 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Enhanced Local Explainability of Random Forests: a Proximity-Based Approach
Oct 19, 2023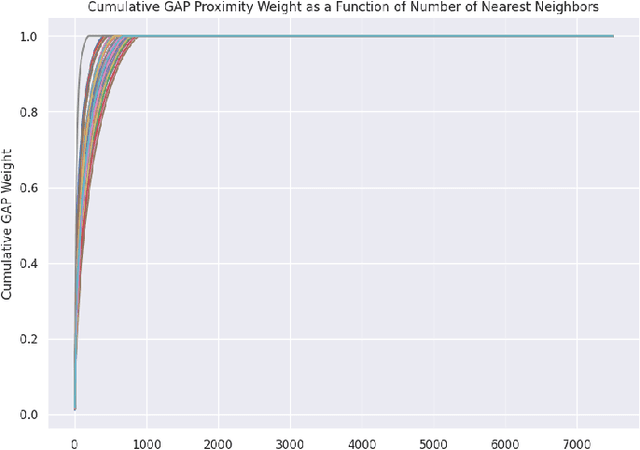
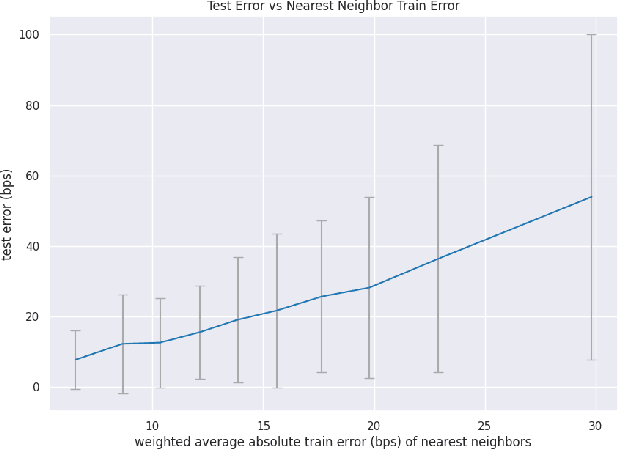
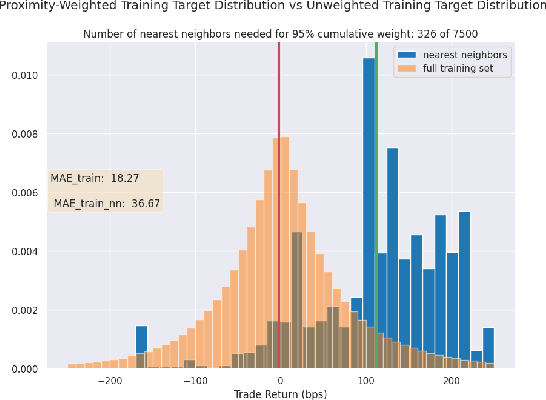
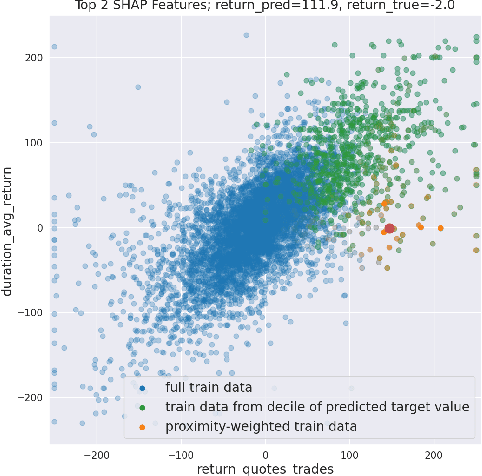
We initiate a novel approach to explain the out of sample performance of random forest (RF) models by exploiting the fact that any RF can be formulated as an adaptive weighted K nearest-neighbors model. Specifically, we use the proximity between points in the feature space learned by the RF to re-write random forest predictions exactly as a weighted average of the target labels of training data points. This linearity facilitates a local notion of explainability of RF predictions that generates attributions for any model prediction across observations in the training set, and thereby complements established methods like SHAP, which instead generates attributions for a model prediction across dimensions of the feature space. We demonstrate this approach in the context of a bond pricing model trained on US corporate bond trades, and compare our approach to various existing approaches to model explainability.
Learning Mutual Fund Categorization using Natural Language Processing
Jul 11, 2022

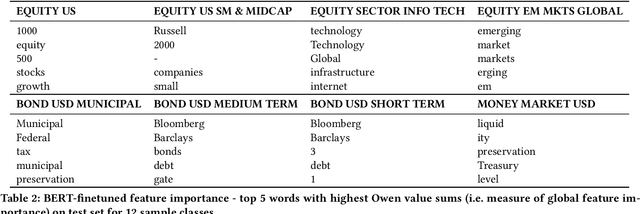

Categorization of mutual funds or Exchange-Traded-funds (ETFs) have long served the financial analysts to perform peer analysis for various purposes starting from competitor analysis, to quantifying portfolio diversification. The categorization methodology usually relies on fund composition data in the structured format extracted from the Form N-1A. Here, we initiate a study to learn the categorization system directly from the unstructured data as depicted in the forms using natural language processing (NLP). Positing as a multi-class classification problem with the input data being only the investment strategy description as reported in the form and the target variable being the Lipper Global categories, and using various NLP models, we show that the categorization system can indeed be learned with high accuracy. We discuss implications and applications of our findings as well as limitations of existing pre-trained architectures in applying them to learn fund categorization.