 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimaxity and Admissibility of Bayesian Neural Networks
Apr 06, 2026Bayesian neural networks (BNNs) offer a natural probabilistic formulation for inference in deep learning models. Despite their popularity, their optimality has received limited attention through the lens of statistical decision theory. In this paper, we study decision rules induced by deep, fully connected feedforward ReLU BNNs in the normal location model under quadratic loss. We show that, for fixed prior scales, the induced Bayes decision rule is not minimax. We then propose a hyperprior on the effective output variance of the BNN prior that yields a superharmonic square-root marginal density, establishing that the resulting decision rule is simultaneously admissible and minimax. We further extend these results from the quadratic loss setting to the predictive density estimation problem with Kullback--Leibler loss. Finally, we validate our theoretical findings numerically through simulation.
Democratic Preference Alignment via Sortition-Weighted RLHF
Feb 04, 2026Whose values should AI systems learn? Preference based alignment methods like RLHF derive their training signal from human raters, yet these rater pools are typically convenience samples that systematically over represent some demographics and under represent others. We introduce Democratic Preference Optimization, or DemPO, a framework that applies algorithmic sortition, the same mechanism used to construct citizen assemblies, to preference based fine tuning. DemPO offers two training schemes. Hard Panel trains exclusively on preferences from a quota satisfying mini public sampled via sortition. Soft Panel retains all data but reweights each rater by their inclusion probability under the sortition lottery. We prove that Soft Panel weighting recovers the expected Hard Panel objective in closed form. Using a public preference dataset that pairs human judgments with rater demographics and a seventy five clause constitution independently elicited from a representative United States panel, we evaluate Llama models from one billion to eight billion parameters fine tuned under each scheme. Across six aggregation methods, the Hard Panel consistently ranks first and the Soft Panel consistently outperforms the unweighted baseline, with effect sizes growing as model capacity increases. These results demonstrate that enforcing demographic representativeness at the preference collection stage, rather than post hoc correction, yields models whose behavior better reflects values elicited from representative publics.
On the Provable Suboptimality of Momentum SGD in Nonstationary Stochastic Optimization
Jan 21, 2026While momentum-based acceleration has been studied extensively in deterministic optimization problems, its behavior in nonstationary environments -- where the data distribution and optimal parameters drift over time -- remains underexplored. We analyze the tracking performance of Stochastic Gradient Descent (SGD) and its momentum variants (Polyak heavy-ball and Nesterov) under uniform strong convexity and smoothness in varying stepsize regimes. We derive finite-time bounds in expectation and with high probability for the tracking error, establishing a sharp decomposition into three components: a transient initialization term, a noise-induced variance term, and a drift-induced tracking lag. Crucially, our analysis uncovers a fundamental trade-off: while momentum can suppress gradient noise, it incurs an explicit penalty on the tracking capability. We show that momentum can substantially amplify drift-induced tracking error, with amplification that becomes unbounded as the momentum parameter approaches one, formalizing the intuition that using 'stale' gradients hinders adaptation to rapid regime shifts. Complementing these upper bounds, we establish minimax lower bounds for dynamic regret under gradient-variation constraints. These lower bounds prove that the inertia-induced penalty is not an artifact of analysis but an information-theoretic barrier: in drift-dominated regimes, momentum creates an unavoidable 'inertia window' that fundamentally degrades performance. Collectively, these results provide a definitive theoretical grounding for the empirical instability of momentum in dynamic environments and delineate the precise regime boundaries where SGD provably outperforms its accelerated counterparts.
Boltzmann convolutions and Welford mean-variance layers with an application to time series forecasting and classification
Mar 06, 2025In this paper we propose a novel problem called the ForeClassing problem where the loss of a classification decision is only observed at a future time point after the classification decision has to be made. To solve this problem, we propose an approximately Bayesian deep neural network architecture called ForeClassNet for time series forecasting and classification. This network architecture forces the network to consider possible future realizations of the time series, by forecasting future time points and their likelihood of occurring, before making its final classification decision. To facilitate this, we introduce two novel neural network layers, Welford mean-variance layers and Boltzmann convolutional layers. Welford mean-variance layers allow networks to iteratively update their estimates of the mean and variance for the forecasted time points for each inputted time series to the network through successive forward passes, which the model can then consider in combination with a learned representation of the observed realizations of the time series for its classification decision. Boltzmann convolutional layers are linear combinations of approximately Bayesian convolutional layers with different filter lengths, allowing the model to learn multitemporal resolution representations of the input time series, and which resolutions to focus on within a given Boltzmann convolutional layer through a Boltzmann distribution. Through several simulation scenarios and two real world applications we demonstrate ForeClassNet achieves superior performance compared with current state of the art methods including a near 30% improvement in test set accuracy in our financial example compared to the second best performing model.
Supervised Similarity for High-Yield Corporate Bonds with Quantum Cognition Machine Learning
Feb 03, 2025
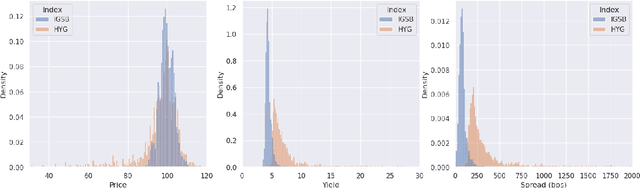
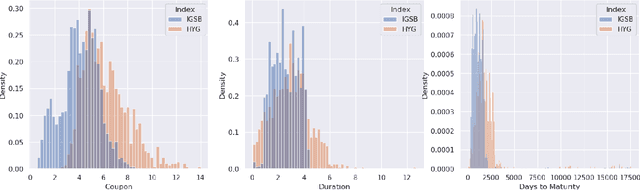
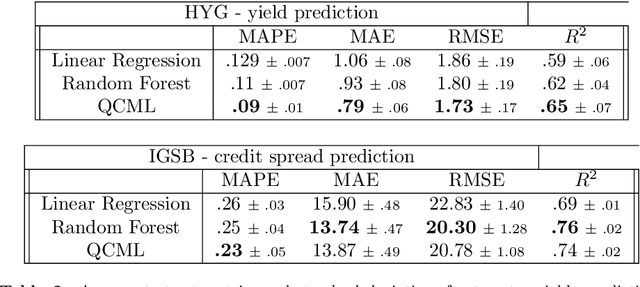
We investigate the application of quantum cognition machine learning (QCML), a novel paradigm for both supervised and unsupervised learning tasks rooted in the mathematical formalism of quantum theory, to distance metric learning in corporate bond markets. Compared to equities, corporate bonds are relatively illiquid and both trade and quote data in these securities are relatively sparse. Thus, a measure of distance/similarity among corporate bonds is particularly useful for a variety of practical applications in the trading of illiquid bonds, including the identification of similar tradable alternatives, pricing securities with relatively few recent quotes or trades, and explaining the predictions and performance of ML models based on their training data. Previous research has explored supervised similarity learning based on classical tree-based models in this context; here, we explore the application of the QCML paradigm for supervised distance metric learning in the same context, showing that it outperforms classical tree-based models in high-yield (HY) markets, while giving comparable or better performance (depending on the evaluation metric) in investment grade (IG) markets.
How Aligned are Generative Models to Humans in High-Stakes Decision-Making?
Oct 20, 2024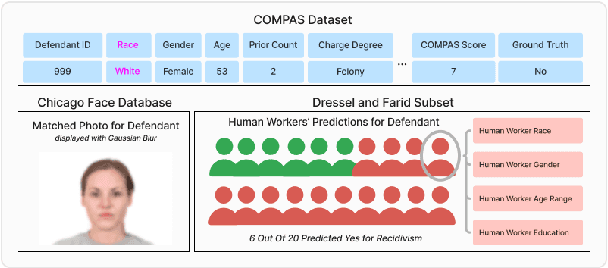


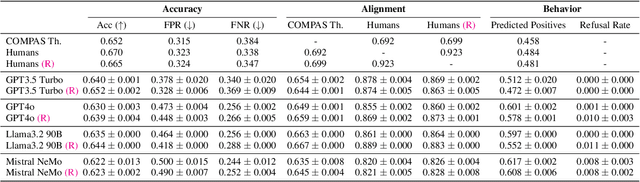
Large generative models (LMs) are increasingly being considered for high-stakes decision-making. This work considers how such models compare to humans and predictive AI models on a specific case of recidivism prediction. We combine three datasets -- COMPAS predictive AI risk scores, human recidivism judgements, and photos -- into a dataset on which we study the properties of several state-of-the-art, multimodal LMs. Beyond accuracy and bias, we focus on studying human-LM alignment on the task of recidivism prediction. We investigate if these models can be steered towards human decisions, the impact of adding photos, and whether anti-discimination prompting is effective. We find that LMs can be steered to outperform humans and COMPAS using in context-learning. We find anti-discrimination prompting to have unintended effects, causing some models to inhibit themselves and significantly reduce their number of positive predictions.
Bellwether Trades: Characteristics of Trades influential in Predicting Future Price Movements in Markets
Sep 08, 2024



In this study, we leverage powerful non-linear machine learning methods to identify the characteristics of trades that contain valuable information. First, we demonstrate the effectiveness of our optimized neural network predictor in accurately predicting future market movements. Then, we utilize the information from this successful neural network predictor to pinpoint the individual trades within each data point (trading window) that had the most impact on the optimized neural network's prediction of future price movements. This approach helps us uncover important insights about the heterogeneity in information content provided by trades of different sizes, venues, trading contexts, and over time.
K-ARMA Models for Clustering Time Series Data
Jun 30, 2022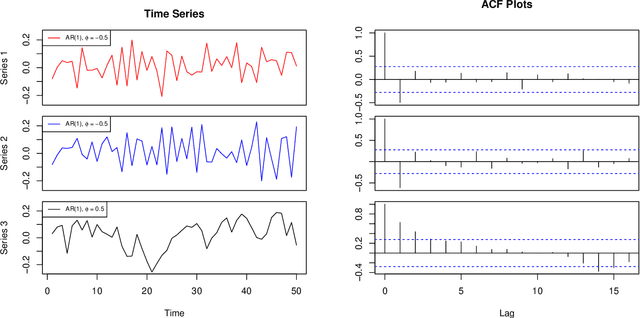
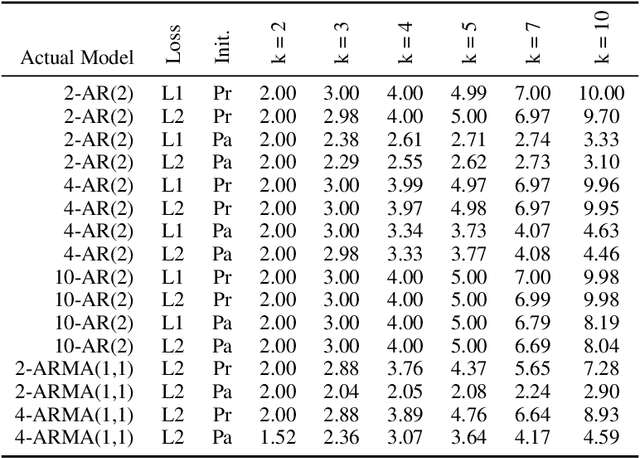
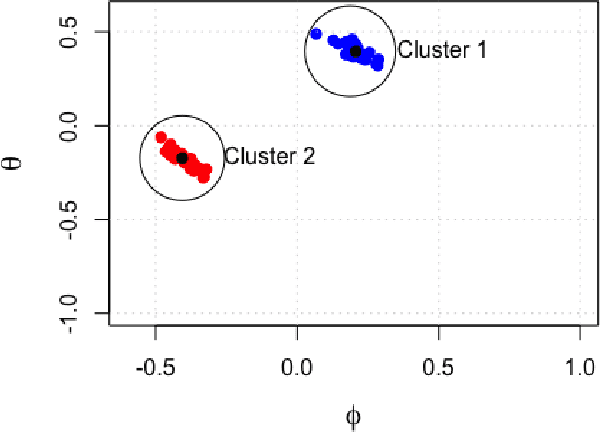

We present an approach to clustering time series data using a model-based generalization of the K-Means algorithm which we call K-Models. We prove the convergence of this general algorithm and relate it to the hard-EM algorithm for mixture modeling. We then apply our method first with an AR($p$) clustering example and show how the clustering algorithm can be made robust to outliers using a least-absolute deviations criteria. We then build our clustering algorithm up for ARMA($p,q$) models and extend this to ARIMA($p,d,q$) models. We develop a goodness of fit statistic for the models fitted to clusters based on the Ljung-Box statistic. We perform experiments with simulated data to show how the algorithm can be used for outlier detection, detecting distributional drift, and discuss the impact of initialization method on empty clusters. We also perform experiments on real data which show that our method is competitive with other existing methods for similar time series clustering tasks.
Interpretable Latent Variables in Deep State Space Models
Mar 03, 2022
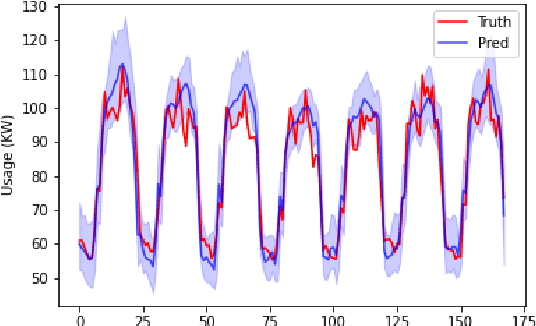

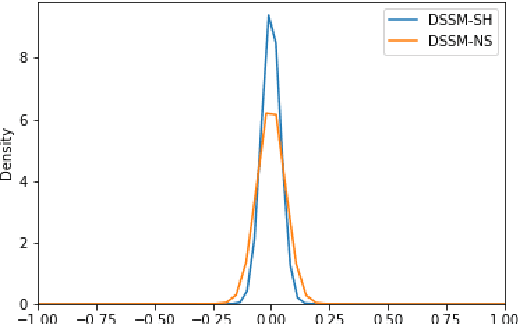
We introduce a new version of deep state-space models (DSSMs) that combines a recurrent neural network with a state-space framework to forecast time series data. The model estimates the observed series as functions of latent variables that evolve non-linearly through time. Due to the complexity and non-linearity inherent in DSSMs, previous works on DSSMs typically produced latent variables that are very difficult to interpret. Our paper focus on producing interpretable latent parameters with two key modifications. First, we simplify the predictive decoder by restricting the response variables to be a linear transformation of the latent variables plus some noise. Second, we utilize shrinkage priors on the latent variables to reduce redundancy and improve robustness. These changes make the latent variables much easier to understand and allow us to interpret the resulting latent variables as random effects in a linear mixed model. We show through two public benchmark datasets the resulting model improves forecasting performances.
Clustering Structure of Microstructure Measures
Jul 05, 2021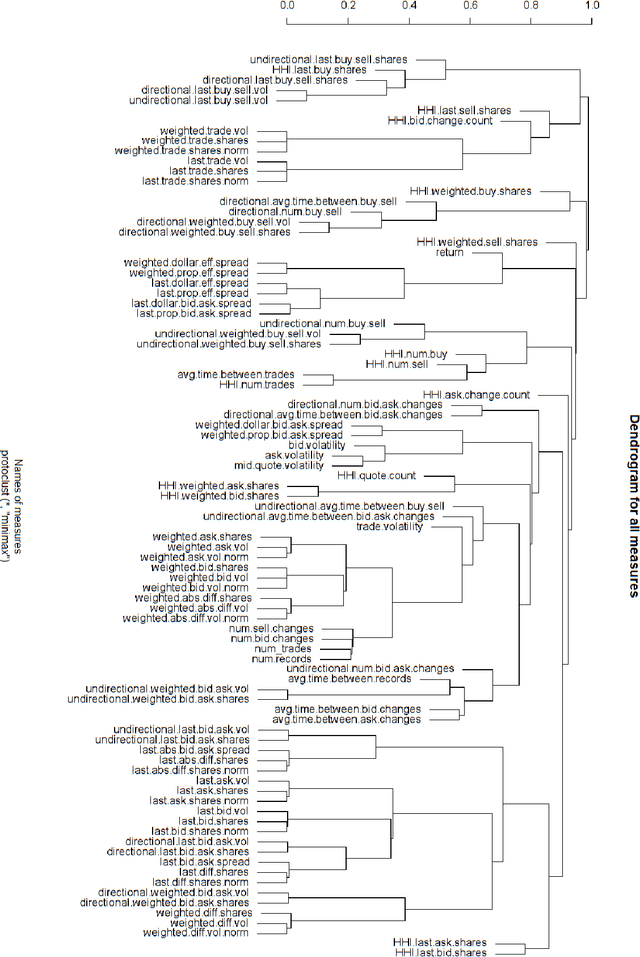
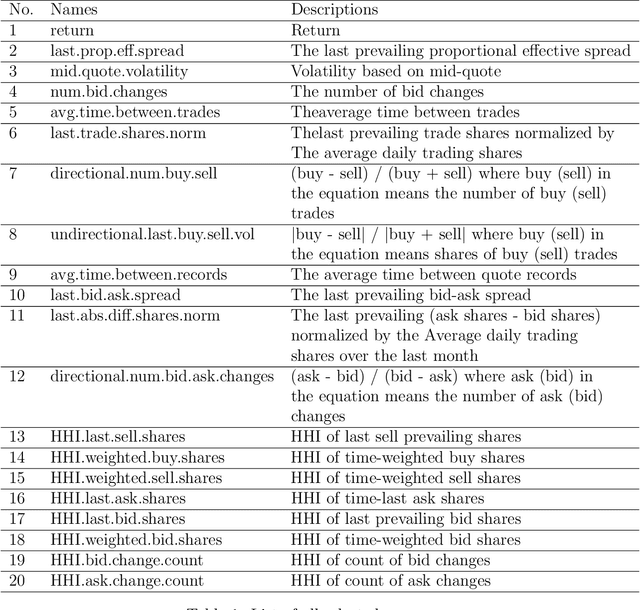
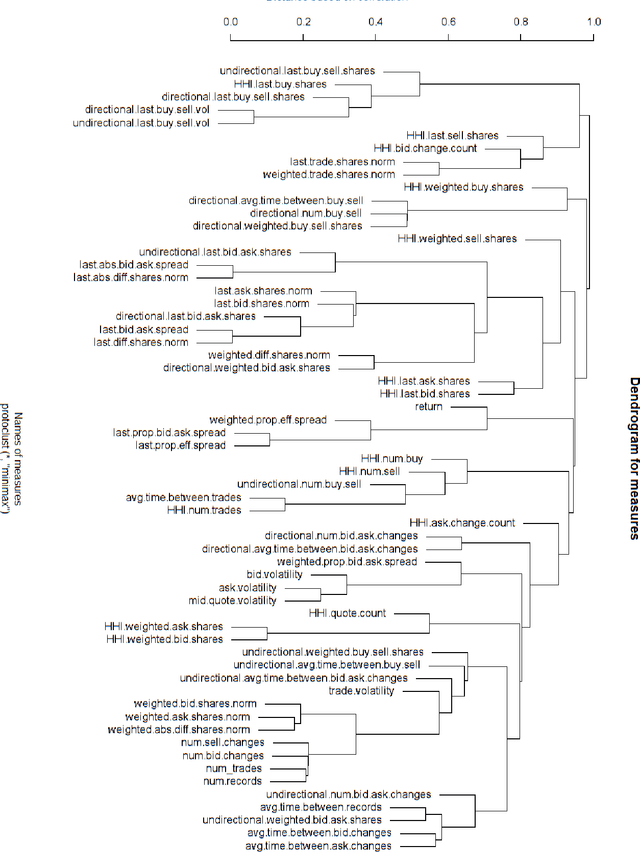
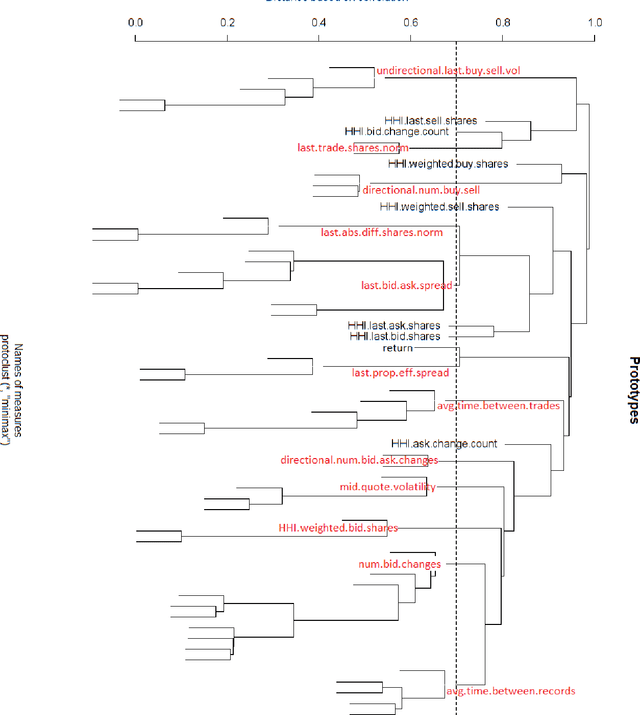
This paper builds the clustering model of measures of market microstructure features which are popular in predicting the stock returns. In a 10-second time frequency, we study the clustering structure of different measures to find out the best ones for predicting. In this way, we can predict more accurately with a limited number of predictors, which removes the noise and makes the model more interpretable.