outputs. While specific problems with the integration of RMs into the T2I pipeline have been studied (e.g. reward hacking or mode collapse), their robustness and fairness as scoring functions remains largely unknown. We conduct a large scale audit of RM robustness with respect to demographic biases during T2I model training and generation. We provide quantitative and qualitative evidence that while originally developed as quality measures, RMs encode demographic biases, which cause reward-guided optimization to disproportionately sexualize female image subjects reinforce gender/racial stereotypes, and collapse demographic diversity. These findings highlight shortcomings in current reward models, challenge their reliability as quality metrics, and underscore the need for improved data collection and training procedures to enable more robust scoring.
Attention IoU: Examining Biases in CelebA using Attention Maps
Mar 26, 2025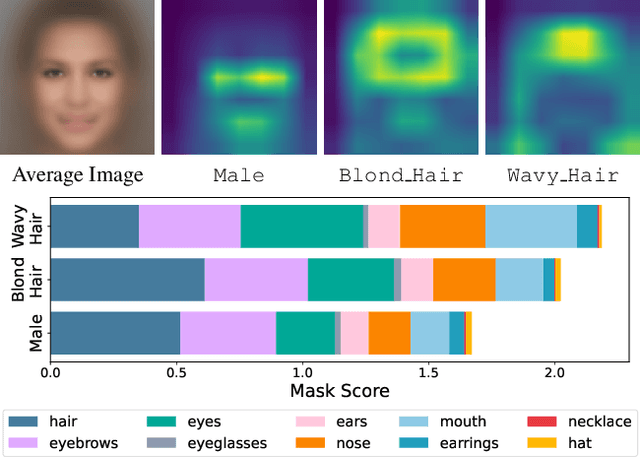

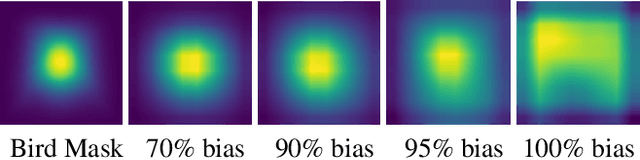
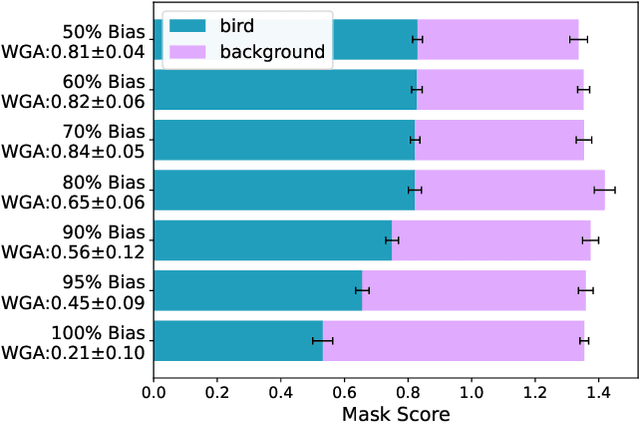
Computer vision models have been shown to exhibit and amplify biases across a wide array of datasets and tasks. Existing methods for quantifying bias in classification models primarily focus on dataset distribution and model performance on subgroups, overlooking the internal workings of a model. We introduce the Attention-IoU (Attention Intersection over Union) metric and related scores, which use attention maps to reveal biases within a model's internal representations and identify image features potentially causing the biases. First, we validate Attention-IoU on the synthetic Waterbirds dataset, showing that the metric accurately measures model bias. We then analyze the CelebA dataset, finding that Attention-IoU uncovers correlations beyond accuracy disparities. Through an investigation of individual attributes through the protected attribute of Male, we examine the distinct ways biases are represented in CelebA. Lastly, by subsampling the training set to change attribute correlations, we demonstrate that Attention-IoU reveals potential confounding variables not present in dataset labels.
UFO: A unified method for controlling Understandability and Faithfulness Objectives in concept-based explanations for CNNs
Mar 27, 2023



Concept-based explanations for convolutional neural networks (CNNs) aim to explain model behavior and outputs using a pre-defined set of semantic concepts (e.g., the model recognizes scene class ``bedroom'' based on the presence of concepts ``bed'' and ``pillow''). However, they often do not faithfully (i.e., accurately) characterize the model's behavior and can be too complex for people to understand. Further, little is known about how faithful and understandable different explanation methods are, and how to control these two properties. In this work, we propose UFO, a unified method for controlling Understandability and Faithfulness Objectives in concept-based explanations. UFO formalizes understandability and faithfulness as mathematical objectives and unifies most existing concept-based explanations methods for CNNs. Using UFO, we systematically investigate how explanations change as we turn the knobs of faithfulness and understandability. Our experiments demonstrate a faithfulness-vs-understandability tradeoff: increasing understandability reduces faithfulness. We also provide insights into the ``disagreement problem'' in explainable machine learning, by analyzing when and how concept-based explanations disagree with each other.
Beyond web-scraping: Crowd-sourcing a geographically diverse image dataset
Jan 05, 2023



Current dataset collection methods typically scrape large amounts of data from the web. While this technique is extremely scalable, data collected in this way tends to reinforce stereotypical biases, can contain personally identifiable information, and typically originates from Europe and North America. In this work, we rethink the dataset collection paradigm and introduce GeoDE, a geographically diverse dataset with 61,940 images from 40 classes and 6 world regions, and no personally identifiable information, collected through crowd-sourcing. We analyse GeoDE to understand differences in images collected in this manner compared to web-scraping. Despite the smaller size of this dataset, we demonstrate its use as both an evaluation and training dataset, highlight shortcomings in current models, as well as show improved performances when even small amounts of GeoDE (1000 - 2000 images per region) are added to a training dataset. We release the full dataset and code at https://geodiverse-data-collection.cs.princeton.edu/
Overlooked factors in concept-based explanations: Dataset choice, concept salience, and human capability
Jul 20, 2022

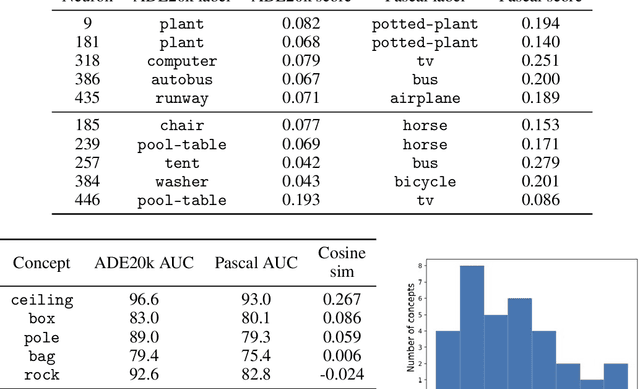
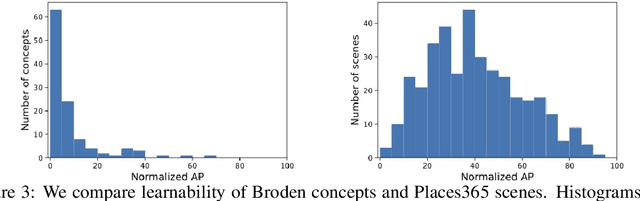
Concept-based interpretability methods aim to explain deep neural network model predictions using a predefined set of semantic concepts. These methods evaluate a trained model on a new, "probe" dataset and correlate model predictions with the visual concepts labeled in that dataset. Despite their popularity, they suffer from limitations that are not well-understood and articulated by the literature. In this work, we analyze three commonly overlooked factors in concept-based explanations. First, the choice of the probe dataset has a profound impact on the generated explanations. Our analysis reveals that different probe datasets may lead to very different explanations, and suggests that the explanations are not generalizable outside the probe dataset. Second, we find that concepts in the probe dataset are often less salient and harder to learn than the classes they claim to explain, calling into question the correctness of the explanations. We argue that only visually salient concepts should be used in concept-based explanations. Finally, while existing methods use hundreds or even thousands of concepts, our human studies reveal a much stricter upper bound of 32 concepts or less, beyond which the explanations are much less practically useful. We make suggestions for future development and analysis of concept-based interpretability methods. Code for our analysis and user interface can be found at \url{https://github.com/princetonvisualai/OverlookedFactors}
Gender Artifacts in Visual Datasets
Jun 18, 2022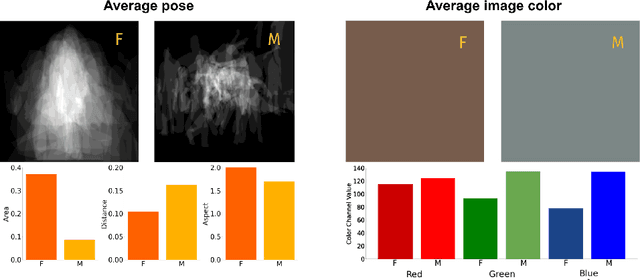

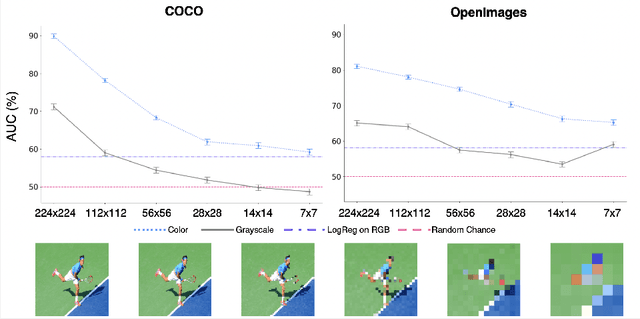
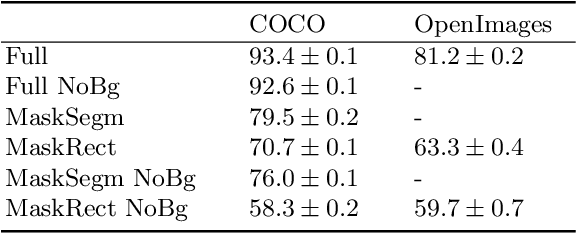
Gender biases are known to exist within large-scale visual datasets and can be reflected or even amplified in downstream models. Many prior works have proposed methods for mitigating gender biases, often by attempting to remove gender expression information from images. To understand the feasibility and practicality of these approaches, we investigate what $\textit{gender artifacts}$ exist within large-scale visual datasets. We define a $\textit{gender artifact}$ as a visual cue that is correlated with gender, focusing specifically on those cues that are learnable by a modern image classifier and have an interpretable human corollary. Through our analyses, we find that gender artifacts are ubiquitous in the COCO and OpenImages datasets, occurring everywhere from low-level information (e.g., the mean value of the color channels) to the higher-level composition of the image (e.g., pose and location of people). Given the prevalence of gender artifacts, we claim that attempts to remove gender artifacts from such datasets are largely infeasible. Instead, the responsibility lies with researchers and practitioners to be aware that the distribution of images within datasets is highly gendered and hence develop methods which are robust to these distributional shifts across groups.
ELUDE: Generating interpretable explanations via a decomposition into labelled and unlabelled features
Jun 16, 2022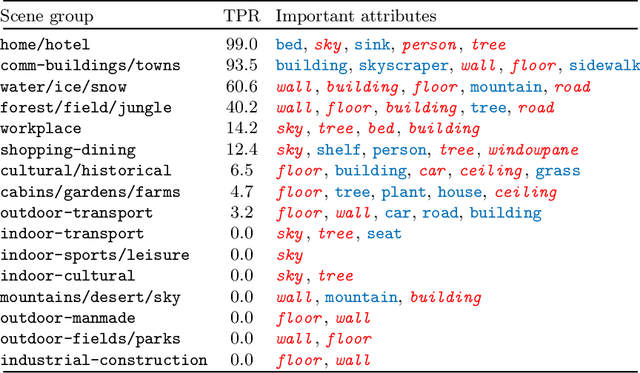
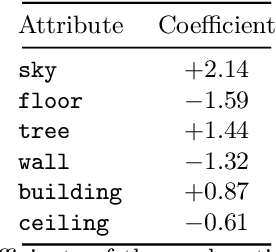
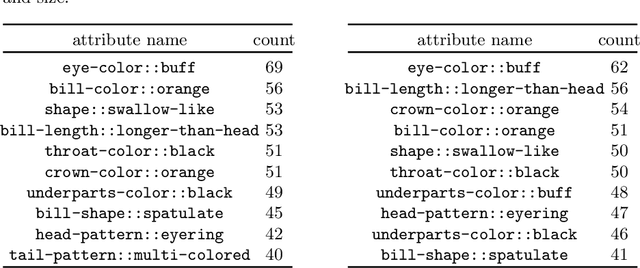

Deep learning models have achieved remarkable success in different areas of machine learning over the past decade; however, the size and complexity of these models make them difficult to understand. In an effort to make them more interpretable, several recent works focus on explaining parts of a deep neural network through human-interpretable, semantic attributes. However, it may be impossible to completely explain complex models using only semantic attributes. In this work, we propose to augment these attributes with a small set of uninterpretable features. Specifically, we develop a novel explanation framework ELUDE (Explanation via Labelled and Unlabelled DEcomposition) that decomposes a model's prediction into two parts: one that is explainable through a linear combination of the semantic attributes, and another that is dependent on the set of uninterpretable features. By identifying the latter, we are able to analyze the "unexplained" portion of the model, obtaining insights into the information used by the model. We show that the set of unlabelled features can generalize to multiple models trained with the same feature space and compare our work to two popular attribute-oriented methods, Interpretable Basis Decomposition and Concept Bottleneck, and discuss the additional insights ELUDE provides.
Towards Intersectionality in Machine Learning: Including More Identities, Handling Underrepresentation, and Performing Evaluation
May 10, 2022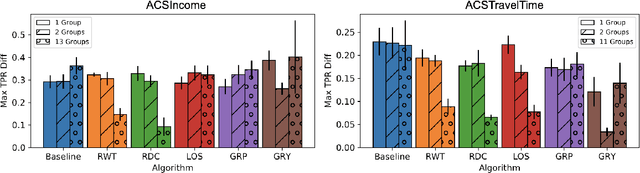
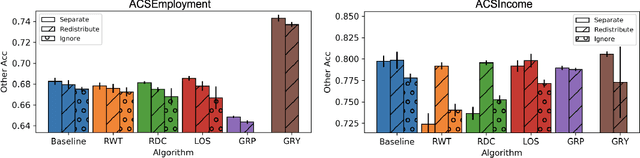
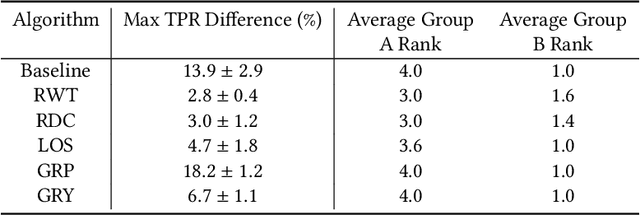
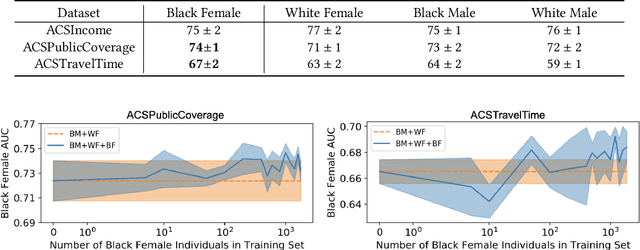
Research in machine learning fairness has historically considered a single binary demographic attribute; however, the reality is of course far more complicated. In this work, we grapple with questions that arise along three stages of the machine learning pipeline when incorporating intersectionality as multiple demographic attributes: (1) which demographic attributes to include as dataset labels, (2) how to handle the progressively smaller size of subgroups during model training, and (3) how to move beyond existing evaluation metrics when benchmarking model fairness for more subgroups. For each question, we provide thorough empirical evaluation on tabular datasets derived from the US Census, and present constructive recommendations for the machine learning community. First, we advocate for supplementing domain knowledge with empirical validation when choosing which demographic attribute labels to train on, while always evaluating on the full set of demographic attributes. Second, we warn against using data imbalance techniques without considering their normative implications and suggest an alternative using the structure in the data. Third, we introduce new evaluation metrics which are more appropriate for the intersectional setting. Overall, we provide substantive suggestions on three necessary (albeit not sufficient!) considerations when incorporating intersectionality into machine learning.
HIVE: Evaluating the Human Interpretability of Visual Explanations
Jan 10, 2022
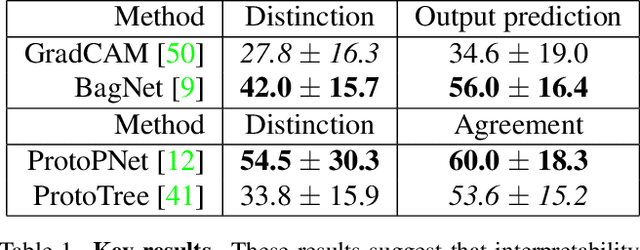

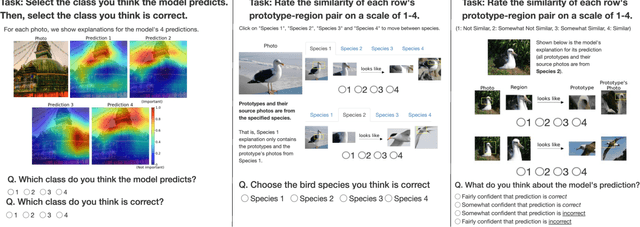
As machine learning is increasingly applied to high-impact, high-risk domains, there have been a number of new methods aimed at making AI models more human interpretable. Despite the recent growth of interpretability work, there is a lack of systematic evaluation of proposed techniques. In this work, we propose a novel human evaluation framework HIVE (Human Interpretability of Visual Explanations) for diverse interpretability methods in computer vision; to the best of our knowledge, this is the first work of its kind. We argue that human studies should be the gold standard in properly evaluating how interpretable a method is to human users. While human studies are often avoided due to challenges associated with cost, study design, and cross-method comparison, we describe how our framework mitigates these issues and conduct IRB-approved studies of four methods that represent the diversity of interpretability works: GradCAM, BagNet, ProtoPNet, and ProtoTree. Our results suggest that explanations (regardless of if they are actually correct) engender human trust, yet are not distinct enough for users to distinguish between correct and incorrect predictions. Lastly, we also open-source our framework to enable future studies and to encourage more human-centered approaches to interpretability.