 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoria: A Scalable Agentic Memory Framework for Personalized Conversational AI
Dec 14, 2025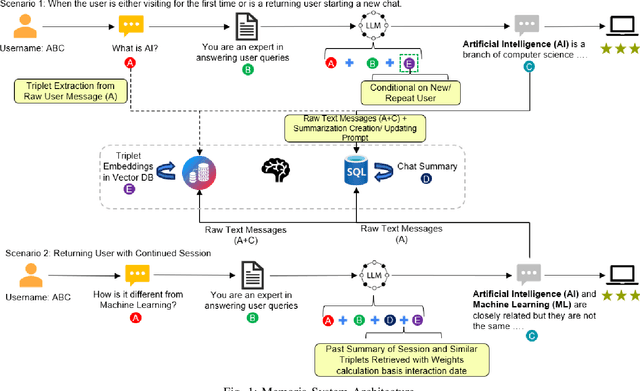

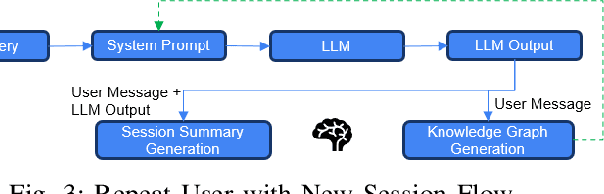
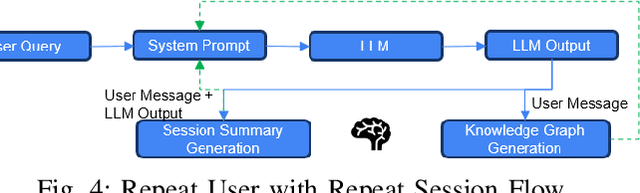
Agentic memory is emerging as a key enabler for large language models (LLM) to maintain continuity, personalization, and long-term context in extended user interactions, critical capabilities for deploying LLMs as truly interactive and adaptive agents. Agentic memory refers to the memory that provides an LLM with agent-like persistence: the ability to retain and act upon information across conversations, similar to how a human would. We present Memoria, a modular memory framework that augments LLM-based conversational systems with persistent, interpretable, and context-rich memory. Memoria integrates two complementary components: dynamic session-level summarization and a weighted knowledge graph (KG)-based user modelling engine that incrementally captures user traits, preferences, and behavioral patterns as structured entities and relationships. This hybrid architecture enables both short-term dialogue coherence and long-term personalization while operating within the token constraints of modern LLMs. We demonstrate how Memoria enables scalable, personalized conversational artificial intelligence (AI) by bridging the gap between stateless LLM interfaces and agentic memory systems, offering a practical solution for industry applications requiring adaptive and evolving user experiences.
Interpretable Model-Aware Counterfactual Explanations for Random Forest
Oct 31, 2025

Despite their enormous predictive power, machine learning models are often unsuitable for applications in regulated industries such as finance, due to their limited capacity to provide explanations. While model-agnostic frameworks such as Shapley values have proved to be convenient and popular, they rarely align with the kinds of causal explanations that are typically sought after. Counterfactual case-based explanations, where an individual is informed of which circumstances would need to be different to cause a change in outcome, may be more intuitive and actionable. However, finding appropriate counterfactual cases is an open challenge, as is interpreting which features are most critical for the change in outcome. Here, we pose the question of counterfactual search and interpretation in terms of similarity learning, exploiting the representation learned by the random forest predictive model itself. Once a counterfactual is found, the feature importance of the explanation is computed as a function of which random forest partitions are crossed in order to reach it from the original instance. We demonstrate this method on both the MNIST hand-drawn digit dataset and the German credit dataset, finding that it generates explanations that are sparser and more useful than Shapley values.
Reasoning or Overthinking: Evaluating Large Language Models on Financial Sentiment Analysis
Jun 05, 2025We investigate the effectiveness of large language models (LLMs), including reasoning-based and non-reasoning models, in performing zero-shot financial sentiment analysis. Using the Financial PhraseBank dataset annotated by domain experts, we evaluate how various LLMs and prompting strategies align with human-labeled sentiment in a financial context. We compare three proprietary LLMs (GPT-4o, GPT-4.1, o3-mini) under different prompting paradigms that simulate System 1 (fast and intuitive) or System 2 (slow and deliberate) thinking and benchmark them against two smaller models (FinBERT-Prosus, FinBERT-Tone) fine-tuned on financial sentiment analysis. Our findings suggest that reasoning, either through prompting or inherent model design, does not improve performance on this task. Surprisingly, the most accurate and human-aligned combination of model and method was GPT-4o without any Chain-of-Thought (CoT) prompting. We further explore how performance is impacted by linguistic complexity and annotation agreement levels, uncovering that reasoning may introduce overthinking, leading to suboptimal predictions. This suggests that for financial sentiment classification, fast, intuitive "System 1"-like thinking aligns more closely with human judgment compared to "System 2"-style slower, deliberative reasoning simulated by reasoning models or CoT prompting. Our results challenge the default assumption that more reasoning always leads to better LLM decisions, particularly in high-stakes financial applications.
Explainable Unsupervised Anomaly Detection with Random Forest
Apr 22, 2025



We describe the use of an unsupervised Random Forest for similarity learning and improved unsupervised anomaly detection. By training a Random Forest to discriminate between real data and synthetic data sampled from a uniform distribution over the real data bounds, a distance measure is obtained that anisometrically transforms the data, expanding distances at the boundary of the data manifold. We show that using distances recovered from this transformation improves the accuracy of unsupervised anomaly detection, compared to other commonly used detectors, demonstrated over a large number of benchmark datasets. As well as improved performance, this method has advantages over other unsupervised anomaly detection methods, including minimal requirements for data preprocessing, native handling of missing data, and potential for visualizations. By relating outlier scores to partitions of the Random Forest, we develop a method for locally explainable anomaly predictions in terms of feature importance.
Supervised Similarity for High-Yield Corporate Bonds with Quantum Cognition Machine Learning
Feb 03, 2025
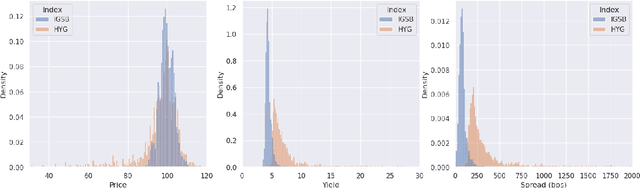
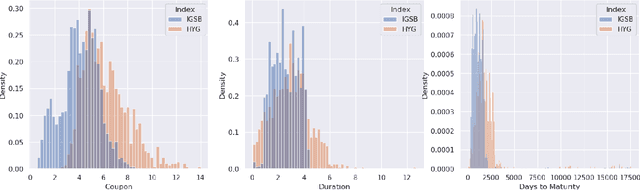
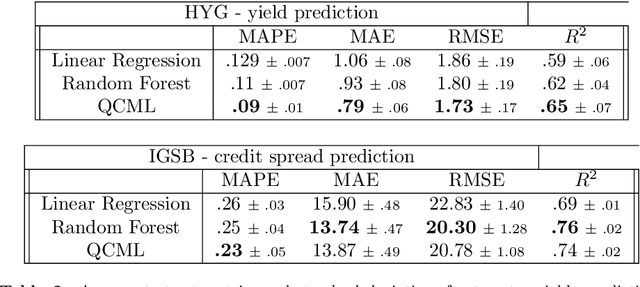
We investigate the application of quantum cognition machine learning (QCML), a novel paradigm for both supervised and unsupervised learning tasks rooted in the mathematical formalism of quantum theory, to distance metric learning in corporate bond markets. Compared to equities, corporate bonds are relatively illiquid and both trade and quote data in these securities are relatively sparse. Thus, a measure of distance/similarity among corporate bonds is particularly useful for a variety of practical applications in the trading of illiquid bonds, including the identification of similar tradable alternatives, pricing securities with relatively few recent quotes or trades, and explaining the predictions and performance of ML models based on their training data. Previous research has explored supervised similarity learning based on classical tree-based models in this context; here, we explore the application of the QCML paradigm for supervised distance metric learning in the same context, showing that it outperforms classical tree-based models in high-yield (HY) markets, while giving comparable or better performance (depending on the evaluation metric) in investment grade (IG) markets.
A Comparative Study of DSPy Teleprompter Algorithms for Aligning Large Language Models Evaluation Metrics to Human Evaluation
Dec 19, 2024



We argue that the Declarative Self-improving Python (DSPy) optimizers are a way to align the large language model (LLM) prompts and their evaluations to the human annotations. We present a comparative analysis of five teleprompter algorithms, namely, Cooperative Prompt Optimization (COPRO), Multi-Stage Instruction Prompt Optimization (MIPRO), BootstrapFewShot, BootstrapFewShot with Optuna, and K-Nearest Neighbor Few Shot, within the DSPy framework with respect to their ability to align with human evaluations. As a concrete example, we focus on optimizing the prompt to align hallucination detection (using LLM as a judge) to human annotated ground truth labels for a publicly available benchmark dataset. Our experiments demonstrate that optimized prompts can outperform various benchmark methods to detect hallucination, and certain telemprompters outperform the others in at least these experiments.
How to Choose a Threshold for an Evaluation Metric for Large Language Models
Dec 10, 2024



To ensure and monitor large language models (LLMs) reliably, various evaluation metrics have been proposed in the literature. However, there is little research on prescribing a methodology to identify a robust threshold on these metrics even though there are many serious implications of an incorrect choice of the thresholds during deployment of the LLMs. Translating the traditional model risk management (MRM) guidelines within regulated industries such as the financial industry, we propose a step-by-step recipe for picking a threshold for a given LLM evaluation metric. We emphasize that such a methodology should start with identifying the risks of the LLM application under consideration and risk tolerance of the stakeholders. We then propose concrete and statistically rigorous procedures to determine a threshold for the given LLM evaluation metric using available ground-truth data. As a concrete example to demonstrate the proposed methodology at work, we employ it on the Faithfulness metric, as implemented in various publicly available libraries, using the publicly available HaluBench dataset. We also lay a foundation for creating systematic approaches to select thresholds, not only for LLMs but for any GenAI applications.
Can an unsupervised clustering algorithm reproduce a categorization system?
Aug 19, 2024
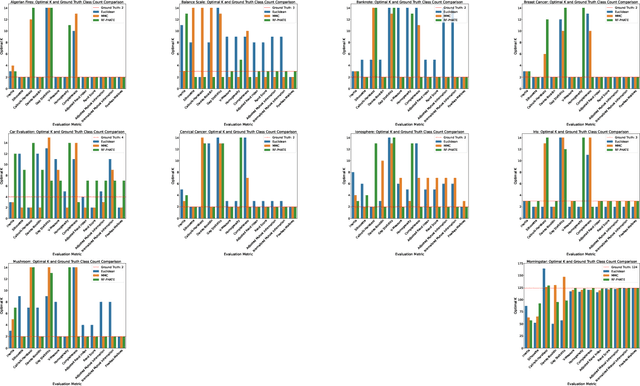


Peer analysis is a critical component of investment management, often relying on expert-provided categorization systems. These systems' consistency is questioned when they do not align with cohorts from unsupervised clustering algorithms optimized for various metrics. We investigate whether unsupervised clustering can reproduce ground truth classes in a labeled dataset, showing that success depends on feature selection and the chosen distance metric. Using toy datasets and fund categorization as real-world examples we demonstrate that accurately reproducing ground truth classes is challenging. We also highlight the limitations of standard clustering evaluation metrics in identifying the optimal number of clusters relative to the ground truth classes. We then show that if appropriate features are available in the dataset, and a proper distance metric is known (e.g., using a supervised Random Forest-based distance metric learning method), then an unsupervised clustering can indeed reproduce the ground truth classes as distinct clusters.
Case-based Explainability for Random Forest: Prototypes, Critics, Counter-factuals and Semi-factuals
Aug 13, 2024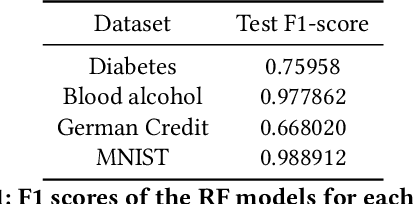
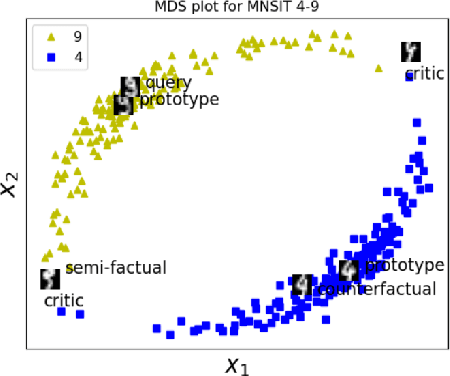
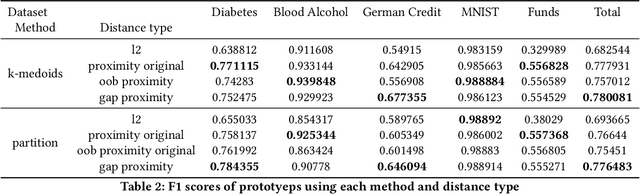
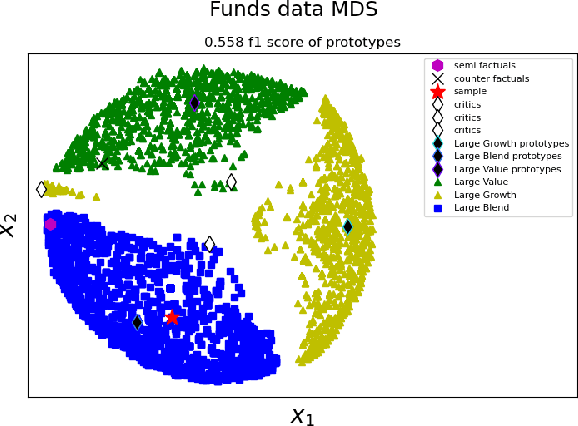
The explainability of black-box machine learning algorithms, commonly known as Explainable Artificial Intelligence (XAI), has become crucial for financial and other regulated industrial applications due to regulatory requirements and the need for transparency in business practices. Among the various paradigms of XAI, Explainable Case-Based Reasoning (XCBR) stands out as a pragmatic approach that elucidates the output of a model by referencing actual examples from the data used to train or test the model. Despite its potential, XCBR has been relatively underexplored for many algorithms such as tree-based models until recently. We start by observing that most XCBR methods are defined based on the distance metric learned by the algorithm. By utilizing a recently proposed technique to extract the distance metric learned by Random Forests (RFs), which is both geometry- and accuracy-preserving, we investigate various XCBR methods. These methods amount to identify special points from the training datasets, such as prototypes, critics, counter-factuals, and semi-factuals, to explain the predictions for a given query of the RF. We evaluate these special points using various evaluation metrics to assess their explanatory power and effectiveness.
HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction
Aug 09, 2024



Extraction and interpretation of intricate information from unstructured text data arising in financial applications, such as earnings call transcripts, present substantial challenges to large language models (LLMs) even using the current best practices to use Retrieval Augmented Generation (RAG) (referred to as VectorRAG techniques which utilize vector databases for information retrieval) due to challenges such as domain specific terminology and complex formats of the documents. We introduce a novel approach based on a combination, called HybridRAG, of the Knowledge Graphs (KGs) based RAG techniques (called GraphRAG) and VectorRAG techniques to enhance question-answer (Q&A) systems for information extraction from financial documents that is shown to be capable of generating accurate and contextually relevant answers. Using experiments on a set of financial earning call transcripts documents which come in the form of Q&A format, and hence provide a natural set of pairs of ground-truth Q&As, we show that HybridRAG which retrieves context from both vector database and KG outperforms both traditional VectorRAG and GraphRAG individually when evaluated at both the retrieval and generation stages in terms of retrieval accuracy and answer generation. The proposed technique has applications beyond the financial domain