 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Enhanced Local Explainability of Random Forests: a Proximity-Based Approach
Paper and Code
Oct 19, 2023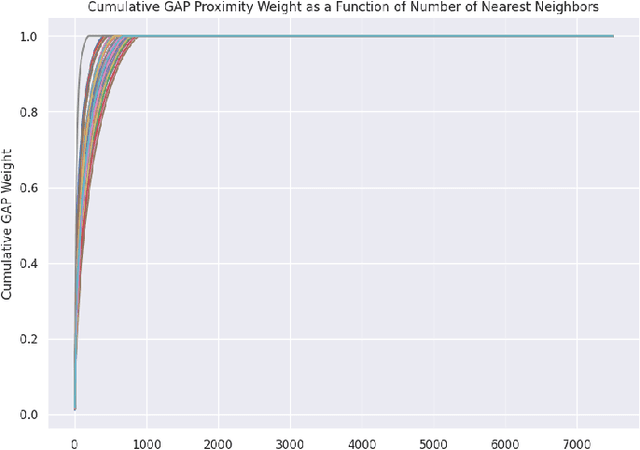
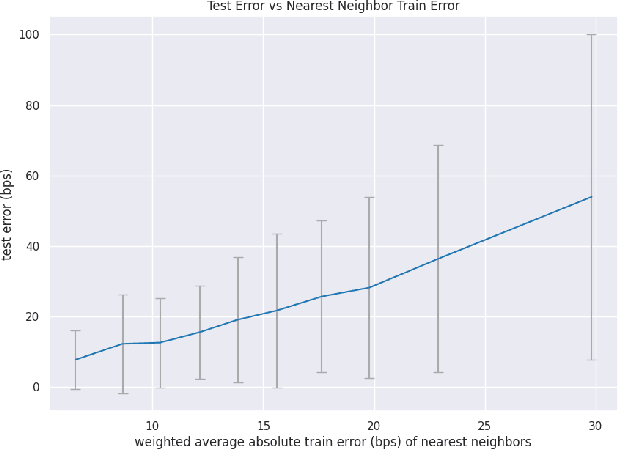
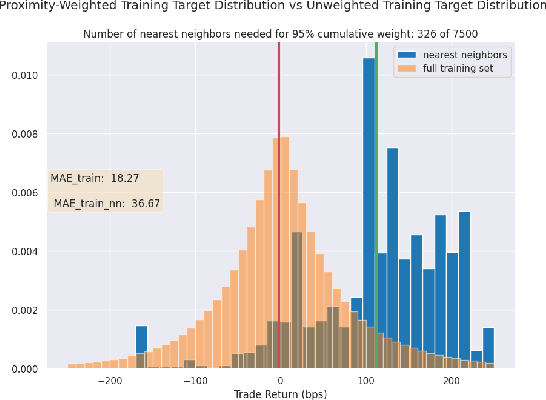
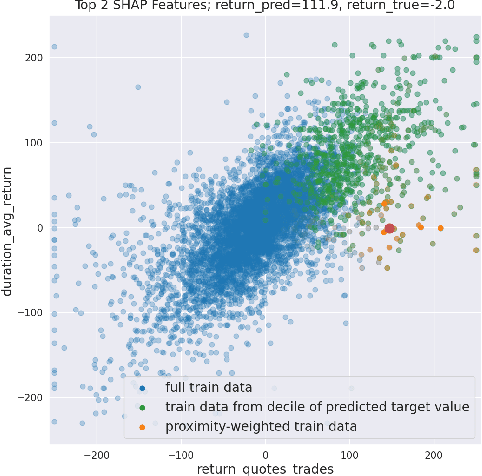
We initiate a novel approach to explain the out of sample performance of random forest (RF) models by exploiting the fact that any RF can be formulated as an adaptive weighted K nearest-neighbors model. Specifically, we use the proximity between points in the feature space learned by the RF to re-write random forest predictions exactly as a weighted average of the target labels of training data points. This linearity facilitates a local notion of explainability of RF predictions that generates attributions for any model prediction across observations in the training set, and thereby complements established methods like SHAP, which instead generates attributions for a model prediction across dimensions of the feature space. We demonstrate this approach in the context of a bond pricing model trained on US corporate bond trades, and compare our approach to various existing approaches to model explainability.