 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Atomic Column Detection in Transmission Electron Microscopy Videos via Ridge Estimation
Feb 02, 2023



Ridge detection is a classical tool to extract curvilinear features in image processing. As such, it has great promise in applications to material science problems; specifically, for trend filtering relatively stable atom-shaped objects in image sequences, such as Transmission Electron Microscopy (TEM) videos. Standard analysis of TEM videos is limited to frame-by-frame object recognition. We instead harness temporal correlation across frames through simultaneous analysis of long image sequences, specified as a spatio-temporal image tensor. We define new ridge detection algorithms to non-parametrically estimate explicit trajectories of atomic-level object locations as a continuous function of time. Our approach is specially tailored to handle temporal analysis of objects that seemingly stochastically disappear and subsequently reappear throughout a sequence. We demonstrate that the proposed method is highly effective and efficient in simulation scenarios, and delivers notable performance improvements in TEM experiments compared to other material science benchmarks.
Detection and hypothesis testing of features in extremely noisy image series using topological data analysis, with applications to nanoparticle videos
Sep 28, 2022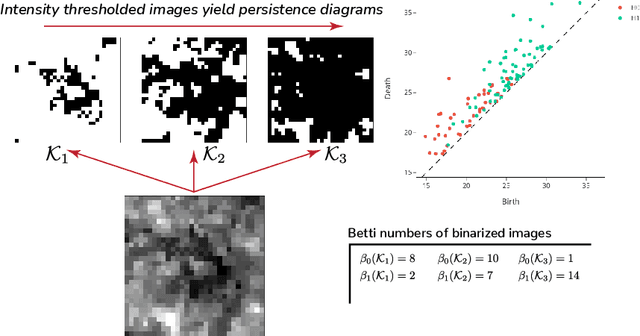



We propose a flexible approach for the detection of features in images with ultra low signal-to-noise ratio using cubical persistent homology. Our main application is in the detection of atomic columns and other features in transmission electron microscopy (TEM) images. Cubical persistent homology is used to identify local minima in subregions in the frames of nanoparticle videos, which are hypothesized to correspond to relevant atomic features. We compare the performance of our algorithm to other employed methods for the detection of columns and their intensity. Additionally, Monte Carlo goodness-of-fit testing using real-valued summaries of persistence diagrams$\unicode{8212}$including the novel ALPS statistic$\unicode{8212}$derived from smoothed images (generated from pixels residing in the vacuum region of an image) is developed and employed to identify whether or not the proposed atomic features generated by our algorithm are due to noise. Using these summaries derived from the generated persistence diagrams, one can produce univariate time series for the nanoparticle videos, thus providing a means for assessing fluxional behavior. A guarantee on the false discovery rate for multiple Monte Carlo testing of identical hypotheses is also established.
K-ARMA Models for Clustering Time Series Data
Jun 30, 2022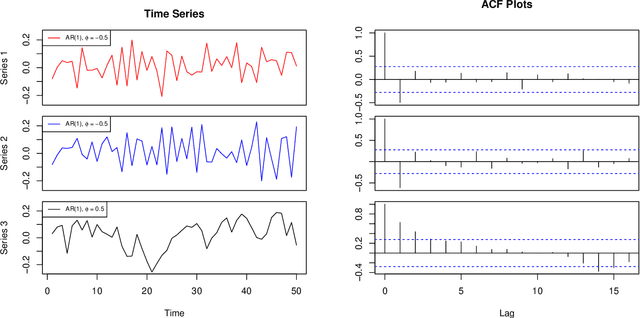
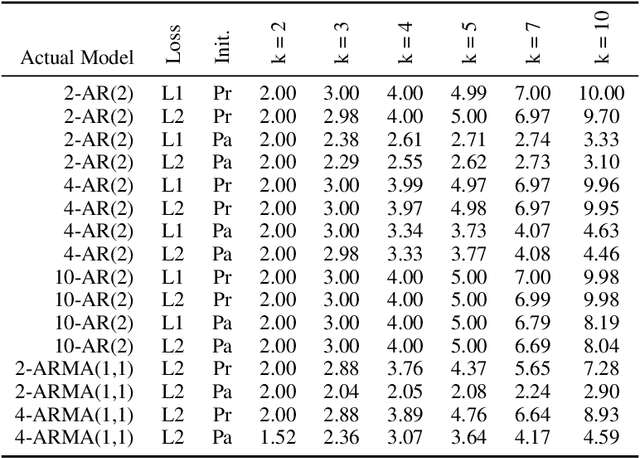
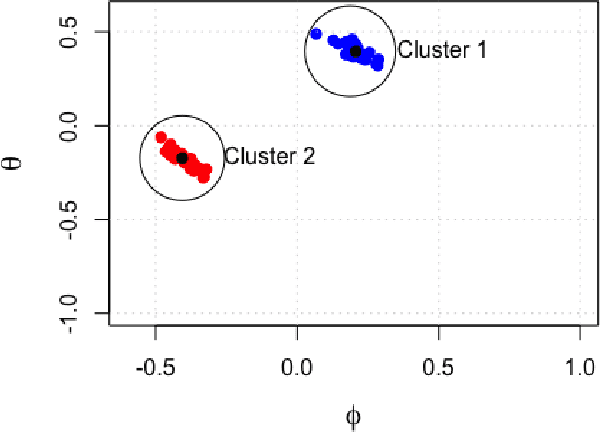

We present an approach to clustering time series data using a model-based generalization of the K-Means algorithm which we call K-Models. We prove the convergence of this general algorithm and relate it to the hard-EM algorithm for mixture modeling. We then apply our method first with an AR($p$) clustering example and show how the clustering algorithm can be made robust to outliers using a least-absolute deviations criteria. We then build our clustering algorithm up for ARMA($p,q$) models and extend this to ARIMA($p,d,q$) models. We develop a goodness of fit statistic for the models fitted to clusters based on the Ljung-Box statistic. We perform experiments with simulated data to show how the algorithm can be used for outlier detection, detecting distributional drift, and discuss the impact of initialization method on empty clusters. We also perform experiments on real data which show that our method is competitive with other existing methods for similar time series clustering tasks.
Interpretable Latent Variables in Deep State Space Models
Mar 03, 2022
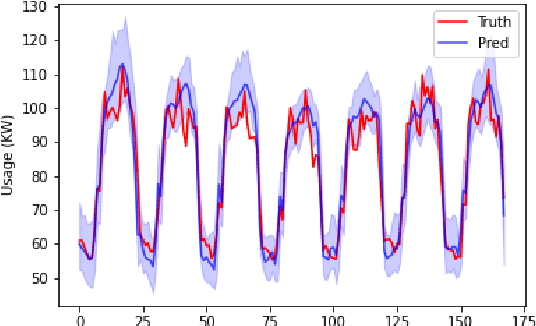

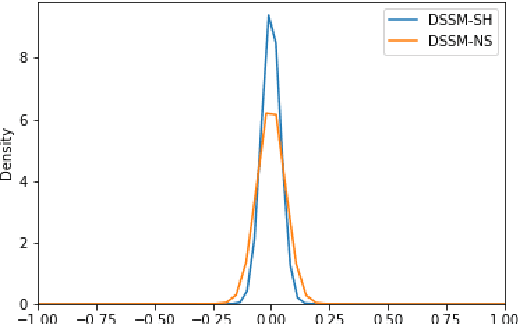
We introduce a new version of deep state-space models (DSSMs) that combines a recurrent neural network with a state-space framework to forecast time series data. The model estimates the observed series as functions of latent variables that evolve non-linearly through time. Due to the complexity and non-linearity inherent in DSSMs, previous works on DSSMs typically produced latent variables that are very difficult to interpret. Our paper focus on producing interpretable latent parameters with two key modifications. First, we simplify the predictive decoder by restricting the response variables to be a linear transformation of the latent variables plus some noise. Second, we utilize shrinkage priors on the latent variables to reduce redundancy and improve robustness. These changes make the latent variables much easier to understand and allow us to interpret the resulting latent variables as random effects in a linear mixed model. We show through two public benchmark datasets the resulting model improves forecasting performances.
Bayesian Spillover Graphs for Dynamic Networks
Mar 03, 2022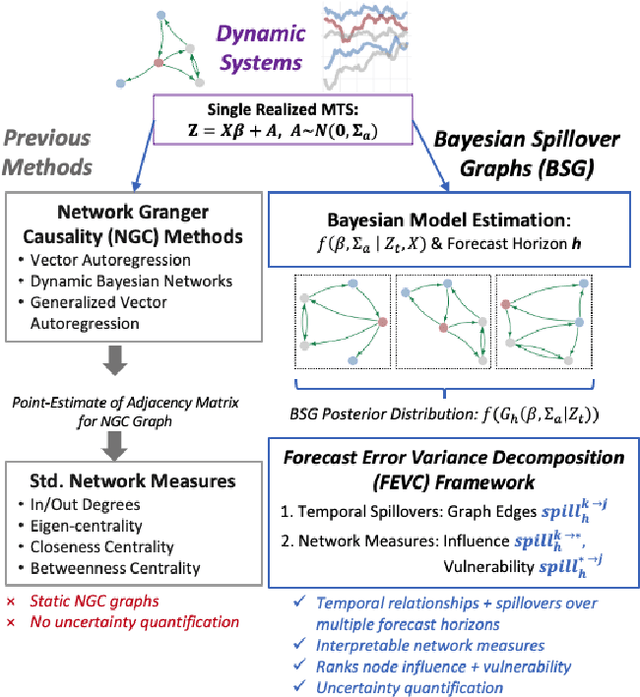
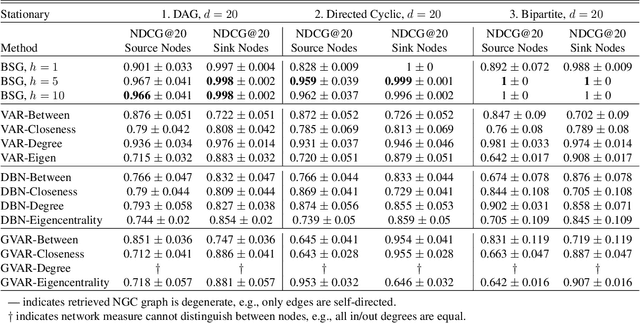
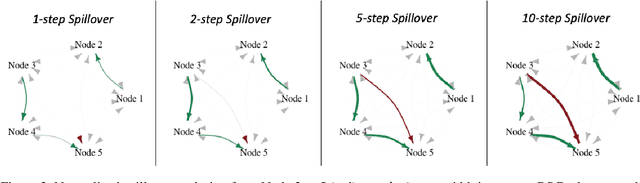
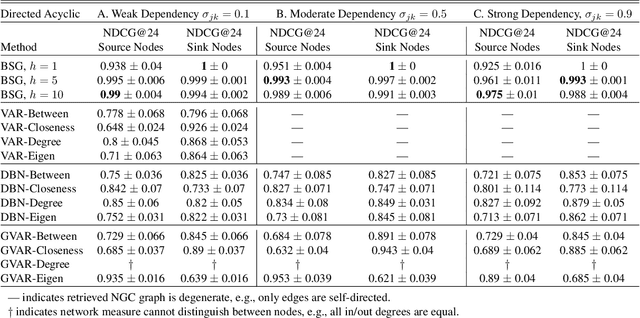
We present Bayesian Spillover Graphs (BSG), a novel method for learning temporal relationships, identifying critical nodes, and quantifying uncertainty for multi-horizon spillover effects in a dynamic system. BSG leverages both an interpretable framework via forecast error variance decompositions (FEVD) and comprehensive uncertainty quantification via Bayesian time series models to contextualize temporal relationships in terms of systemic risk and prediction variability. Forecast horizon hyperparameter $h$ allows for learning both short-term and equilibrium state network behaviors. Experiments for identifying source and sink nodes under various graph and error specifications show significant performance gains against state-of-the-art Bayesian Networks and deep-learning baselines. Applications to real-world systems also showcase BSG as an exploratory analysis tool for uncovering indirect spillovers and quantifying risk.
IB-GAN: A Unified Approach for Multivariate Time Series Classification under Class Imbalance
Oct 14, 2021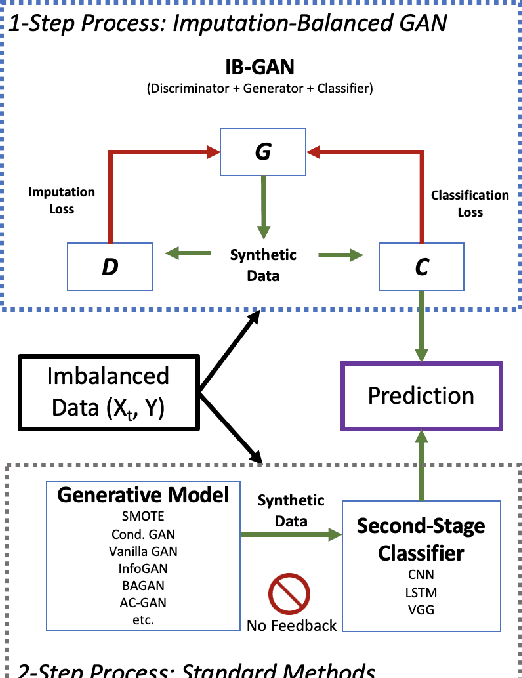
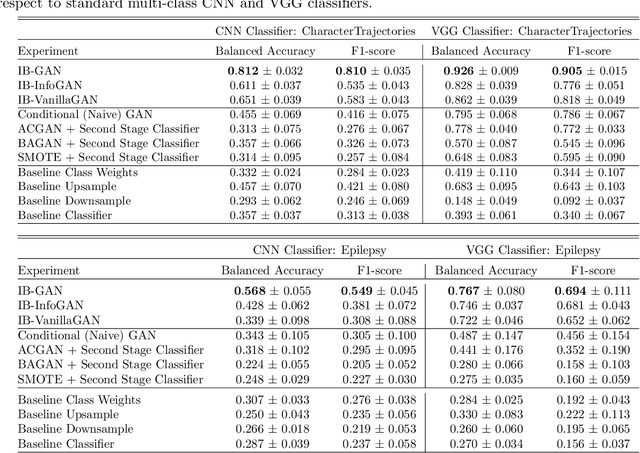
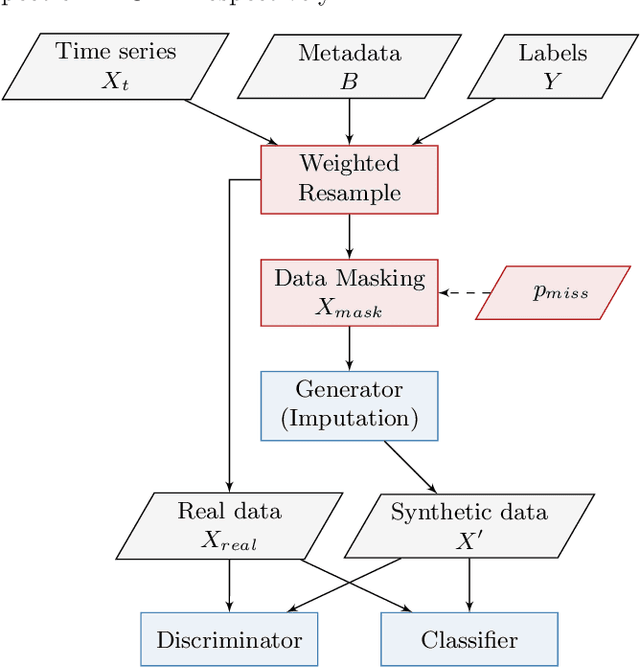
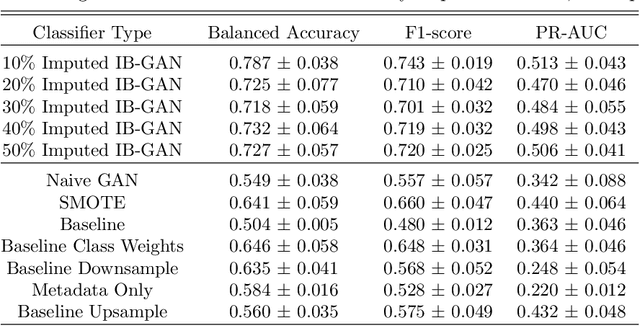
Classification of large multivariate time series with strong class imbalance is an important task in real-world applications. Standard methods of class weights, oversampling, or parametric data augmentation do not always yield significant improvements for predicting minority classes of interest. Non-parametric data augmentation with Generative Adversarial Networks (GANs) offers a promising solution. We propose Imputation Balanced GAN (IB-GAN), a novel method that joins data augmentation and classification in a one-step process via an imputation-balancing approach. IB-GAN uses imputation and resampling techniques to generate higher quality samples from randomly masked vectors than from white noise, and augments classification through a class-balanced set of real and synthetic samples. Imputation hyperparameter $p_{miss}$ allows for regularization of classifier variability by tuning innovations introduced via generator imputation. IB-GAN is simple to train and model-agnostic, pairing any deep learning classifier with a generator-discriminator duo and resulting in higher accuracy for under-observed classes. Empirical experiments on open-source UCR data and proprietary 90K product dataset show significant performance gains against state-of-the-art parametric and GAN baselines.
Developing a Deep Neural Network to Denoise Time-Resolved In Situ ETEM Movies of Catalyst Nanoparticles
Jan 19, 2021
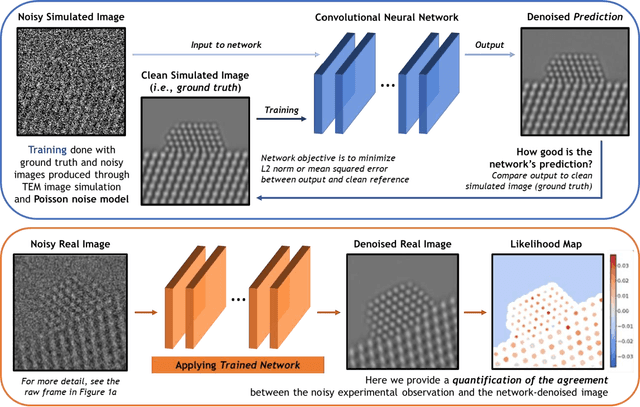
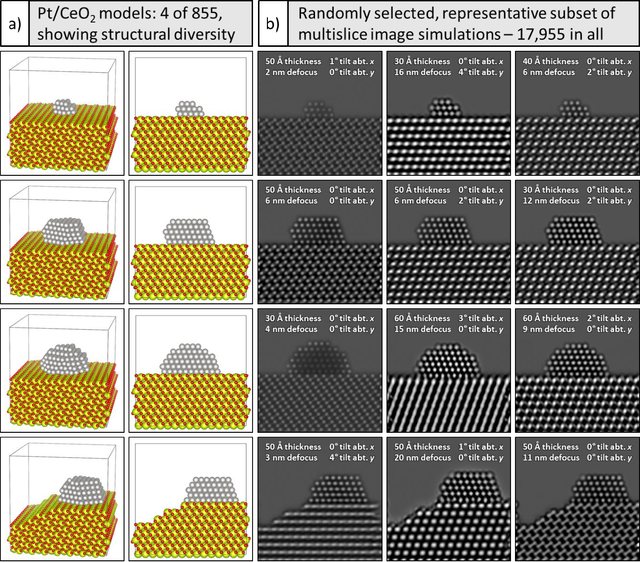

A deep learning-based convolutional neural network has been developed to denoise atomic-resolution in situ TEM image datasets of catalyst nanoparticles acquired on high speed, direct electron counting detectors, where the signal is severely limited by shot noise. The network was applied to a model catalyst of CeO2-supported Pt nanoparticles. We leverage multislice simulation to generate a large and flexible dataset for training and testing the network. The proposed network outperforms state-of-the-art denoising methods by a significant margin both on simulated and experimental test data. Factors contributing to the performance are identified, including most importantly (a) the geometry of the images used during training and (b) the size of the network's receptive field. Through a gradient-based analysis, we investigate the mechanisms used by the network to denoise experimental images. This shows the network exploits information on the surrounding structure and that it adapts its filtering approach when it encounters atomic-level defects at the catalyst surface. Extensive analysis has been done to characterize the network's ability to correctly predict the exact atomic structure at the catalyst surface. Finally, we develop an approach based on the log-likelihood ratio test that provides an quantitative measure of uncertainty regarding the atomic-level structure in the network-denoised image.
Learning to Rank with Missing Data via Generative Adversarial Networks
Nov 09, 2020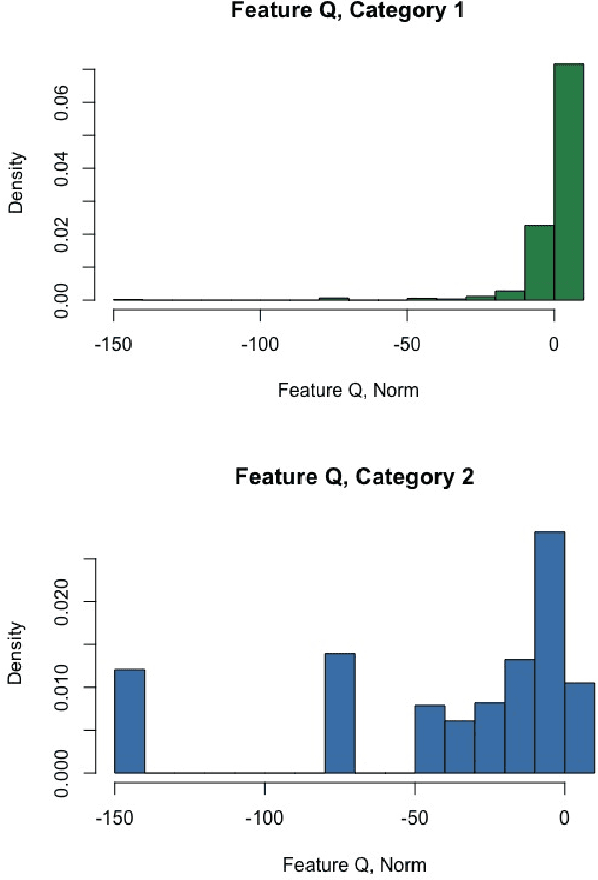

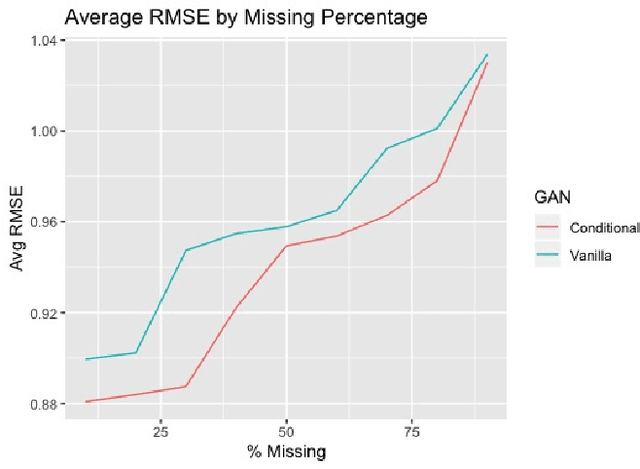
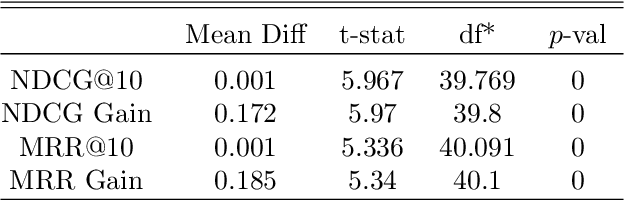
We explore the role of Conditional Generative Adversarial Networks (GAN) in imputing missing data and apply GAN imputation on a novel use case in e-commerce: a learning-to-rank problem with incomplete training data. Conventional imputation methods often make assumptions regarding the underlying distribution of the missing data, while GANs offer an alternative framework to sidestep approximating intractable distributions. First, we prove that GAN imputation offers theoretical guarantees beyond the naive Missing Completely At Random (MCAR) scenario. Next, we show that empirically, the Conditional GAN structure is well suited for data with heterogeneous distributions and across unbalanced classes, improving performance metrics such as RMSE. Using an Amazon Search ranking dataset, we produce standard ranking models trained on GAN-imputed data that are comparable to training on ground-truth data based on standard ranking quality metrics NDCG and MRR. We also highlight how different neural net features such as convolution and dropout layers can improve performance given different missing value settings.
Deep Denoising For Scientific Discovery: A Case Study In Electron Microscopy
Oct 24, 2020



Denoising is a fundamental challenge in scientific imaging. Deep convolutional neural networks (CNNs) provide the current state of the art in denoising natural images, where they produce impressive results. However, their potential has barely been explored in the context of scientific imaging. Denoising CNNs are typically trained on real natural images artificially corrupted with simulated noise. In contrast, in scientific applications, noiseless ground-truth images are usually not available. To address this issue, we propose a simulation-based denoising (SBD) framework, in which CNNs are trained on simulated images. We test the framework on data obtained from transmission electron microscopy (TEM), an imaging technique with widespread applications in material science, biology, and medicine. SBD outperforms existing techniques by a wide margin on a simulated benchmark dataset, as well as on real data. Apart from the denoised images, SBD generates likelihood maps to visualize the agreement between the structure of the denoised image and the observed data. Our results reveal shortcomings of state-of-the-art denoising architectures, such as their small field-of-view: substantially increasing the field-of-view of the CNNs allows them to exploit non-local periodic patterns in the data, which is crucial at high noise levels. In addition, we analyze the generalization capability of SBD, demonstrating that the trained networks are robust to variations of imaging parameters and of the underlying signal structure. Finally, we release the first publicly available benchmark dataset of TEM images, containing 18,000 examples.
Graph-Based Continual Learning
Jul 09, 2020
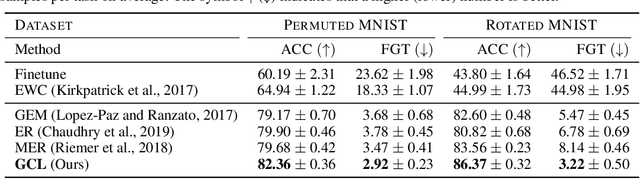
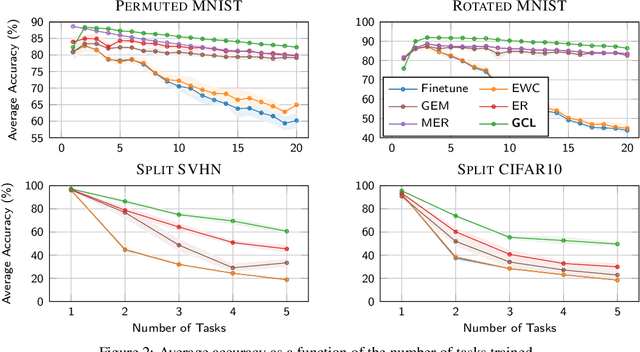
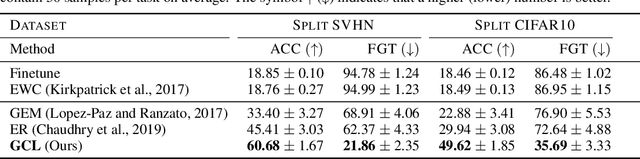
Despite significant advances, continual learning models still suffer from catastrophic forgetting when exposed to incrementally available data from non-stationary distributions. Rehearsal approaches alleviate the problem by maintaining and replaying a small episodic memory of previous samples, often implemented as an array of independent memory slots. In this work, we propose to augment such an array with a learnable random graph that captures pairwise similarities between its samples, and use it not only to learn new tasks but also to guard against forgetting. Empirical results on several benchmark datasets show that our model consistently outperforms recently proposed baselines for task-free continual learning.