 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetadata Extraction Leveraging Large Language Models
Oct 22, 2025The advent of Large Language Models has revolutionized tasks across domains, including the automation of legal document analysis, a critical component of modern contract management systems. This paper presents a comprehensive implementation of LLM-enhanced metadata extraction for contract review, focusing on the automatic detection and annotation of salient legal clauses. Leveraging both the publicly available Contract Understanding Atticus Dataset (CUAD) and proprietary contract datasets, our work demonstrates the integration of advanced LLM methodologies with practical applications. We identify three pivotal elements for optimizing metadata extraction: robust text conversion, strategic chunk selection, and advanced LLM-specific techniques, including Chain of Thought (CoT) prompting and structured tool calling. The results from our experiments highlight the substantial improvements in clause identification accuracy and efficiency. Our approach shows promise in reducing the time and cost associated with contract review while maintaining high accuracy in legal clause identification. The results suggest that carefully optimized LLM systems could serve as valuable tools for legal professionals, potentially increasing access to efficient contract review services for organizations of all sizes.
Mitigating Exploitation Bias in Learning to Rank with an Uncertainty-aware Empirical Bayes Approach
May 26, 2023



Ranking is at the core of many artificial intelligence (AI) applications, including search engines, recommender systems, etc. Modern ranking systems are often constructed with learning-to-rank (LTR) models built from user behavior signals. While previous studies have demonstrated the effectiveness of using user behavior signals (e.g., clicks) as both features and labels of LTR algorithms, we argue that existing LTR algorithms that indiscriminately treat behavior and non-behavior signals in input features could lead to suboptimal performance in practice. Particularly because user behavior signals often have strong correlations with the ranking objective and can only be collected on items that have already been shown to users, directly using behavior signals in LTR could create an exploitation bias that hurts the system performance in the long run. To address the exploitation bias, we propose EBRank, an empirical Bayes-based uncertainty-aware ranking algorithm. Specifically, to overcome exploitation bias brought by behavior features in ranking models, EBRank uses a sole non-behavior feature based prior model to get a prior estimation of relevance. In the dynamic training and serving of ranking systems, EBRank uses the observed user behaviors to update posterior relevance estimation instead of concatenating behaviors as features in ranking models. Besides, EBRank additionally applies an uncertainty-aware exploration strategy to explore actively, collect user behaviors for empirical Bayesian modeling and improve ranking performance. Experiments on three public datasets show that EBRank is effective, practical and significantly outperforms state-of-the-art ranking algorithms.
IB-GAN: A Unified Approach for Multivariate Time Series Classification under Class Imbalance
Oct 14, 2021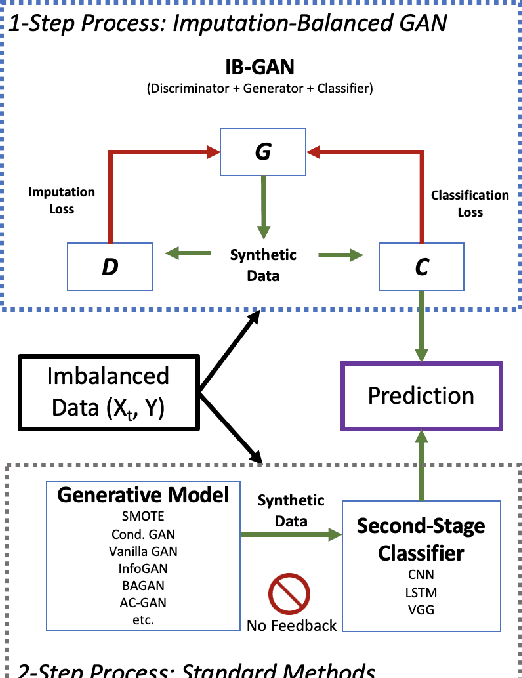
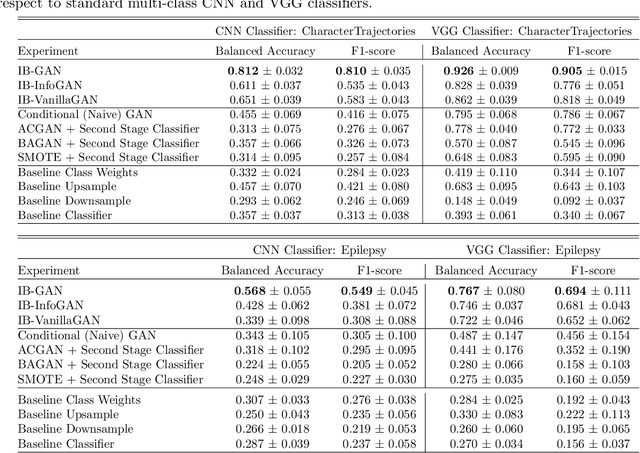
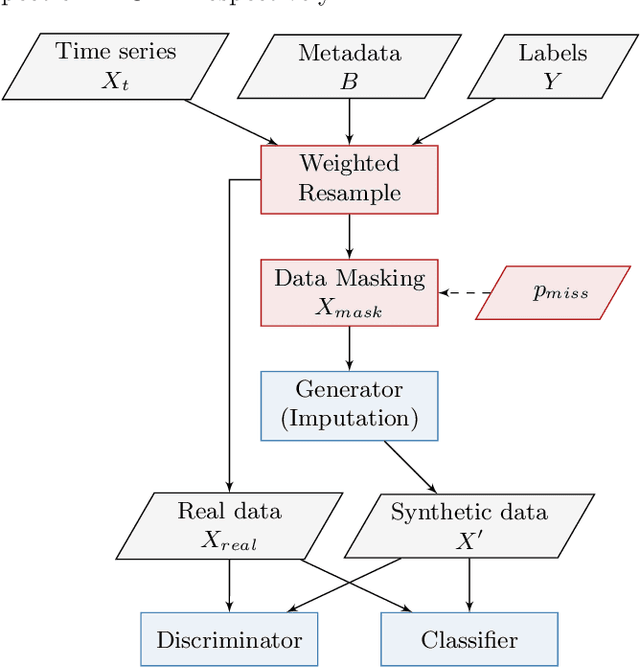
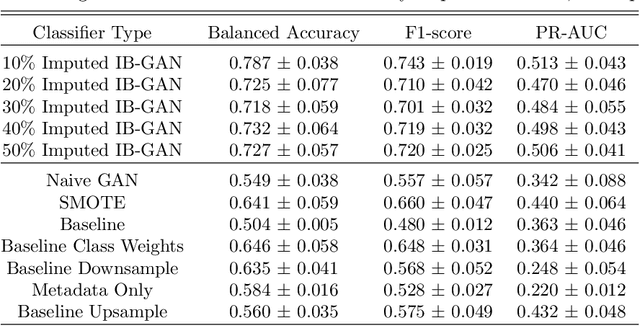
Classification of large multivariate time series with strong class imbalance is an important task in real-world applications. Standard methods of class weights, oversampling, or parametric data augmentation do not always yield significant improvements for predicting minority classes of interest. Non-parametric data augmentation with Generative Adversarial Networks (GANs) offers a promising solution. We propose Imputation Balanced GAN (IB-GAN), a novel method that joins data augmentation and classification in a one-step process via an imputation-balancing approach. IB-GAN uses imputation and resampling techniques to generate higher quality samples from randomly masked vectors than from white noise, and augments classification through a class-balanced set of real and synthetic samples. Imputation hyperparameter $p_{miss}$ allows for regularization of classifier variability by tuning innovations introduced via generator imputation. IB-GAN is simple to train and model-agnostic, pairing any deep learning classifier with a generator-discriminator duo and resulting in higher accuracy for under-observed classes. Empirical experiments on open-source UCR data and proprietary 90K product dataset show significant performance gains against state-of-the-art parametric and GAN baselines.
Scalable Feature Selection for (Multitask) Gradient Boosted Trees
Sep 05, 2021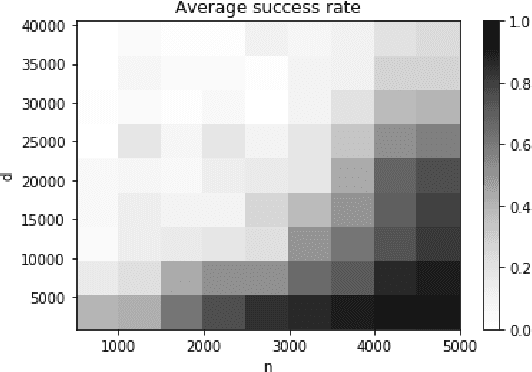
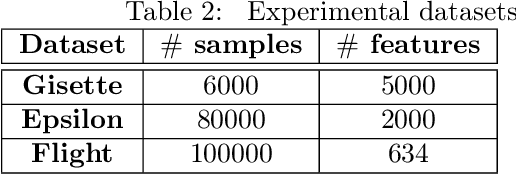
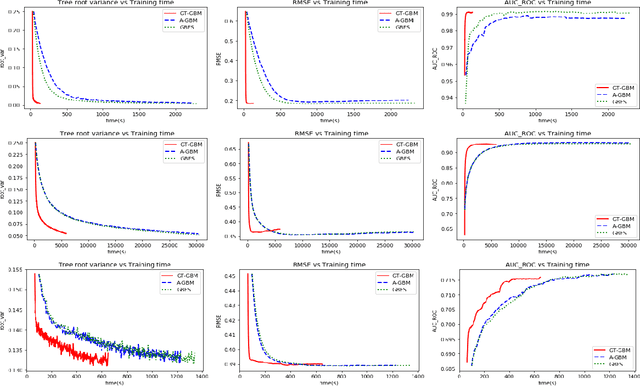
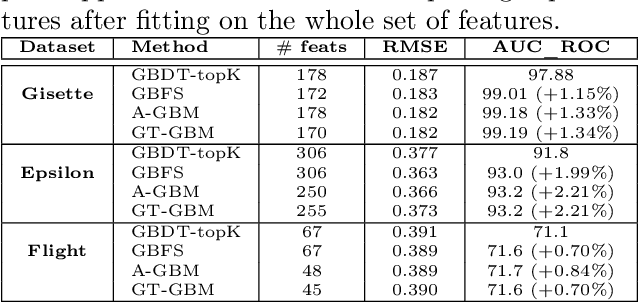
Gradient Boosted Decision Trees (GBDTs) are widely used for building ranking and relevance models in search and recommendation. Considerations such as latency and interpretability dictate the use of as few features as possible to train these models. Feature selection in GBDT models typically involves heuristically ranking the features by importance and selecting the top few, or by performing a full backward feature elimination routine. On-the-fly feature selection methods proposed previously scale suboptimally with the number of features, which can be daunting in high dimensional settings. We develop a scalable forward feature selection variant for GBDT, via a novel group testing procedure that works well in high dimensions, and enjoys favorable theoretical performance and computational guarantees. We show via extensive experiments on both public and proprietary datasets that the proposed method offers significant speedups in training time, while being as competitive as existing GBDT methods in terms of model performance metrics. We also extend the method to the multitask setting, allowing the practitioner to select common features across tasks, as well as selecting task-specific features.
* Correct a mistake in the proof of Lemma B1 in http://proceedings.mlr.press/v108/han20a.html
Aggregated Customer Engagement Model
Aug 17, 2021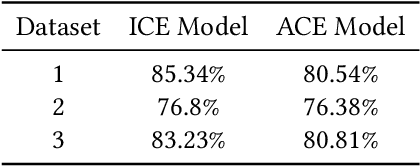

E-commerce websites use machine learned ranking models to serve shopping results to customers. Typically, the websites log the customer search events, which include the query entered and the resulting engagement with the shopping results, such as clicks and purchases. Each customer search event serves as input training data for the models, and the individual customer engagement serves as a signal for customer preference. So a purchased shopping result, for example, is perceived to be more important than one that is not. However, new or under-impressed products do not have enough customer engagement signals and end up at a disadvantage when being ranked alongside popular products. In this paper, we propose a novel method for data curation that aggregates all customer engagements within a day for the same query to use as input training data. This aggregated customer engagement gives the models a complete picture of the relative importance of shopping results. Training models on this aggregated data leads to less reliance on behavioral features. This helps mitigate the cold start problem and boosted relevant new products to top search results. In this paper, we present the offline and online analysis and results comparing the individual and aggregated customer engagement models trained on e-commerce data.
Learning to Rank with Missing Data via Generative Adversarial Networks
Nov 09, 2020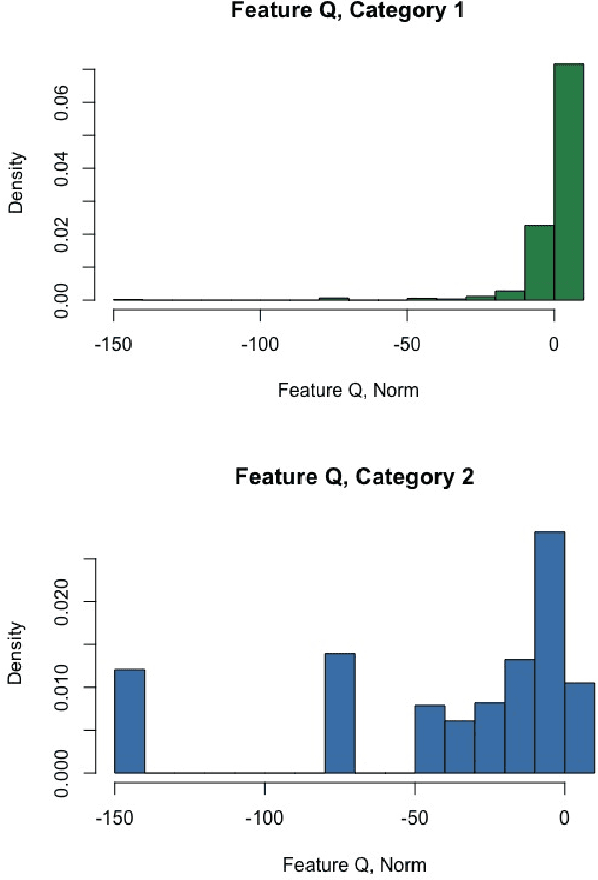

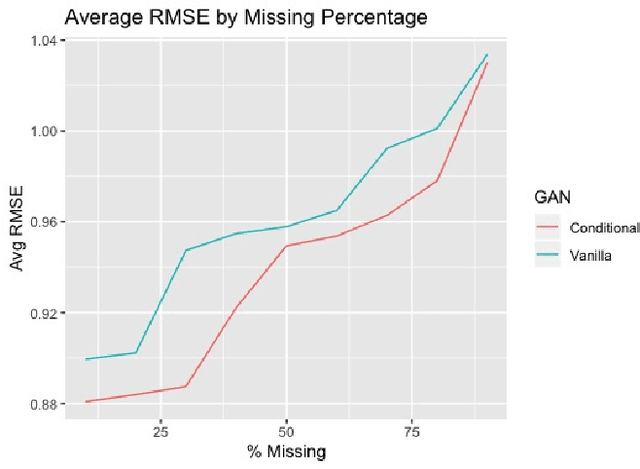
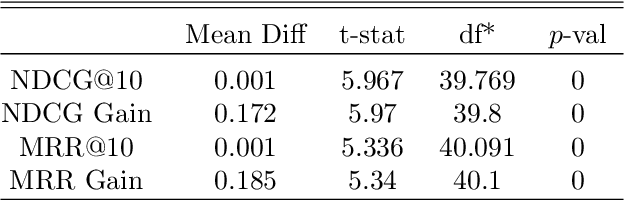
We explore the role of Conditional Generative Adversarial Networks (GAN) in imputing missing data and apply GAN imputation on a novel use case in e-commerce: a learning-to-rank problem with incomplete training data. Conventional imputation methods often make assumptions regarding the underlying distribution of the missing data, while GANs offer an alternative framework to sidestep approximating intractable distributions. First, we prove that GAN imputation offers theoretical guarantees beyond the naive Missing Completely At Random (MCAR) scenario. Next, we show that empirically, the Conditional GAN structure is well suited for data with heterogeneous distributions and across unbalanced classes, improving performance metrics such as RMSE. Using an Amazon Search ranking dataset, we produce standard ranking models trained on GAN-imputed data that are comparable to training on ground-truth data based on standard ranking quality metrics NDCG and MRR. We also highlight how different neural net features such as convolution and dropout layers can improve performance given different missing value settings.