 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplain Like I'm 5 or Whatever I Choose: Evaluating the Interactive Potential of Language Model Responses
Jun 05, 2026Evaluations of large language models (LLMs) in scientific information seeking tasks have become increasingly use-centric, such as conducting live or multi-turn evaluations with real users. These evaluations still assume a single, static chat interface, but as models are integrated into new interfaces, evaluations must shift to incorporate interface-specific criteria. We propose a new evaluation framework based on a formative study with $16$ participants that tests models' ability to generate multiple responses to one query that differ along an interpretable axis of language (language complexity), inspired by direct manipulation interfaces from human-centered design literature. We evaluate GPT-5.1, GPT-5 mini, Claude Sonnet 4.5 + Thinking, and DeepSeek-V3.1 by generating 5 responses at different levels of language complexity for $98$ scientific queries. While models vary complexity across responses, most changes remain inconsistent, with the best performing model (Claude Sonnet 4.5) only shifting reliable complexity measures in the correct direction $46\%$ of the time. Our findings hold with increased sample size and alternative complexity levels.
Interactivity x Explainability: Toward Understanding How Interactivity Can Improve Computer Vision Explanations
Apr 14, 2025Explanations for computer vision models are important tools for interpreting how the underlying models work. However, they are often presented in static formats, which pose challenges for users, including information overload, a gap between semantic and pixel-level information, and limited opportunities for exploration. We investigate interactivity as a mechanism for tackling these issues in three common explanation types: heatmap-based, concept-based, and prototype-based explanations. We conducted a study (N=24), using a bird identification task, involving participants with diverse technical and domain expertise. We found that while interactivity enhances user control, facilitates rapid convergence to relevant information, and allows users to expand their understanding of the model and explanation, it also introduces new challenges. To address these, we provide design recommendations for interactive computer vision explanations, including carefully selected default views, independent input controls, and constrained output spaces.
Comparing Importance Sampling Based Methods for Mitigating the Effect of Class Imbalance
Feb 28, 2024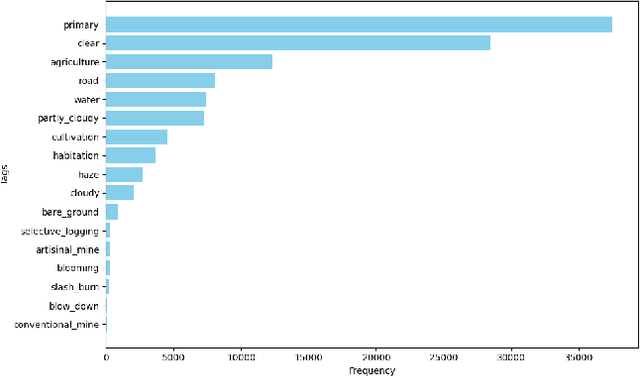
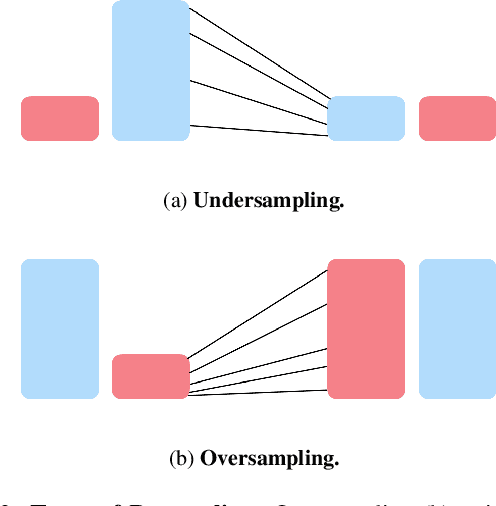
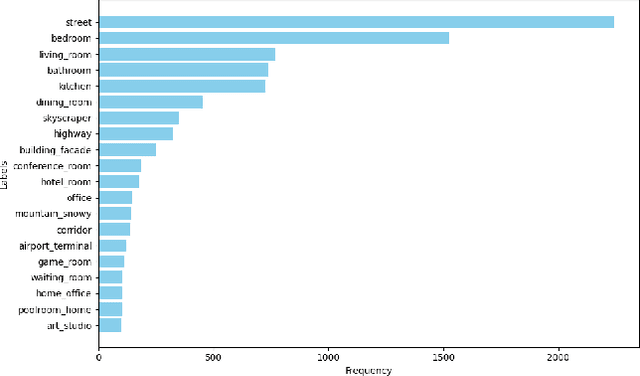

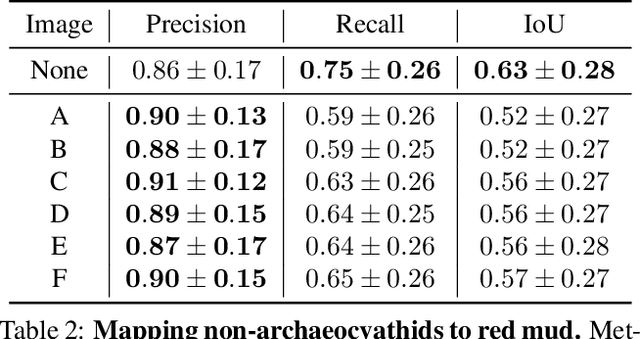
Most state-of-the-art computer vision models heavily depend on data. However, many datasets exhibit extreme class imbalance which has been shown to negatively impact model performance. Among the training-time and data-generation solutions that have been explored, one subset that leverages existing data is importance sampling. A good deal of this work focuses primarily on the CIFAR-10 and CIFAR-100 datasets which fail to be representative of the scale, composition, and complexity of current state-of-the-art datasets. In this work, we explore and compare three techniques that derive from importance sampling: loss reweighting, undersampling, and oversampling. Specifically, we compare the effect of these techniques on the performance of two encoders on an impactful satellite imagery dataset, Planet's Amazon Rainforest dataset, in preparation for another work. Furthermore, we perform supplemental experimentation on a scene classification dataset, ADE20K, to test on a contrasting domain and clarify our results. Across both types of encoders, we find that up-weighting the loss for and undersampling has a negigible effect on the performance on underrepresented classes. Additionally, our results suggest oversampling generally improves performance for the same underrepresented classes. Interestingly, our findings also indicate that there may exist some redundancy in data in the Planet dataset. Our work aims to provide a foundation for further work on the Planet dataset and similar domain-specific datasets. We open-source our code at https://github.com/RichardZhu123/514-class-imbalance for future work on other satellite imagery datasets as well.
Improving Fine-Grain Segmentation via Interpretable Modifications: A Case Study in Fossil Segmentation
Oct 08, 2022
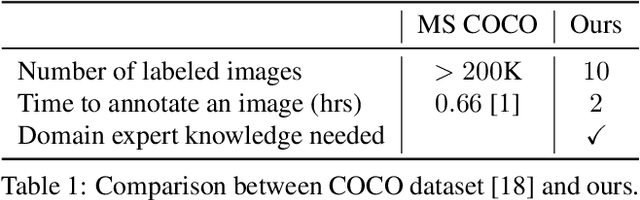
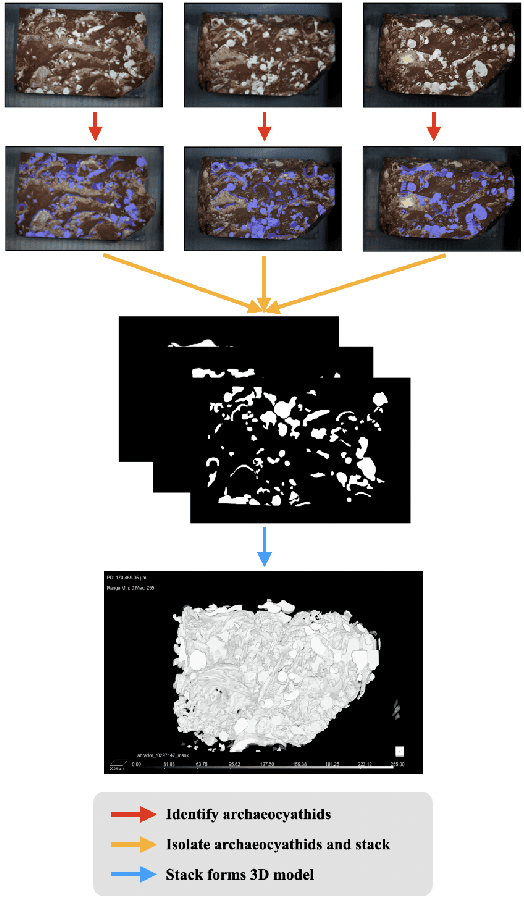
Most interpretability research focuses on datasets containing thousands of images of commonplace objects. However, many high-impact datasets, such as those in medicine and the geosciences, contain fine-grain objects that require domain-expert knowledge to recognize and are time-consuming to collect and annotate. As a result, these datasets contain few annotated images, and current machine vision models cannot train intensively on them. Thus, adapting interpretability techniques to maximize the amount of information that models can learn from small, fine-grain datasets is an important endeavor. Using a Mask R-CNN to segment ancient reef fossils in rock sample images, we present a general paradigm for identifying and mitigating model weaknesses. Specifically, we apply image perturbations to expose the Mask R-CNN's inability to distinguish between different classes of fossils and its inconsistency in segmenting fossils with different textures. To address these shortcomings, we extend an existing model-editing method for correcting systematic mistakes in image classification to image segmentation and introduce a novel application of the technique: encouraging a greater separation between positive and negative pixels for a given class. Through extensive experiments, we find that editing the model by perturbing all pixels for a given class in one image is most effective (compared to using multiple images and/or fewer pixels). Our paradigm may also generalize to other segmentation models trained on small, fine-grain datasets.
Leveraging Structure from Motion to Localize Inaccessible Bus Stops
Oct 07, 2022
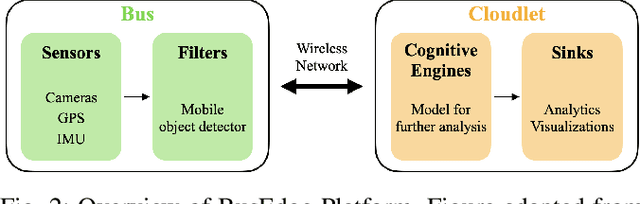

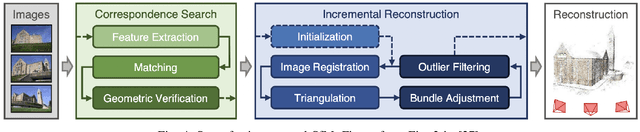
The detection of hazardous conditions near public transit stations is necessary for ensuring the safety and accessibility of public transit. Smart city infrastructures aim to facilitate this task among many others through the use of computer vision. However, most state-of-the-art computer vision models require thousands of images in order to perform accurate detection, and there exist few images of hazardous conditions as they are generally rare. In this paper, we examine the detection of snow-covered sidewalks along bus routes. Previous work has focused on detecting other vehicles in heavy snowfall or simply detecting the presence of snow. However, our application has an added complication of determining if the snow covers areas of importance and can cause falls or other accidents (e.g. snow covering a sidewalk) or simply covers some background area (e.g. snow on a neighboring field). This problem involves localizing the positions of the areas of importance when they are not necessarily visible. We introduce a method that utilizes Structure from Motion (SfM) rather than additional annotated data to address this issue. Specifically, our method learns the locations of sidewalks in a given scene by applying a segmentation model and SfM to images from bus cameras during clear weather. Then, we use the learned locations to detect if and where the sidewalks become obscured with snow. After evaluating across various threshold parameters, we identify an optimal range at which our method consistently classifies different categories of sidewalk images correctly. Although we demonstrate an application for snow coverage along bus routes, this method can extend to other hazardous conditions as well. Code for this project is available at https://github.com/ind1010/SfM_for_BusEdge.