 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-ARMA Models for Clustering Time Series Data
Jun 30, 2022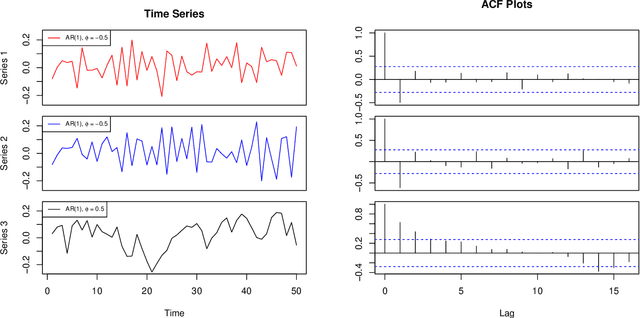
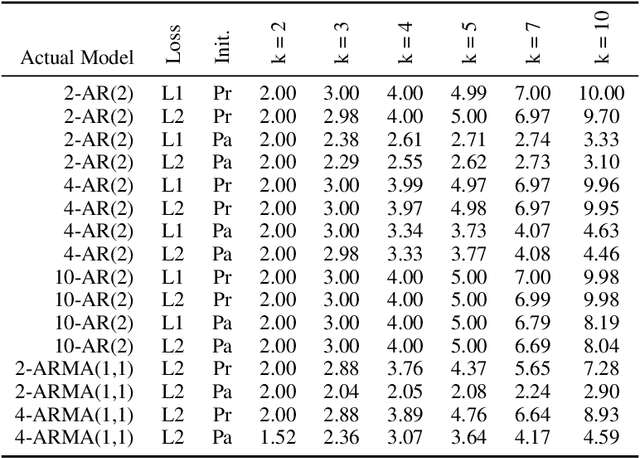
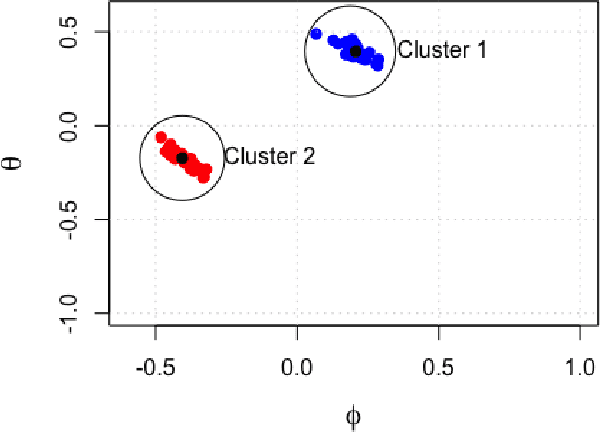

We present an approach to clustering time series data using a model-based generalization of the K-Means algorithm which we call K-Models. We prove the convergence of this general algorithm and relate it to the hard-EM algorithm for mixture modeling. We then apply our method first with an AR($p$) clustering example and show how the clustering algorithm can be made robust to outliers using a least-absolute deviations criteria. We then build our clustering algorithm up for ARMA($p,q$) models and extend this to ARIMA($p,d,q$) models. We develop a goodness of fit statistic for the models fitted to clusters based on the Ljung-Box statistic. We perform experiments with simulated data to show how the algorithm can be used for outlier detection, detecting distributional drift, and discuss the impact of initialization method on empty clusters. We also perform experiments on real data which show that our method is competitive with other existing methods for similar time series clustering tasks.