 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Rank with Missing Data via Generative Adversarial Networks
Paper and Code
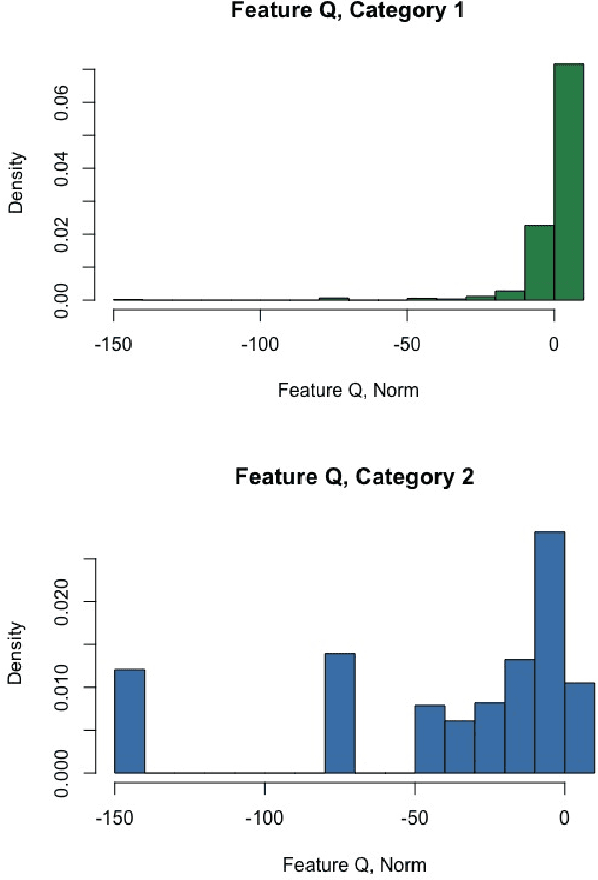

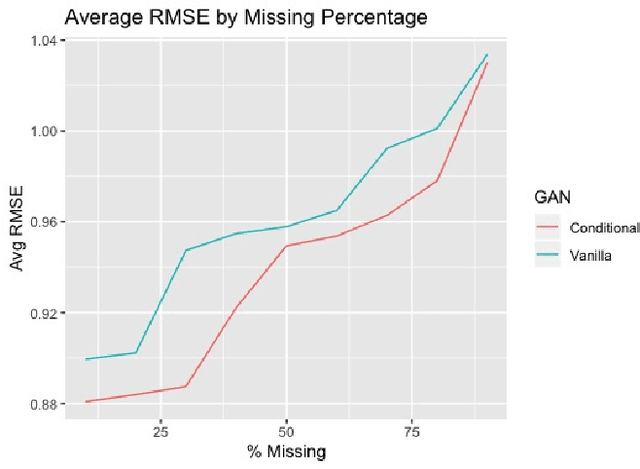
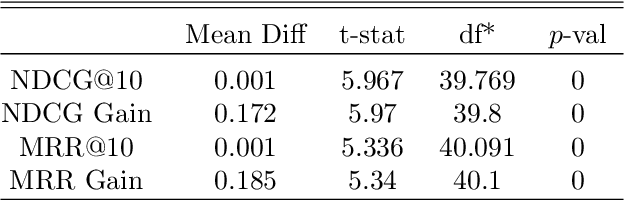
We explore the role of Conditional Generative Adversarial Networks (GAN) in imputing missing data and apply GAN imputation on a novel use case in e-commerce: a learning-to-rank problem with incomplete training data. Conventional imputation methods often make assumptions regarding the underlying distribution of the missing data, while GANs offer an alternative framework to sidestep approximating intractable distributions. First, we prove that GAN imputation offers theoretical guarantees beyond the naive Missing Completely At Random (MCAR) scenario. Next, we show that empirically, the Conditional GAN structure is well suited for data with heterogeneous distributions and across unbalanced classes, improving performance metrics such as RMSE. Using an Amazon Search ranking dataset, we produce standard ranking models trained on GAN-imputed data that are comparable to training on ground-truth data based on standard ranking quality metrics NDCG and MRR. We also highlight how different neural net features such as convolution and dropout layers can improve performance given different missing value settings.