 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Unsupervised Anomaly Detection with Random Forest
Apr 22, 2025



We describe the use of an unsupervised Random Forest for similarity learning and improved unsupervised anomaly detection. By training a Random Forest to discriminate between real data and synthetic data sampled from a uniform distribution over the real data bounds, a distance measure is obtained that anisometrically transforms the data, expanding distances at the boundary of the data manifold. We show that using distances recovered from this transformation improves the accuracy of unsupervised anomaly detection, compared to other commonly used detectors, demonstrated over a large number of benchmark datasets. As well as improved performance, this method has advantages over other unsupervised anomaly detection methods, including minimal requirements for data preprocessing, native handling of missing data, and potential for visualizations. By relating outlier scores to partitions of the Random Forest, we develop a method for locally explainable anomaly predictions in terms of feature importance.
Can an unsupervised clustering algorithm reproduce a categorization system?
Aug 19, 2024
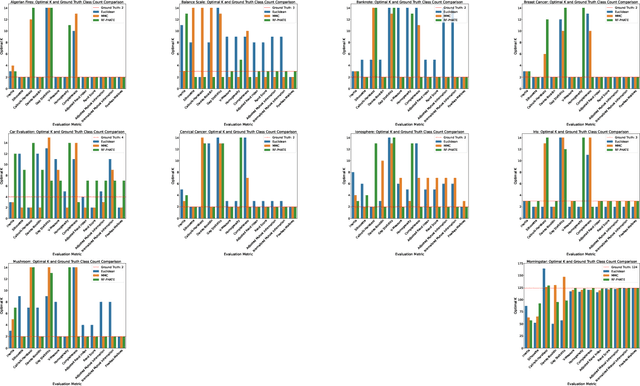


Peer analysis is a critical component of investment management, often relying on expert-provided categorization systems. These systems' consistency is questioned when they do not align with cohorts from unsupervised clustering algorithms optimized for various metrics. We investigate whether unsupervised clustering can reproduce ground truth classes in a labeled dataset, showing that success depends on feature selection and the chosen distance metric. Using toy datasets and fund categorization as real-world examples we demonstrate that accurately reproducing ground truth classes is challenging. We also highlight the limitations of standard clustering evaluation metrics in identifying the optimal number of clusters relative to the ground truth classes. We then show that if appropriate features are available in the dataset, and a proper distance metric is known (e.g., using a supervised Random Forest-based distance metric learning method), then an unsupervised clustering can indeed reproduce the ground truth classes as distinct clusters.
Case-based Explainability for Random Forest: Prototypes, Critics, Counter-factuals and Semi-factuals
Aug 13, 2024
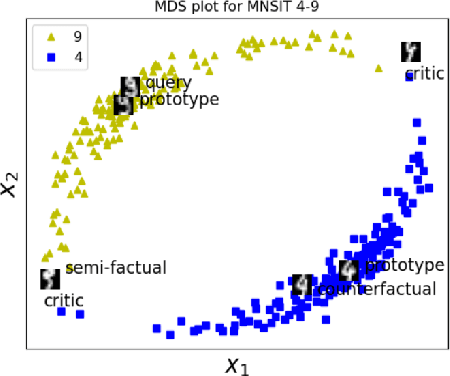
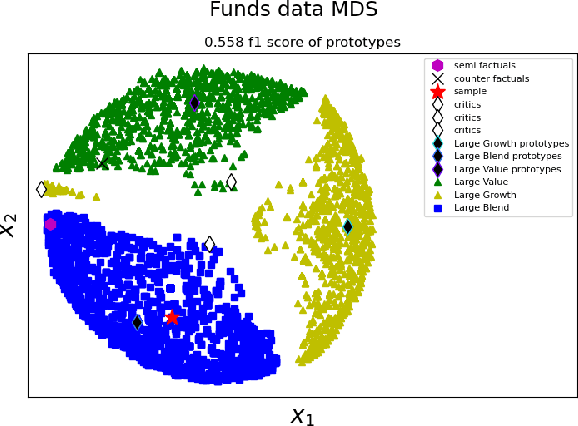
The explainability of black-box machine learning algorithms, commonly known as Explainable Artificial Intelligence (XAI), has become crucial for financial and other regulated industrial applications due to regulatory requirements and the need for transparency in business practices. Among the various paradigms of XAI, Explainable Case-Based Reasoning (XCBR) stands out as a pragmatic approach that elucidates the output of a model by referencing actual examples from the data used to train or test the model. Despite its potential, XCBR has been relatively underexplored for many algorithms such as tree-based models until recently. We start by observing that most XCBR methods are defined based on the distance metric learned by the algorithm. By utilizing a recently proposed technique to extract the distance metric learned by Random Forests (RFs), which is both geometry- and accuracy-preserving, we investigate various XCBR methods. These methods amount to identify special points from the training datasets, such as prototypes, critics, counter-factuals, and semi-factuals, to explain the predictions for a given query of the RF. We evaluate these special points using various evaluation metrics to assess their explanatory power and effectiveness.
Quantile Regression using Random Forest Proximities
Aug 05, 2024
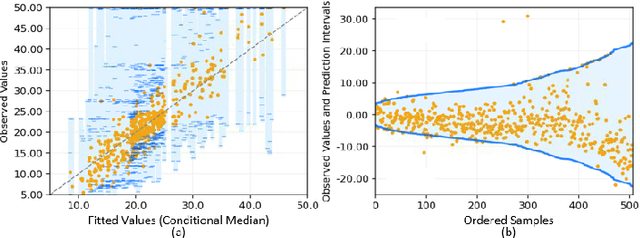
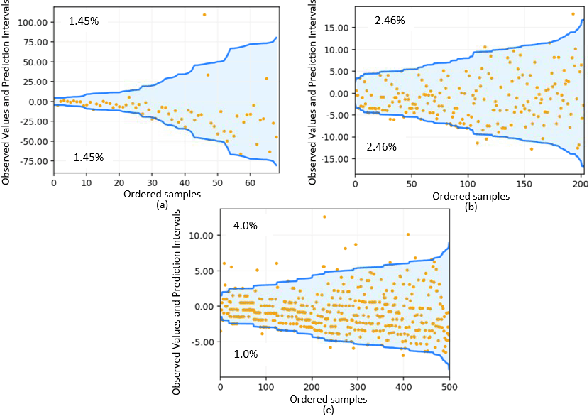

Due to the dynamic nature of financial markets, maintaining models that produce precise predictions over time is difficult. Often the goal isn't just point prediction but determining uncertainty. Quantifying uncertainty, especially the aleatoric uncertainty due to the unpredictable nature of market drivers, helps investors understand varying risk levels. Recently, quantile regression forests (QRF) have emerged as a promising solution: Unlike most basic quantile regression methods that need separate models for each quantile, quantile regression forests estimate the entire conditional distribution of the target variable with a single model, while retaining all the salient features of a typical random forest. We introduce a novel approach to compute quantile regressions from random forests that leverages the proximity (i.e., distance metric) learned by the model and infers the conditional distribution of the target variable. We evaluate the proposed methodology using publicly available datasets and then apply it towards the problem of forecasting the average daily volume of corporate bonds. We show that using quantile regression using Random Forest proximities demonstrates superior performance in approximating conditional target distributions and prediction intervals to the original version of QRF. We also demonstrate that the proposed framework is significantly more computationally efficient than traditional approaches to quantile regressions.
Open Set Recognition for Random Forest
Aug 01, 2024In many real-world classification or recognition tasks, it is often difficult to collect training examples that exhaust all possible classes due to, for example, incomplete knowledge during training or ever changing regimes. Therefore, samples from unknown/novel classes may be encountered in testing/deployment. In such scenarios, the classifiers should be able to i) perform classification on known classes, and at the same time, ii) identify samples from unknown classes. This is known as open-set recognition. Although random forest has been an extremely successful framework as a general-purpose classification (and regression) method, in practice, it usually operates under the closed-set assumption and is not able to identify samples from new classes when run out of the box. In this work, we propose a novel approach to enabling open-set recognition capability for random forest classifiers by incorporating distance metric learning and distance-based open-set recognition. The proposed method is validated on both synthetic and real-world datasets. The experimental results indicate that the proposed approach outperforms state-of-the-art distance-based open-set recognition methods.
Towards Enhanced Local Explainability of Random Forests: a Proximity-Based Approach
Oct 19, 2023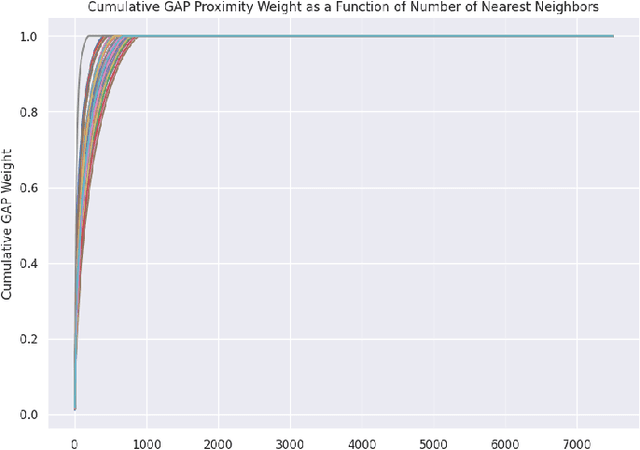
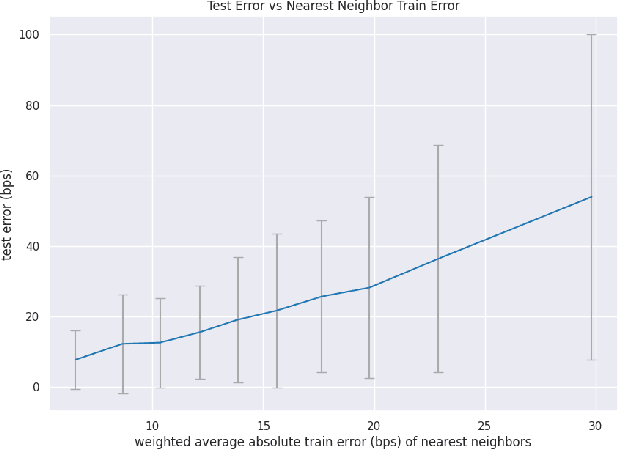
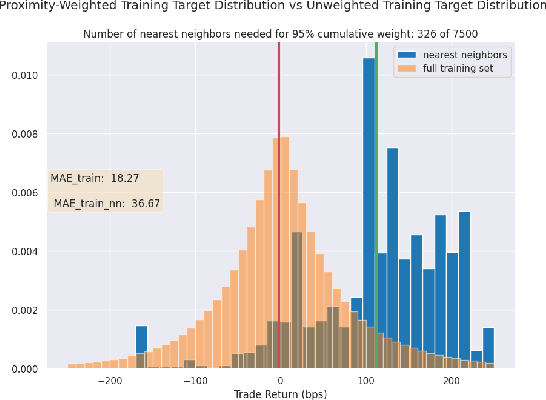
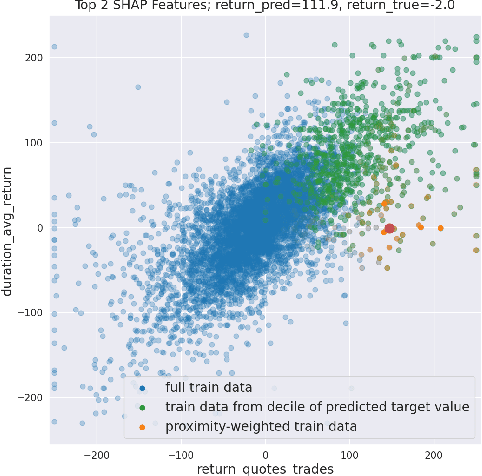
We initiate a novel approach to explain the out of sample performance of random forest (RF) models by exploiting the fact that any RF can be formulated as an adaptive weighted K nearest-neighbors model. Specifically, we use the proximity between points in the feature space learned by the RF to re-write random forest predictions exactly as a weighted average of the target labels of training data points. This linearity facilitates a local notion of explainability of RF predictions that generates attributions for any model prediction across observations in the training set, and thereby complements established methods like SHAP, which instead generates attributions for a model prediction across dimensions of the feature space. We demonstrate this approach in the context of a bond pricing model trained on US corporate bond trades, and compare our approach to various existing approaches to model explainability.
Quantifying Outlierness of Funds from their Categories using Supervised Similarity
Aug 14, 2023



Mutual fund categorization has become a standard tool for the investment management industry and is extensively used by allocators for portfolio construction and manager selection, as well as by fund managers for peer analysis and competitive positioning. As a result, a (unintended) miscategorization or lack of precision can significantly impact allocation decisions and investment fund managers. Here, we aim to quantify the effect of miscategorization of funds utilizing a machine learning based approach. We formulate the problem of miscategorization of funds as a distance-based outlier detection problem, where the outliers are the data-points that are far from the rest of the data-points in the given feature space. We implement and employ a Random Forest (RF) based method of distance metric learning, and compute the so-called class-wise outlier measures for each data-point to identify outliers in the data. We test our implementation on various publicly available data sets, and then apply it to mutual fund data. We show that there is a strong relationship between the outlier measures of the funds and their future returns and discuss the implications of our findings.
Learning Mutual Fund Categorization using Natural Language Processing
Jul 11, 2022

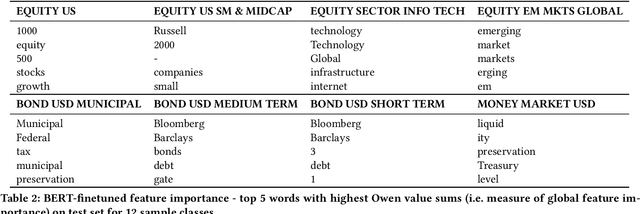

Categorization of mutual funds or Exchange-Traded-funds (ETFs) have long served the financial analysts to perform peer analysis for various purposes starting from competitor analysis, to quantifying portfolio diversification. The categorization methodology usually relies on fund composition data in the structured format extracted from the Form N-1A. Here, we initiate a study to learn the categorization system directly from the unstructured data as depicted in the forms using natural language processing (NLP). Positing as a multi-class classification problem with the input data being only the investment strategy description as reported in the form and the target variable being the Lipper Global categories, and using various NLP models, we show that the categorization system can indeed be learned with high accuracy. We discuss implications and applications of our findings as well as limitations of existing pre-trained architectures in applying them to learn fund categorization.
Fund2Vec: Mutual Funds Similarity using Graph Learning
Jun 24, 2021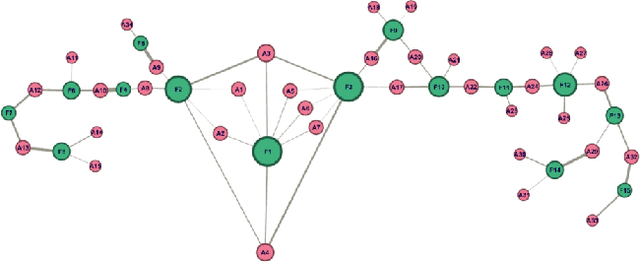
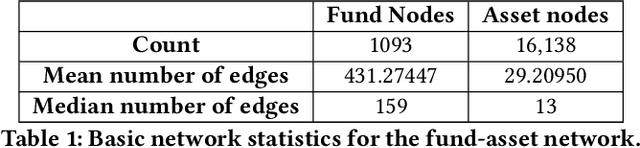
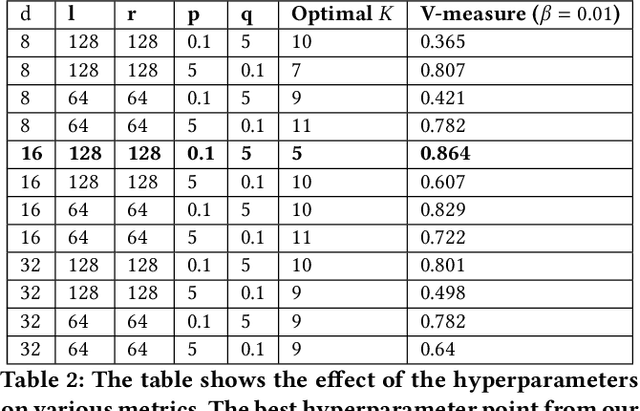
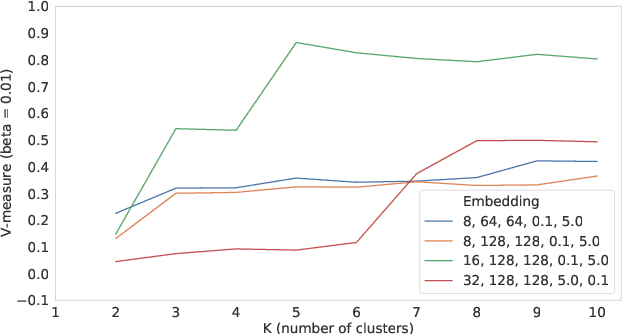
Identifying similar mutual funds with respect to the underlying portfolios has found many applications in financial services ranging from fund recommender systems, competitors analysis, portfolio analytics, marketing and sales, etc. The traditional methods are either qualitative, and hence prone to biases and often not reproducible, or, are known not to capture all the nuances (non-linearities) among the portfolios from the raw data. We propose a radically new approach to identify similar funds based on the weighted bipartite network representation of funds and their underlying assets data using a sophisticated machine learning method called Node2Vec which learns an embedded low-dimensional representation of the network. We call the embedding \emph{Fund2Vec}. Ours is the first ever study of the weighted bipartite network representation of the funds-assets network in its original form that identifies structural similarity among portfolios as opposed to merely portfolio overlaps.
Machine Learning Fund Categorizations
May 29, 2020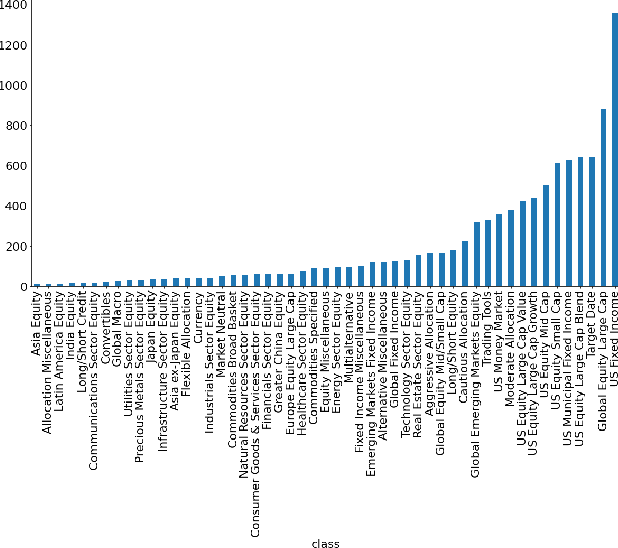
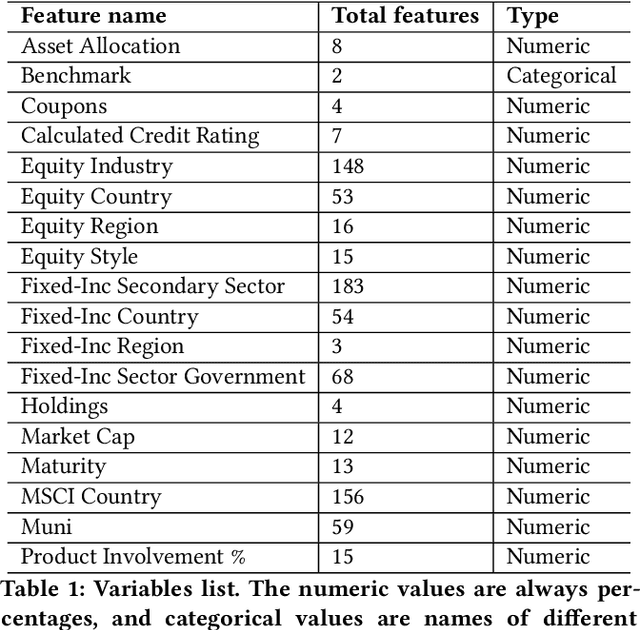
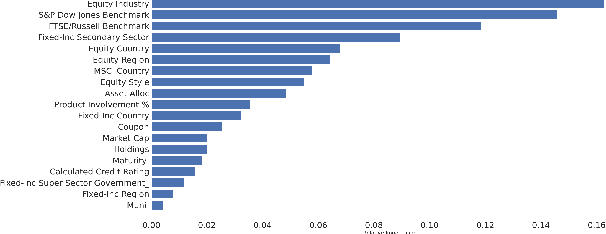
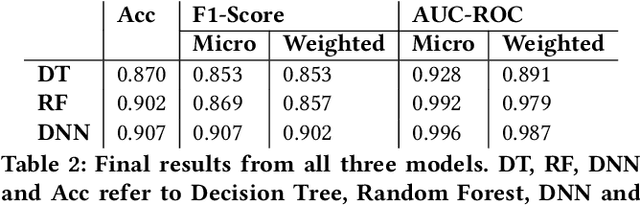
Given the surge in popularity of mutual funds (including exchange-traded funds (ETFs)) as a diversified financial investment, a vast variety of mutual funds from various investment management firms and diversification strategies have become available in the market. Identifying similar mutual funds among such a wide landscape of mutual funds has become more important than ever because of many applications ranging from sales and marketing to portfolio replication, portfolio diversification and tax loss harvesting. The current best method is data-vendor provided categorization which usually relies on curation by human experts with the help of available data. In this work, we establish that an industry wide well-regarded categorization system is learnable using machine learning and largely reproducible, and in turn constructing a truly data-driven categorization. We discuss the intellectual challenges in learning this man-made system, our results and their implications.