 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging State Space Models in Long Range Genomics
Apr 07, 2025



Long-range dependencies are critical for understanding genomic structure and function, yet most conventional methods struggle with them. Widely adopted transformer-based models, while excelling at short-context tasks, are limited by the attention module's quadratic computational complexity and inability to extrapolate to sequences longer than those seen in training. In this work, we explore State Space Models (SSMs) as a promising alternative by benchmarking two SSM-inspired architectures, Caduceus and Hawk, on long-range genomics modeling tasks under conditions parallel to a 50M parameter transformer baseline. We discover that SSMs match transformer performance and exhibit impressive zero-shot extrapolation across multiple tasks, handling contexts 10 to 100 times longer than those seen during training, indicating more generalizable representations better suited for modeling the long and complex human genome. Moreover, we demonstrate that these models can efficiently process sequences of 1M tokens on a single GPU, allowing for modeling entire genomic regions at once, even in labs with limited compute. Our findings establish SSMs as efficient and scalable for long-context genomic analysis.
Enhancing Visual Domain Adaptation with Source Preparation
Jun 16, 2023Robotic Perception in diverse domains such as low-light scenarios, where new modalities like thermal imaging and specialized night-vision sensors are increasingly employed, remains a challenge. Largely, this is due to the limited availability of labeled data. Existing Domain Adaptation (DA) techniques, while promising to leverage labels from existing well-lit RGB images, fail to consider the characteristics of the source domain itself. We holistically account for this factor by proposing Source Preparation (SP), a method to mitigate source domain biases. Our Almost Unsupervised Domain Adaptation (AUDA) framework, a label-efficient semi-supervised approach for robotic scenarios -- employs Source Preparation (SP), Unsupervised Domain Adaptation (UDA) and Supervised Alignment (SA) from limited labeled data. We introduce CityIntensified, a novel dataset comprising temporally aligned image pairs captured from a high-sensitivity camera and an intensifier camera for semantic segmentation and object detection in low-light settings. We demonstrate the effectiveness of our method in semantic segmentation, with experiments showing that SP enhances UDA across a range of visual domains, with improvements up to 40.64% in mIoU over baseline, while making target models more robust to real-world shifts within the target domain. We show that AUDA is a label-efficient framework for effective DA, significantly improving target domain performance with only tens of labeled samples from the target domain.
BirdSLAM: Monocular Multibody SLAM in Bird's-Eye View
Nov 15, 2020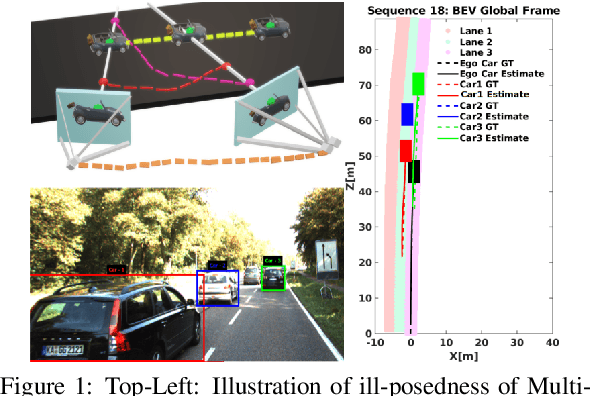
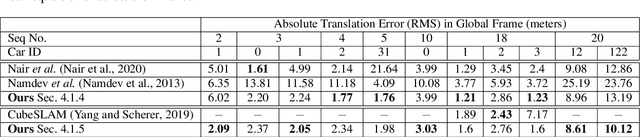
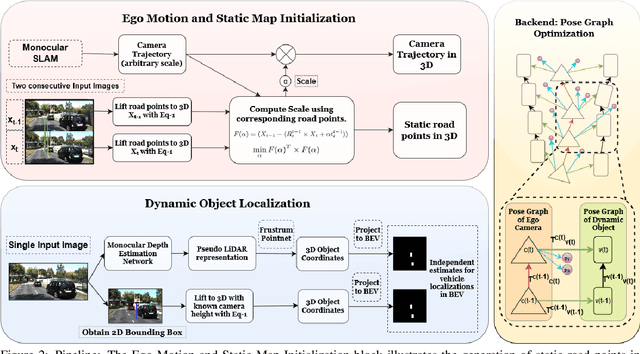
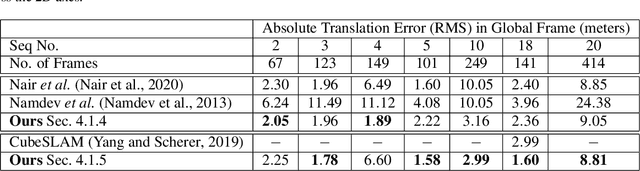
In this paper, we present BirdSLAM, a novel simultaneous localization and mapping (SLAM) system for the challenging scenario of autonomous driving platforms equipped with only a monocular camera. BirdSLAM tackles challenges faced by other monocular SLAM systems (such as scale ambiguity in monocular reconstruction, dynamic object localization, and uncertainty in feature representation) by using an orthographic (bird's-eye) view as the configuration space in which localization and mapping are performed. By assuming only the height of the ego-camera above the ground, BirdSLAM leverages single-view metrology cues to accurately localize the ego-vehicle and all other traffic participants in bird's-eye view. We demonstrate that our system outperforms prior work that uses strictly greater information, and highlight the relevance of each design decision via an ablation analysis.
Multi-object Monocular SLAM for Dynamic Environments
Feb 10, 2020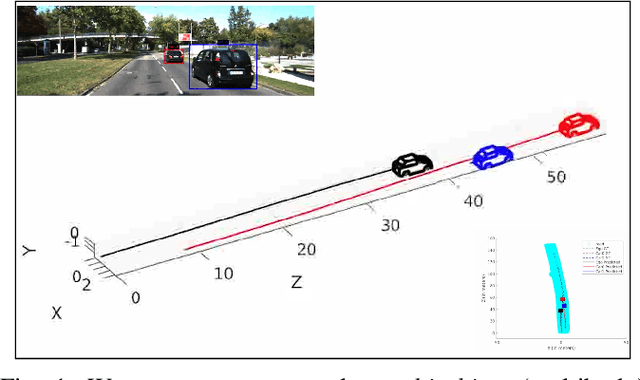
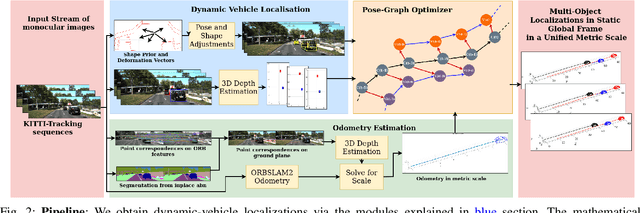
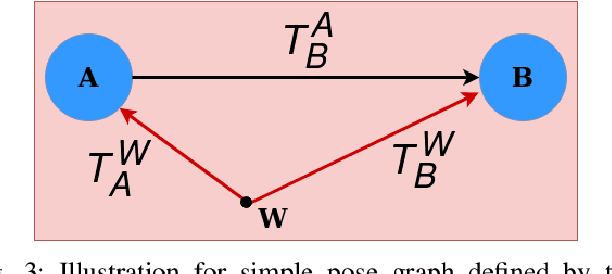
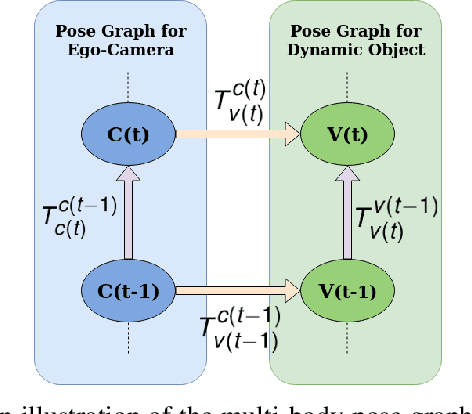
Multibody monocular SLAM in dynamic environments remains a long-standing challenge in terms of perception and state estimation. Although theoretical solutions exist, practice lags behind, predominantly due to the lack of robust perceptual and predictive models of dynamic participants. The quintessential challenge in Multi-body monocular SLAM in dynamic scenes stems from the problem of unobservability as it is not possible to triangulate a moving object from a moving monocular camera. Under restrictions of object motion the problem can be solved, however even here one is entailed to solve for the single family solution to the relative scale problem. The relative scale problem exists since the dynamic objects that get reconstructed with the monocular camera have a different scale vis a vis the scale space in which the stationary scene is reconstructed. We solve this rather intractable problem by reconstructing dynamic vehicles/participants in single view in metric scale through an object SLAM pipeline. Further, we lift the ego vehicle trajectory obtained from Monocular ORB-SLAM also into metric scales making use of ground plane features thereby resolving the relative scale problem. We present a multi pose-graph optimization formulation to estimate the pose and track dynamic objects in the environment. This optimization helps us reduce the average error in trajectories of multiple bodies in KITTI Tracking sequences. To the best of our knowledge, our method is the first practical monocular multi-body SLAM system to perform dynamic multi-object and ego localization in a unified framework in metric scale.