 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxonomy of Faults in Attention-Based Neural Networks
Aug 06, 2025Attention mechanisms are at the core of modern neural architectures, powering systems ranging from ChatGPT to autonomous vehicles and driving a major economic impact. However, high-profile failures, such as ChatGPT's nonsensical outputs or Google's suspension of Gemini's image generation due to attention weight errors, highlight a critical gap: existing deep learning fault taxonomies might not adequately capture the unique failures introduced by attention mechanisms. This gap leaves practitioners without actionable diagnostic guidance. To address this gap, we present the first comprehensive empirical study of faults in attention-based neural networks (ABNNs). Our work is based on a systematic analysis of 555 real-world faults collected from 96 projects across ten frameworks, including GitHub, Hugging Face, and Stack Overflow. Through our analysis, we develop a novel taxonomy comprising seven attention-specific fault categories, not captured by existing work. Our results show that over half of the ABNN faults arise from mechanisms unique to attention architectures. We further analyze the root causes and manifestations of these faults through various symptoms. Finally, by analyzing symptom-root cause associations, we identify four evidence-based diagnostic heuristics that explain 33.0% of attention-specific faults, offering the first systematic diagnostic guidance for attention-based models.
COMET: Generating Commit Messages using Delta Graph Context Representation
Feb 02, 2024



Commit messages explain code changes in a commit and facilitate collaboration among developers. Several commit message generation approaches have been proposed; however, they exhibit limited success in capturing the context of code changes. We propose Comet (Context-Aware Commit Message Generation), a novel approach that captures context of code changes using a graph-based representation and leverages a transformer-based model to generate high-quality commit messages. Our proposed method utilizes delta graph that we developed to effectively represent code differences. We also introduce a customizable quality assurance module to identify optimal messages, mitigating subjectivity in commit messages. Experiments show that Comet outperforms state-of-the-art techniques in terms of bleu-norm and meteor metrics while being comparable in terms of rogue-l. Additionally, we compare the proposed approach with the popular gpt-3.5-turbo model, along with gpt-4-turbo; the most capable GPT model, over zero-shot, one-shot, and multi-shot settings. We found Comet outperforming the GPT models, on five and four metrics respectively and provide competitive results with the two other metrics. The study has implications for researchers, tool developers, and software developers. Software developers may utilize Comet to generate context-aware commit messages. Researchers and tool developers can apply the proposed delta graph technique in similar contexts, like code review summarization.
CONCORD: Towards a DSL for Configurable Graph Code Representation
Jan 31, 2024Deep learning is widely used to uncover hidden patterns in large code corpora. To achieve this, constructing a format that captures the relevant characteristics and features of source code is essential. Graph-based representations have gained attention for their ability to model structural and semantic information. However, existing tools lack flexibility in constructing graphs across different programming languages, limiting their use. Additionally, the output of these tools often lacks interoperability and results in excessively large graphs, making graph-based neural networks training slower and less scalable. We introduce CONCORD, a domain-specific language to build customizable graph representations. It implements reduction heuristics to reduce graphs' size complexity. We demonstrate its effectiveness in code smell detection as an illustrative use case and show that: first, CONCORD can produce code representations automatically per the specified configuration, and second, our heuristics can achieve comparable performance with significantly reduced size. CONCORD will help researchers a) create and experiment with customizable graph-based code representations for different software engineering tasks involving DL, b) reduce the engineering work to generate graph representations, c) address the issue of scalability in GNN models, and d) enhance the reproducibility of experiments in research through a standardized approach to code representation and analysis.
Naturalness of Attention: Revisiting Attention in Code Language Models
Nov 22, 2023



Language models for code such as CodeBERT offer the capability to learn advanced source code representation, but their opacity poses barriers to understanding of captured properties. Recent attention analysis studies provide initial interpretability insights by focusing solely on attention weights rather than considering the wider context modeling of Transformers. This study aims to shed some light on the previously ignored factors of the attention mechanism beyond the attention weights. We conduct an initial empirical study analyzing both attention distributions and transformed representations in CodeBERT. Across two programming languages, Java and Python, we find that the scaled transformation norms of the input better capture syntactic structure compared to attention weights alone. Our analysis reveals characterization of how CodeBERT embeds syntactic code properties. The findings demonstrate the importance of incorporating factors beyond just attention weights for rigorously understanding neural code models. This lays the groundwork for developing more interpretable models and effective uses of attention mechanisms in program analysis.
FECoM: A Step towards Fine-Grained Energy Measurement for Deep Learning
Aug 23, 2023With the increasing usage, scale, and complexity of Deep Learning (DL) models, their rapidly growing energy consumption has become a critical concern. Promoting green development and energy awareness at different granularities is the need of the hour to limit carbon emissions of DL systems. However, the lack of standard and repeatable tools to accurately measure and optimize energy consumption at a fine granularity (e.g., at method level) hinders progress in this area. In this paper, we introduce FECoM (Fine-grained Energy Consumption Meter), a framework for fine-grained DL energy consumption measurement. Specifically, FECoM provides researchers and developers a mechanism to profile DL APIs. FECoM addresses the challenges of measuring energy consumption at fine-grained level by using static instrumentation and considering various factors, including computational load and temperature stability. We assess FECoM's capability to measure fine-grained energy consumption for one of the most popular open-source DL frameworks, namely TensorFlow. Using FECoM, we also investigate the impact of parameter size and execution time on energy consumption, enriching our understanding of TensorFlow APIs' energy profiles. Furthermore, we elaborate on the considerations, issues, and challenges that one needs to consider while designing and implementing a fine-grained energy consumption measurement tool. We hope this work will facilitate further advances in DL energy measurement and the development of energy-aware practices for DL systems.
Towards Real-Time Analysis of Broadcast Badminton Videos
Aug 23, 2023



Analysis of player movements is a crucial subset of sports analysis. Existing player movement analysis methods use recorded videos after the match is over. In this work, we propose an end-to-end framework for player movement analysis for badminton matches on live broadcast match videos. We only use the visual inputs from the match and, unlike other approaches which use multi-modal sensor data, our approach uses only visual cues. We propose a method to calculate the on-court distance covered by both the players from the video feed of a live broadcast badminton match. To perform this analysis, we focus on the gameplay by removing replays and other redundant parts of the broadcast match. We then perform player tracking to identify and track the movements of both players in each frame. Finally, we calculate the distance covered by each player and the average speed with which they move on the court. We further show a heatmap of the areas covered by the player on the court which is useful for analyzing the gameplay of the player. Our proposed framework was successfully used to analyze live broadcast matches in real-time during the Premier Badminton League 2019 (PBL 2019), with commentators and broadcasters appreciating the utility.
Quantifying Outlierness of Funds from their Categories using Supervised Similarity
Aug 14, 2023



Mutual fund categorization has become a standard tool for the investment management industry and is extensively used by allocators for portfolio construction and manager selection, as well as by fund managers for peer analysis and competitive positioning. As a result, a (unintended) miscategorization or lack of precision can significantly impact allocation decisions and investment fund managers. Here, we aim to quantify the effect of miscategorization of funds utilizing a machine learning based approach. We formulate the problem of miscategorization of funds as a distance-based outlier detection problem, where the outliers are the data-points that are far from the rest of the data-points in the given feature space. We implement and employ a Random Forest (RF) based method of distance metric learning, and compute the so-called class-wise outlier measures for each data-point to identify outliers in the data. We test our implementation on various publicly available data sets, and then apply it to mutual fund data. We show that there is a strong relationship between the outlier measures of the funds and their future returns and discuss the implications of our findings.
DACOS-A Manually Annotated Dataset of Code Smells
Mar 15, 2023Researchers apply machine-learning techniques for code smell detection to counter the subjectivity of many code smells. Such approaches need a large, manually annotated dataset for training and benchmarking. Existing literature offers a few datasets; however, they are small in size and, more importantly, do not focus on the subjective code snippets. In this paper, we present DACOS, a manually annotated dataset containing 10,267 annotations for 5,192 code snippets. The dataset targets three kinds of code smells at different granularity: multifaceted abstraction, complex method, and long parameter list. The dataset is created in two phases. The first phase helps us identify the code snippets that are potentially subjective by determining the thresholds of metrics used to detect a smell. The second phase collects annotations for potentially subjective snippets. We also offer an extended dataset DACOSX that includes definitely benign and definitely smelly snippets by using the thresholds identified in the first phase. We have developed TagMan, a web application to help annotators view and mark the snippets one-by-one and record the provided annotations. We make the datasets and the web application accessible publicly. This dataset will help researchers working on smell detection techniques to build relevant and context-aware machine-learning models.
A Survey on Machine Learning Techniques for Source Code Analysis
Oct 18, 2021
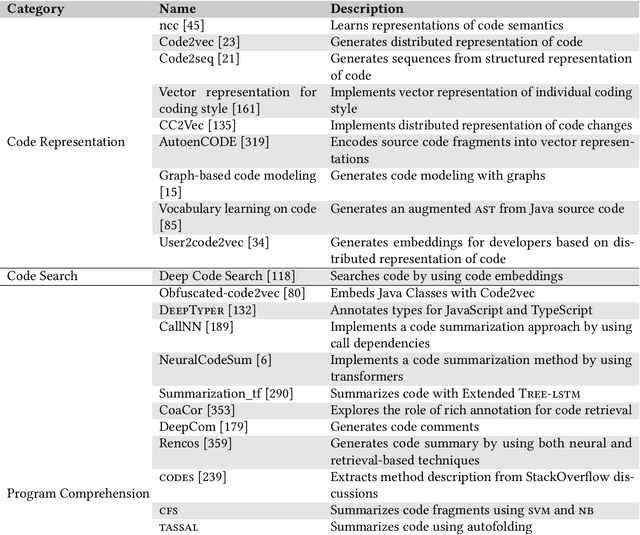

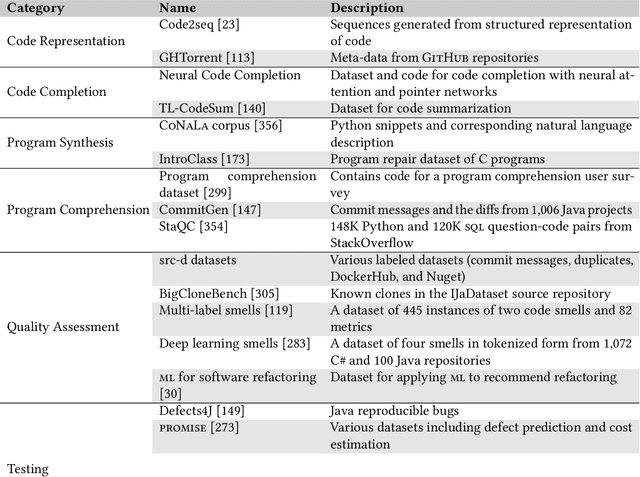
Context: The advancements in machine learning techniques have encouraged researchers to apply these techniques to a myriad of software engineering tasks that use source code analysis such as testing and vulnerabilities detection. A large number of studies poses challenges to the community to understand the current landscape. Objective: We aim to summarize the current knowledge in the area of applied machine learning for source code analysis. Method: We investigate studies belonging to twelve categories of software engineering tasks and corresponding machine learning techniques, tools, and datasets that have been applied to solve them. To do so, we carried out an extensive literature search and identified 364 primary studies published between 2002 and 2021. We summarize our observations and findings with the help of the identified studies. Results: Our findings suggest that the usage of machine learning techniques for source code analysis tasks is consistently increasing. We synthesize commonly used steps and the overall workflow for each task, and summarize the employed machine learning techniques. Additionally, we collate a comprehensive list of available datasets and tools useable in this context. Finally, we summarize the perceived challenges in this area that include availability of standard datasets, reproducibility and replicability, and hardware resources.