 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAD-LAD: Rule and Language Grounded Autonomous Driving in Real-Time
Mar 31, 2026We present LAD, a real-time language--action planner with an interruptible architecture that produces a motion plan in a single forward pass (~20 Hz) or generates textual reasoning alongside a motion plan (~10 Hz). LAD is fast enough for real-time closed-loop deployment, achieving ~3x lower latency than prior driving language models while setting a new learning-based state of the art on nuPlan Test14-Hard and InterPlan. We also introduce RAD, a rule-based planner designed to address structural limitations of PDM-Closed. RAD achieves state-of-the-art performance among rule-based planners on nuPlan Test14-Hard and InterPlan. Finally, we show that combining RAD and LAD enables hybrid planning that captures the strengths of both approaches. This hybrid system demonstrates that rules and learning provide complementary capabilities: rules support reliable maneuvering, while language enables adaptive and explainable decision-making.
AerialMegaDepth: Learning Aerial-Ground Reconstruction and View Synthesis
Apr 17, 2025We explore the task of geometric reconstruction of images captured from a mixture of ground and aerial views. Current state-of-the-art learning-based approaches fail to handle the extreme viewpoint variation between aerial-ground image pairs. Our hypothesis is that the lack of high-quality, co-registered aerial-ground datasets for training is a key reason for this failure. Such data is difficult to assemble precisely because it is difficult to reconstruct in a scalable way. To overcome this challenge, we propose a scalable framework combining pseudo-synthetic renderings from 3D city-wide meshes (e.g., Google Earth) with real, ground-level crowd-sourced images (e.g., MegaDepth). The pseudo-synthetic data simulates a wide range of aerial viewpoints, while the real, crowd-sourced images help improve visual fidelity for ground-level images where mesh-based renderings lack sufficient detail, effectively bridging the domain gap between real images and pseudo-synthetic renderings. Using this hybrid dataset, we fine-tune several state-of-the-art algorithms and achieve significant improvements on real-world, zero-shot aerial-ground tasks. For example, we observe that baseline DUSt3R localizes fewer than 5% of aerial-ground pairs within 5 degrees of camera rotation error, while fine-tuning with our data raises accuracy to nearly 56%, addressing a major failure point in handling large viewpoint changes. Beyond camera estimation and scene reconstruction, our dataset also improves performance on downstream tasks like novel-view synthesis in challenging aerial-ground scenarios, demonstrating the practical value of our approach in real-world applications.
ROADWork Dataset: Learning to Recognize, Observe, Analyze and Drive Through Work Zones
Jun 11, 2024



Perceiving and navigating through work zones is challenging and under-explored, even with major strides in self-driving research. An important reason is the lack of open datasets for developing new algorithms to address this long-tailed scenario. We propose the ROADWork dataset to learn how to recognize, observe and analyze and drive through work zones. We find that state-of-the-art foundation models perform poorly on work zones. With our dataset, we improve upon detecting work zone objects (+26.2 AP), while discovering work zones with higher precision (+32.5%) at a much higher discovery rate (12.8 times), significantly improve detecting (+23.9 AP) and reading (+14.2% 1-NED) work zone signs and describing work zones (+36.7 SPICE). We also compute drivable paths from work zone navigation videos and show that it is possible to predict navigational goals and pathways such that 53.6% goals have angular error (AE) < 0.5 degrees (+9.9 %) and 75.3% pathways have AE < 0.5 degrees (+8.1 %).
Addressing Source Scale Bias via Image Warping for Domain Adaptation
Mar 19, 2024



In visual recognition, scale bias is a key challenge due to the imbalance of object and image size distribution inherent in real scene datasets. Conventional solutions involve injecting scale invariance priors, oversampling the dataset at different scales during training, or adjusting scale at inference. While these strategies mitigate scale bias to some extent, their ability to adapt across diverse datasets is limited. Besides, they increase computational load during training and latency during inference. In this work, we use adaptive attentional processing -- oversampling salient object regions by warping images in-place during training. Discovering that shifting the source scale distribution improves backbone features, we developed a instance-level warping guidance aimed at object region sampling to mitigate source scale bias in domain adaptation. Our approach improves adaptation across geographies, lighting and weather conditions, is agnostic to the task, domain adaptation algorithm, saliency guidance, and underlying model architecture. Highlights include +6.1 mAP50 for BDD100K Clear $\rightarrow$ DENSE Foggy, +3.7 mAP50 for BDD100K Day $\rightarrow$ Night, +3.0 mAP50 for BDD100K Clear $\rightarrow$ Rainy, and +6.3 mIoU for Cityscapes $\rightarrow$ ACDC. Our approach adds minimal memory during training and has no additional latency at inference time. Please see Appendix for more results and analysis.
Towards Real-Time Analysis of Broadcast Badminton Videos
Aug 23, 2023



Analysis of player movements is a crucial subset of sports analysis. Existing player movement analysis methods use recorded videos after the match is over. In this work, we propose an end-to-end framework for player movement analysis for badminton matches on live broadcast match videos. We only use the visual inputs from the match and, unlike other approaches which use multi-modal sensor data, our approach uses only visual cues. We propose a method to calculate the on-court distance covered by both the players from the video feed of a live broadcast badminton match. To perform this analysis, we focus on the gameplay by removing replays and other redundant parts of the broadcast match. We then perform player tracking to identify and track the movements of both players in each frame. Finally, we calculate the distance covered by each player and the average speed with which they move on the court. We further show a heatmap of the areas covered by the player on the court which is useful for analyzing the gameplay of the player. Our proposed framework was successfully used to analyze live broadcast matches in real-time during the Premier Badminton League 2019 (PBL 2019), with commentators and broadcasters appreciating the utility.
Enhancing Visual Domain Adaptation with Source Preparation
Jun 16, 2023Robotic Perception in diverse domains such as low-light scenarios, where new modalities like thermal imaging and specialized night-vision sensors are increasingly employed, remains a challenge. Largely, this is due to the limited availability of labeled data. Existing Domain Adaptation (DA) techniques, while promising to leverage labels from existing well-lit RGB images, fail to consider the characteristics of the source domain itself. We holistically account for this factor by proposing Source Preparation (SP), a method to mitigate source domain biases. Our Almost Unsupervised Domain Adaptation (AUDA) framework, a label-efficient semi-supervised approach for robotic scenarios -- employs Source Preparation (SP), Unsupervised Domain Adaptation (UDA) and Supervised Alignment (SA) from limited labeled data. We introduce CityIntensified, a novel dataset comprising temporally aligned image pairs captured from a high-sensitivity camera and an intensifier camera for semantic segmentation and object detection in low-light settings. We demonstrate the effectiveness of our method in semantic segmentation, with experiments showing that SP enhances UDA across a range of visual domains, with improvements up to 40.64% in mIoU over baseline, while making target models more robust to real-world shifts within the target domain. We show that AUDA is a label-efficient framework for effective DA, significantly improving target domain performance with only tens of labeled samples from the target domain.
Learned Two-Plane Perspective Prior based Image Resampling for Efficient Object Detection
Mar 25, 2023Real-time efficient perception is critical for autonomous navigation and city scale sensing. Orthogonal to architectural improvements, streaming perception approaches have exploited adaptive sampling improving real-time detection performance. In this work, we propose a learnable geometry-guided prior that incorporates rough geometry of the 3D scene (a ground plane and a plane above) to resample images for efficient object detection. This significantly improves small and far-away object detection performance while also being more efficient both in terms of latency and memory. For autonomous navigation, using the same detector and scale, our approach improves detection rate by +4.1 $AP_{S}$ or +39% and in real-time performance by +5.3 $sAP_{S}$ or +63% for small objects over state-of-the-art (SOTA). For fixed traffic cameras, our approach detects small objects at image scales other methods cannot. At the same scale, our approach improves detection of small objects by 195% (+12.5 $AP_{S}$) over naive-downsampling and 63% (+4.2 $AP_{S}$) over SOTA.
Streaming Video Analytics On The Edge With Asynchronous Cloud Support
Oct 04, 2022


Emerging Internet of Things (IoT) and mobile computing applications are expected to support latency-sensitive deep neural network (DNN) workloads. To realize this vision, the Internet is evolving towards an edge-computing architecture, where computing infrastructure is located closer to the end device to help achieve low latency. However, edge computing may have limited resources compared to cloud environments and thus, cannot run large DNN models that often have high accuracy. In this work, we develop REACT, a framework that leverages cloud resources to execute large DNN models with higher accuracy to improve the accuracy of models running on edge devices. To do so, we propose a novel edge-cloud fusion algorithm that fuses edge and cloud predictions, achieving low latency and high accuracy. We extensively evaluate our approach and show that our approach can significantly improve the accuracy compared to baseline approaches. We focus specifically on object detection in videos (applicable in many video analytics scenarios) and show that the fused edge-cloud predictions can outperform the accuracy of edge-only and cloud-only scenarios by as much as 50%. We also show that REACT can achieve good performance across tradeoff points by choosing a wide range of system parameters to satisfy use-case specific constraints, such as limited network bandwidth or GPU cycles.
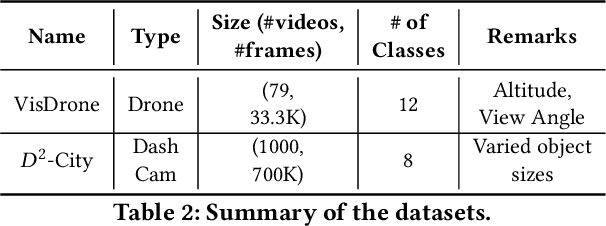
Adaptive Streaming Perception using Deep Reinforcement Learning
Jun 10, 2021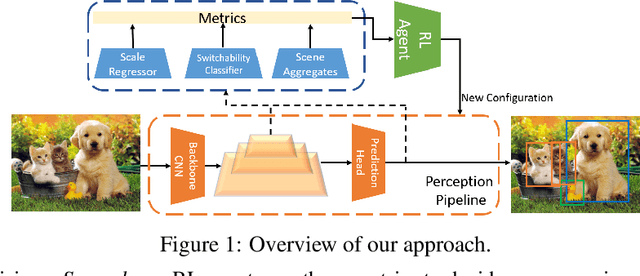
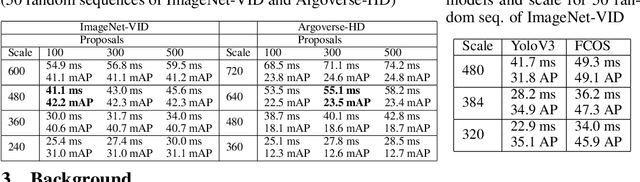
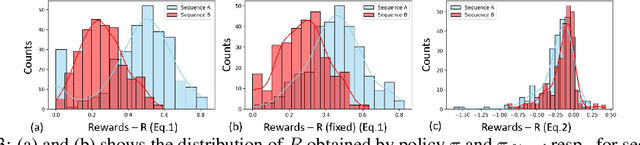
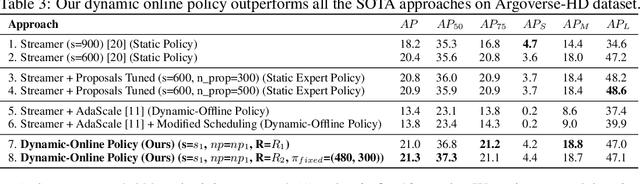
Executing computer vision models on streaming visual data, or streaming perception is an emerging problem, with applications in self-driving, embodied agents, and augmented/virtual reality. The development of such systems is largely governed by the accuracy and latency of the processing pipeline. While past work has proposed numerous approximate execution frameworks, their decision functions solely focus on optimizing latency, accuracy, or energy, etc. This results in sub-optimum decisions, affecting the overall system performance. We argue that the streaming perception systems should holistically maximize the overall system performance (i.e., considering both accuracy and latency simultaneously). To this end, we describe a new approach based on deep reinforcement learning to learn these tradeoffs at runtime for streaming perception. This tradeoff optimization is formulated as a novel deep contextual bandit problem and we design a new reward function that holistically integrates latency and accuracy into a single metric. We show that our agent can learn a competitive policy across multiple decision dimensions, which outperforms state-of-the-art policies on public datasets.
SmartTennisTV: Automatic indexing of tennis videos
Jan 04, 2018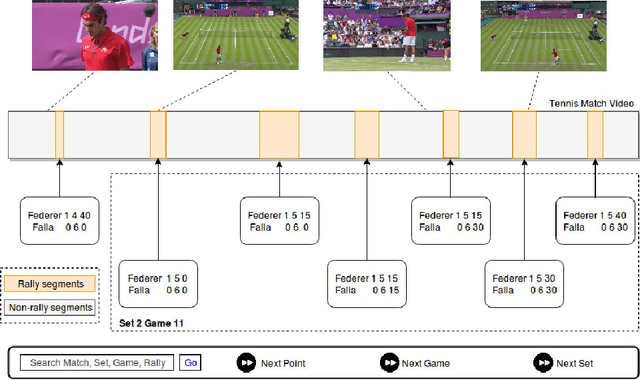
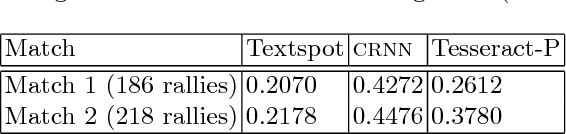
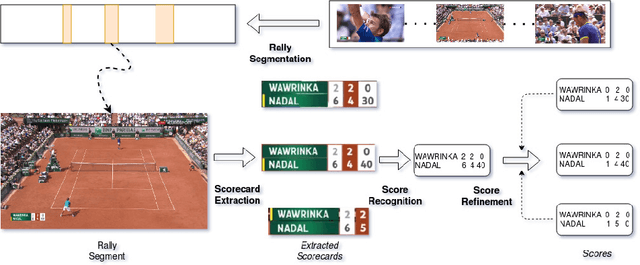
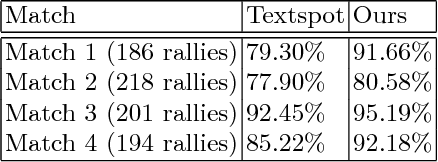
In this paper, we demonstrate a score based indexing approach for tennis videos. Given a broadcast tennis video (BTV), we index all the video segments with their scores to create a navigable and searchable match. Our approach temporally segments the rallies in the video and then recognizes the scores from each of the segments, before refining the scores using the knowledge of the tennis scoring system. We finally build an interface to effortlessly retrieve and view the relevant video segments by also automatically tagging the segmented rallies with human accessible tags such as 'fault' and 'deuce'. The efficiency of our approach is demonstrated on BTV's from two major tennis tournaments.