 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROADWork Dataset: Learning to Recognize, Observe, Analyze and Drive Through Work Zones
Jun 11, 2024



Perceiving and navigating through work zones is challenging and under-explored, even with major strides in self-driving research. An important reason is the lack of open datasets for developing new algorithms to address this long-tailed scenario. We propose the ROADWork dataset to learn how to recognize, observe and analyze and drive through work zones. We find that state-of-the-art foundation models perform poorly on work zones. With our dataset, we improve upon detecting work zone objects (+26.2 AP), while discovering work zones with higher precision (+32.5%) at a much higher discovery rate (12.8 times), significantly improve detecting (+23.9 AP) and reading (+14.2% 1-NED) work zone signs and describing work zones (+36.7 SPICE). We also compute drivable paths from work zone navigation videos and show that it is possible to predict navigational goals and pathways such that 53.6% goals have angular error (AE) < 0.5 degrees (+9.9 %) and 75.3% pathways have AE < 0.5 degrees (+8.1 %).
Enhancing Visual Domain Adaptation with Source Preparation
Jun 16, 2023Robotic Perception in diverse domains such as low-light scenarios, where new modalities like thermal imaging and specialized night-vision sensors are increasingly employed, remains a challenge. Largely, this is due to the limited availability of labeled data. Existing Domain Adaptation (DA) techniques, while promising to leverage labels from existing well-lit RGB images, fail to consider the characteristics of the source domain itself. We holistically account for this factor by proposing Source Preparation (SP), a method to mitigate source domain biases. Our Almost Unsupervised Domain Adaptation (AUDA) framework, a label-efficient semi-supervised approach for robotic scenarios -- employs Source Preparation (SP), Unsupervised Domain Adaptation (UDA) and Supervised Alignment (SA) from limited labeled data. We introduce CityIntensified, a novel dataset comprising temporally aligned image pairs captured from a high-sensitivity camera and an intensifier camera for semantic segmentation and object detection in low-light settings. We demonstrate the effectiveness of our method in semantic segmentation, with experiments showing that SP enhances UDA across a range of visual domains, with improvements up to 40.64% in mIoU over baseline, while making target models more robust to real-world shifts within the target domain. We show that AUDA is a label-efficient framework for effective DA, significantly improving target domain performance with only tens of labeled samples from the target domain.
Learned Two-Plane Perspective Prior based Image Resampling for Efficient Object Detection
Mar 25, 2023Real-time efficient perception is critical for autonomous navigation and city scale sensing. Orthogonal to architectural improvements, streaming perception approaches have exploited adaptive sampling improving real-time detection performance. In this work, we propose a learnable geometry-guided prior that incorporates rough geometry of the 3D scene (a ground plane and a plane above) to resample images for efficient object detection. This significantly improves small and far-away object detection performance while also being more efficient both in terms of latency and memory. For autonomous navigation, using the same detector and scale, our approach improves detection rate by +4.1 $AP_{S}$ or +39% and in real-time performance by +5.3 $sAP_{S}$ or +63% for small objects over state-of-the-art (SOTA). For fixed traffic cameras, our approach detects small objects at image scales other methods cannot. At the same scale, our approach improves detection of small objects by 195% (+12.5 $AP_{S}$) over naive-downsampling and 63% (+4.2 $AP_{S}$) over SOTA.
Leveraging Structure from Motion to Localize Inaccessible Bus Stops
Oct 07, 2022
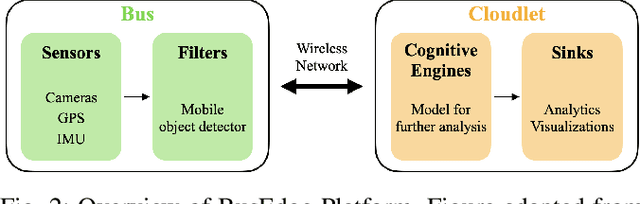

The detection of hazardous conditions near public transit stations is necessary for ensuring the safety and accessibility of public transit. Smart city infrastructures aim to facilitate this task among many others through the use of computer vision. However, most state-of-the-art computer vision models require thousands of images in order to perform accurate detection, and there exist few images of hazardous conditions as they are generally rare. In this paper, we examine the detection of snow-covered sidewalks along bus routes. Previous work has focused on detecting other vehicles in heavy snowfall or simply detecting the presence of snow. However, our application has an added complication of determining if the snow covers areas of importance and can cause falls or other accidents (e.g. snow covering a sidewalk) or simply covers some background area (e.g. snow on a neighboring field). This problem involves localizing the positions of the areas of importance when they are not necessarily visible. We introduce a method that utilizes Structure from Motion (SfM) rather than additional annotated data to address this issue. Specifically, our method learns the locations of sidewalks in a given scene by applying a segmentation model and SfM to images from bus cameras during clear weather. Then, we use the learned locations to detect if and where the sidewalks become obscured with snow. After evaluating across various threshold parameters, we identify an optimal range at which our method consistently classifies different categories of sidewalk images correctly. Although we demonstrate an application for snow coverage along bus routes, this method can extend to other hazardous conditions as well. Code for this project is available at https://github.com/ind1010/SfM_for_BusEdge.
Multimodal Object Detection via Bayesian Fusion
Apr 07, 2021
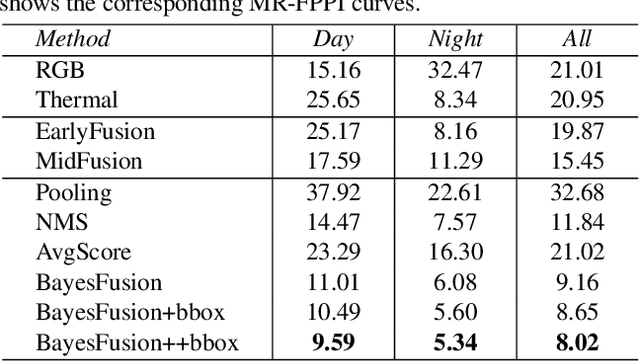


Object detection with multimodal inputs can improve many safety-critical perception systems such as autonomous vehicles (AVs). Motivated by AVs that operate in both day and night, we study multimodal object detection with RGB and thermal cameras, since the latter can provide much stronger object signatures under poor illumination. We explore strategies for fusing information from different modalities. Our key contribution is a non-learned late-fusion method that fuses together bounding box detections from different modalities via a simple probabilistic model derived from first principles. Our simple approach, which we call Bayesian Fusion, is readily derived from conditional independence assumptions across different modalities. We apply our approach to benchmarks containing both aligned (KAIST) and unaligned (FLIR) multimodal sensor data. Our Bayesian Fusion outperforms prior work by more than 13% in relative performance.
Depth Completion via Inductive Fusion of Planar LIDAR and Monocular Camera
Sep 03, 2020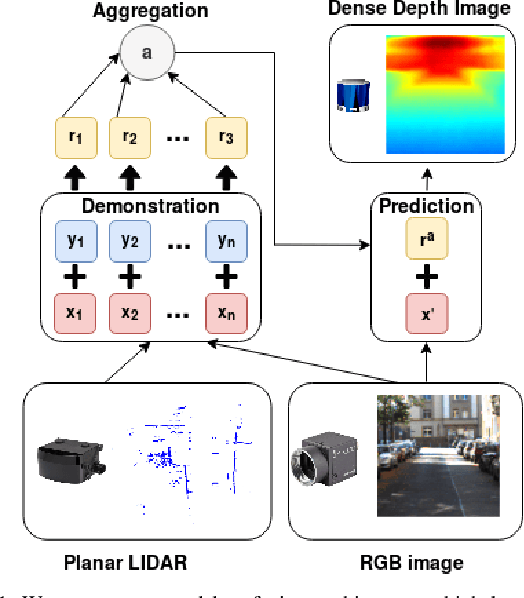
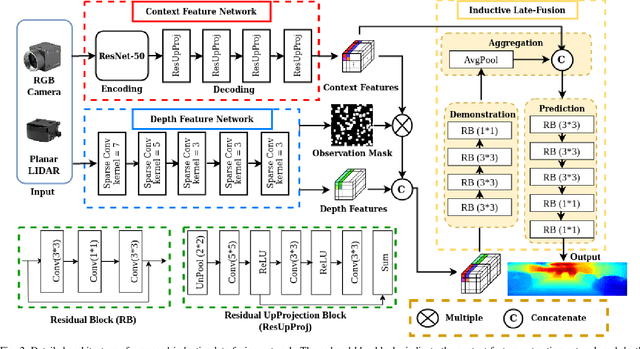
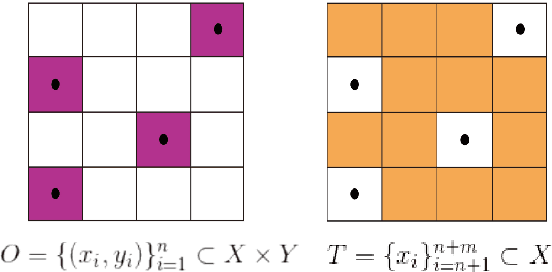
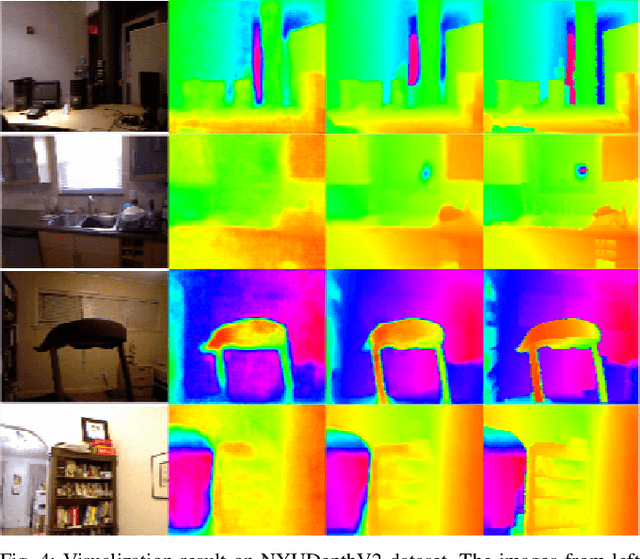
Modern high-definition LIDAR is expensive for commercial autonomous driving vehicles and small indoor robots. An affordable solution to this problem is fusion of planar LIDAR with RGB images to provide a similar level of perception capability. Even though state-of-the-art methods provide approaches to predict depth information from limited sensor input, they are usually a simple concatenation of sparse LIDAR features and dense RGB features through an end-to-end fusion architecture. In this paper, we introduce an inductive late-fusion block which better fuses different sensor modalities inspired by a probability model. The proposed demonstration and aggregation network propagates the mixed context and depth features to the prediction network and serves as a prior knowledge of the depth completion. This late-fusion block uses the dense context features to guide the depth prediction based on demonstrations by sparse depth features. In addition to evaluating the proposed method on benchmark depth completion datasets including NYUDepthV2 and KITTI, we also test the proposed method on a simulated planar LIDAR dataset. Our method shows promising results compared to previous approaches on both the benchmark datasets and simulated dataset with various 3D densities.
DeepDA: LSTM-based Deep Data Association Network for Multi-Targets Tracking in Clutter
Jul 16, 2019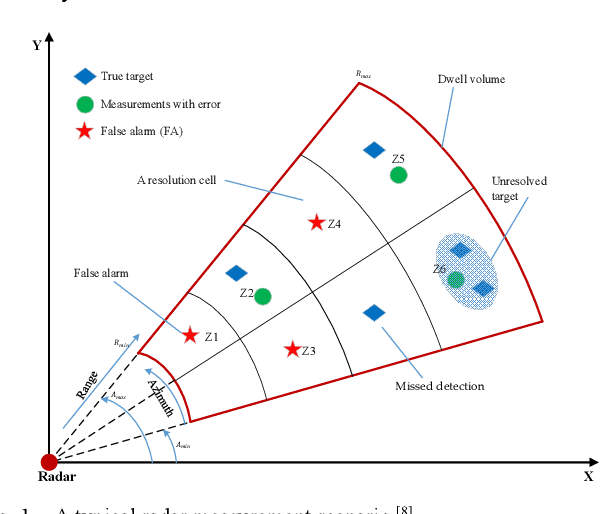
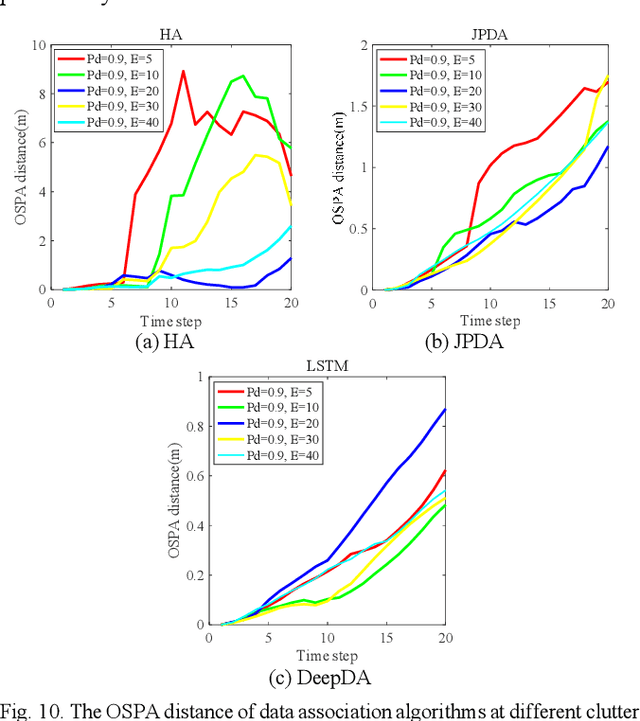
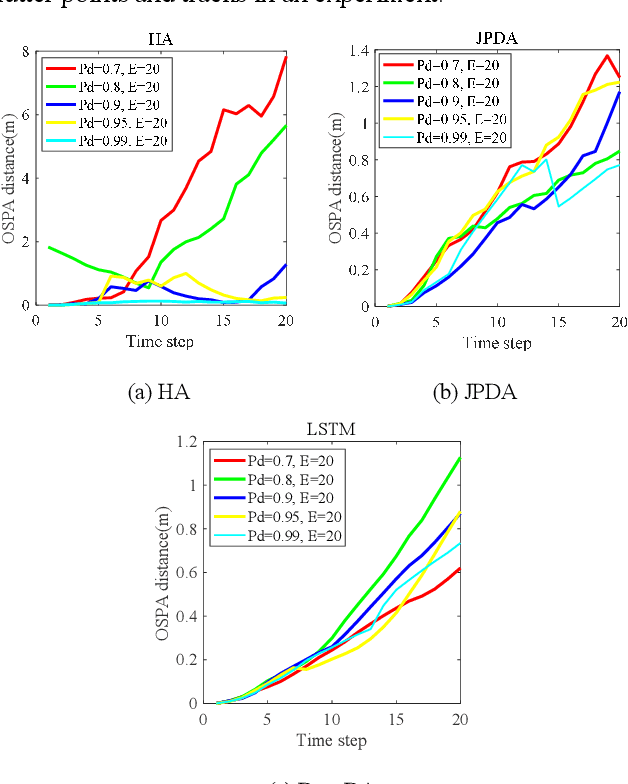

The Long Short-Term Memory (LSTM) neural network based data association algorithm named as DeepDA for multi-target tracking in clutters is proposed to deal with the NP-hard combinatorial optimization problem in this paper. Different from the classical data association methods involving complex models and accurate prior knowledge on clutter density, filter covariance or associated gating etc, data-driven deep learning methods have been extensively researched for this topic. Firstly, data association mathematical problem for multitarget tracking on unknown target number, missed detection and clutter, which is beyond one-to-one mapping between observations and targets is redefined formally. Subsequently, an LSTM network is designed to learn the measurement-to-track association probability from radar noisy measurements and exist tracks. Moreover, an LSTM-based data-driven deep neural network after a supervised training through the BPTT and RMSprop optimization method can get the association probability directly. Experimental results on simulated data show a significant performance on association ratio, target ID switching and time-consuming for tracking multiple targets even they are crossing each other in the complicated clutter environment.
Learning Unsupervised Multi-View Stereopsis via Robust Photometric Consistency
Jun 06, 2019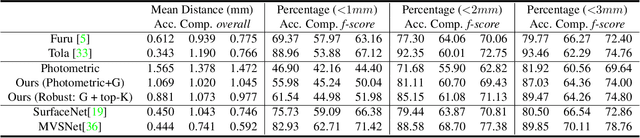
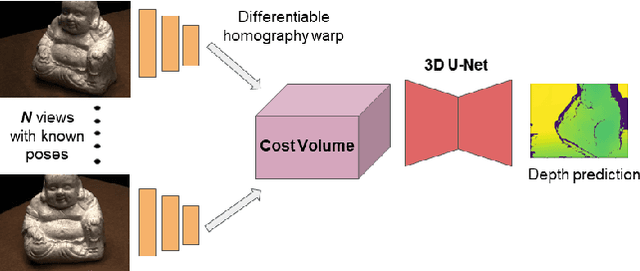
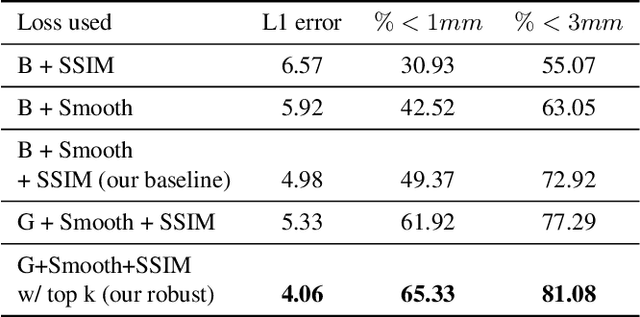
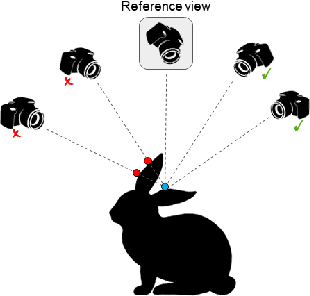
We present a learning based approach for multi-view stereopsis (MVS). While current deep MVS methods achieve impressive results, they crucially rely on ground-truth 3D training data, and acquisition of such precise 3D geometry for supervision is a major hurdle. Our framework instead leverages photometric consistency between multiple views as supervisory signal for learning depth prediction in a wide baseline MVS setup. However, naively applying photo consistency constraints is undesirable due to occlusion and lighting changes across views. To overcome this, we propose a robust loss formulation that: a) enforces first order consistency and b) for each point, selectively enforces consistency with some views, thus implicitly handling occlusions. We demonstrate our ability to learn MVS without 3D supervision using a real dataset, and show that each component of our proposed robust loss results in a significant improvement. We qualitatively observe that our reconstructions are often more complete than the acquired ground truth, further showing the merits of this approach. Lastly, our learned model generalizes to novel settings, and our approach allows adaptation of existing CNNs to datasets without ground-truth 3D by unsupervised finetuning. Project webpage: https://tejaskhot.github.io/unsup_mvs
Iterative Transformer Network for 3D Point Cloud
Nov 27, 2018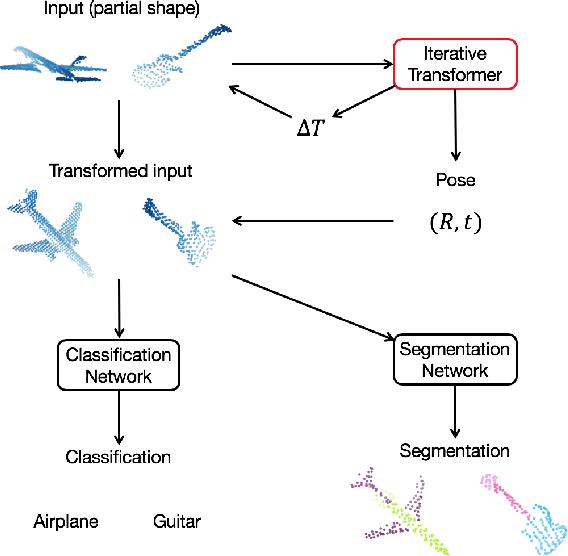
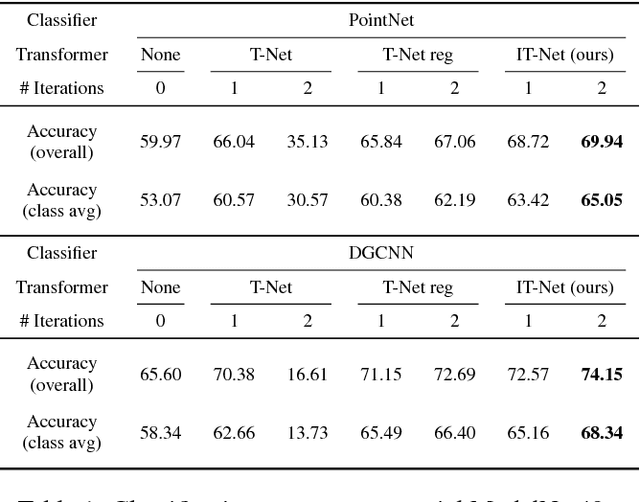


3D point cloud is an efficient and flexible representation of 3D structures. Recently, neural networks operating on point clouds have shown superior performance on tasks such as shape classification and part segmentation. However, performance on these tasks are evaluated using complete, aligned shapes, while real world 3D data are partial and unaligned. A key challenge in learning from unaligned point cloud data is how to attain invariance or equivariance with respect to geometric transformations. To address this challenge, we propose a novel transformer network that operates on 3D point clouds, named Iterative Transformer Network (IT-Net). Different from existing transformer networks, IT-Net predicts a 3D rigid transformation using an iterative refinement scheme inspired by classical image and point cloud alignment algorithms. We demonstrate that models using IT-Net achieves superior performance over baselines on the classification and segmentation of partial, unaligned 3D shapes. Further, we provide an analysis on the efficacy of the iterative refinement scheme on estimating accurate object poses from partial observations.
PCN: Point Completion Network
Aug 05, 2018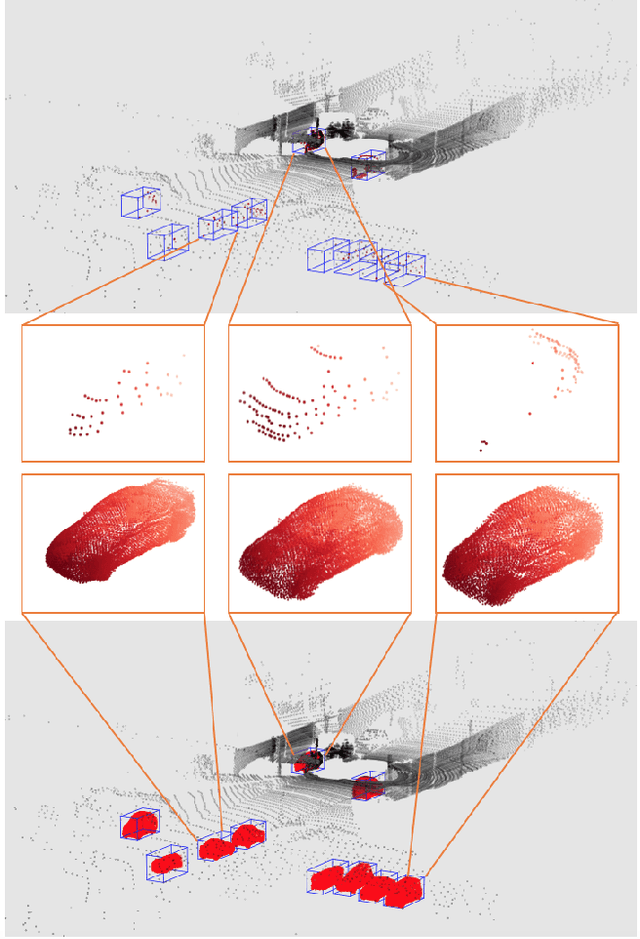

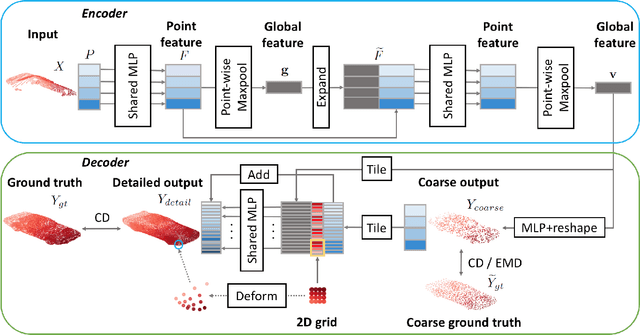

Shape completion, the problem of estimating the complete geometry of objects from partial observations, lies at the core of many vision and robotics applications. In this work, we propose Point Completion Network (PCN), a novel learning-based approach for shape completion. Unlike existing shape completion methods, PCN directly operates on raw point clouds without any structural assumption (e.g. symmetry) or annotation (e.g. semantic class) about the underlying shape. It features a decoder design that enables the generation of fine-grained completions while maintaining a small number of parameters. Our experiments show that PCN produces dense, complete point clouds with realistic structures in the missing regions on inputs with various levels of incompleteness and noise, including cars from LiDAR scans in the KITTI dataset.