 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Spillover Graphs for Dynamic Networks
Mar 03, 2022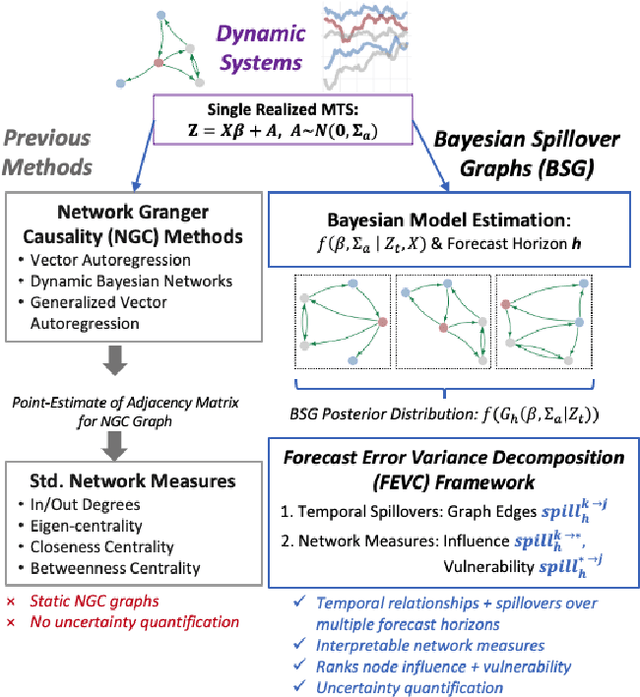
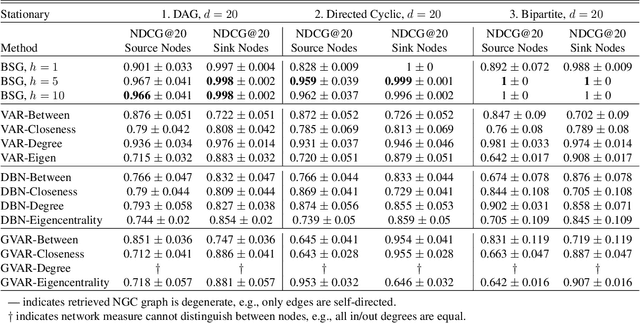
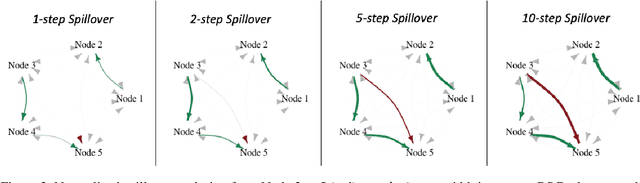
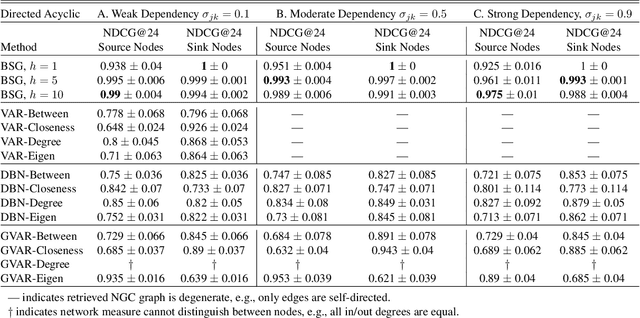
We present Bayesian Spillover Graphs (BSG), a novel method for learning temporal relationships, identifying critical nodes, and quantifying uncertainty for multi-horizon spillover effects in a dynamic system. BSG leverages both an interpretable framework via forecast error variance decompositions (FEVD) and comprehensive uncertainty quantification via Bayesian time series models to contextualize temporal relationships in terms of systemic risk and prediction variability. Forecast horizon hyperparameter $h$ allows for learning both short-term and equilibrium state network behaviors. Experiments for identifying source and sink nodes under various graph and error specifications show significant performance gains against state-of-the-art Bayesian Networks and deep-learning baselines. Applications to real-world systems also showcase BSG as an exploratory analysis tool for uncovering indirect spillovers and quantifying risk.
IB-GAN: A Unified Approach for Multivariate Time Series Classification under Class Imbalance
Oct 14, 2021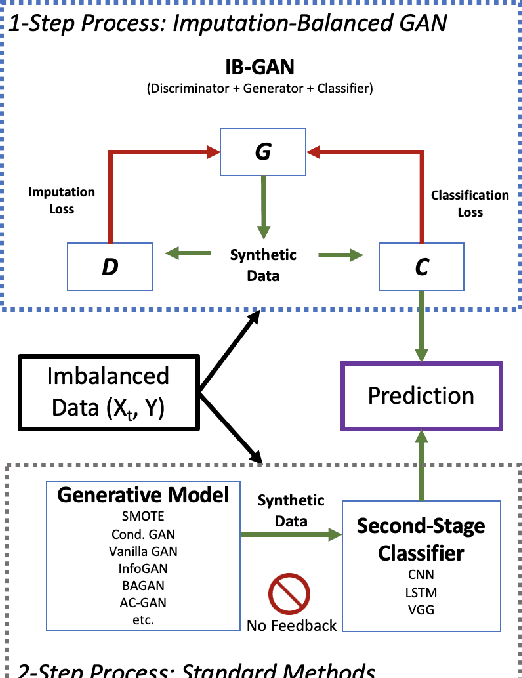
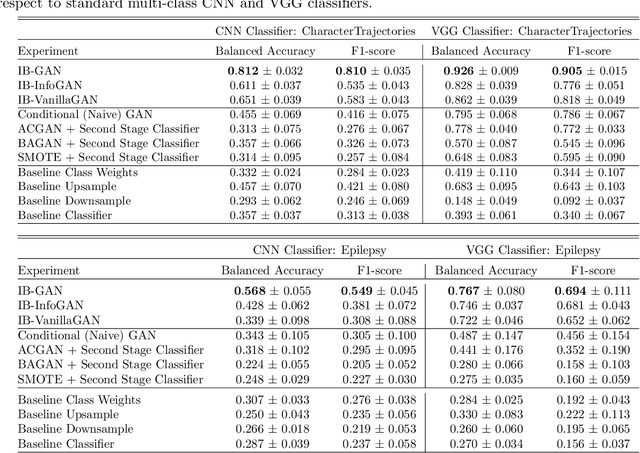
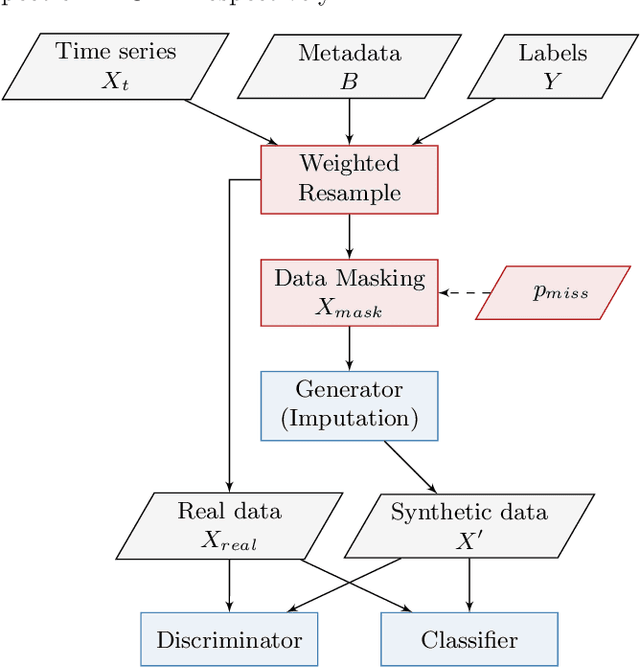
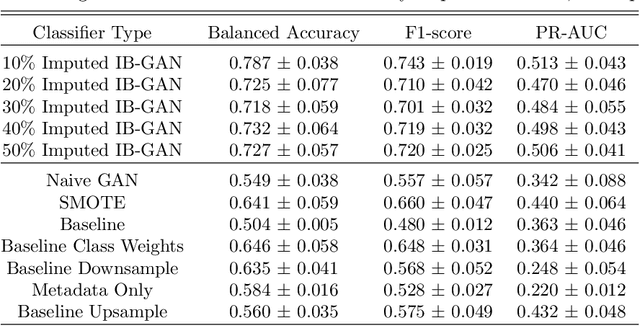
Classification of large multivariate time series with strong class imbalance is an important task in real-world applications. Standard methods of class weights, oversampling, or parametric data augmentation do not always yield significant improvements for predicting minority classes of interest. Non-parametric data augmentation with Generative Adversarial Networks (GANs) offers a promising solution. We propose Imputation Balanced GAN (IB-GAN), a novel method that joins data augmentation and classification in a one-step process via an imputation-balancing approach. IB-GAN uses imputation and resampling techniques to generate higher quality samples from randomly masked vectors than from white noise, and augments classification through a class-balanced set of real and synthetic samples. Imputation hyperparameter $p_{miss}$ allows for regularization of classifier variability by tuning innovations introduced via generator imputation. IB-GAN is simple to train and model-agnostic, pairing any deep learning classifier with a generator-discriminator duo and resulting in higher accuracy for under-observed classes. Empirical experiments on open-source UCR data and proprietary 90K product dataset show significant performance gains against state-of-the-art parametric and GAN baselines.
Learning to Rank with Missing Data via Generative Adversarial Networks
Nov 09, 2020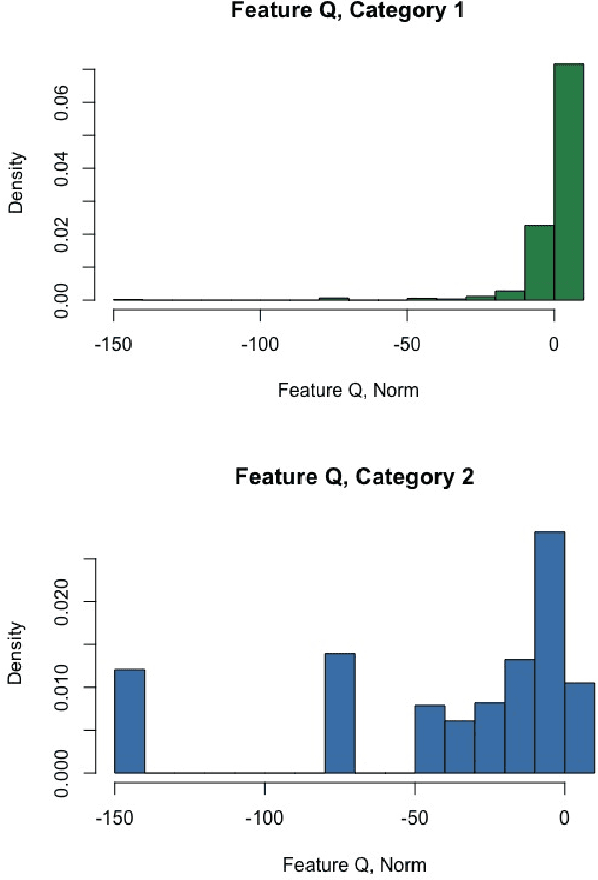

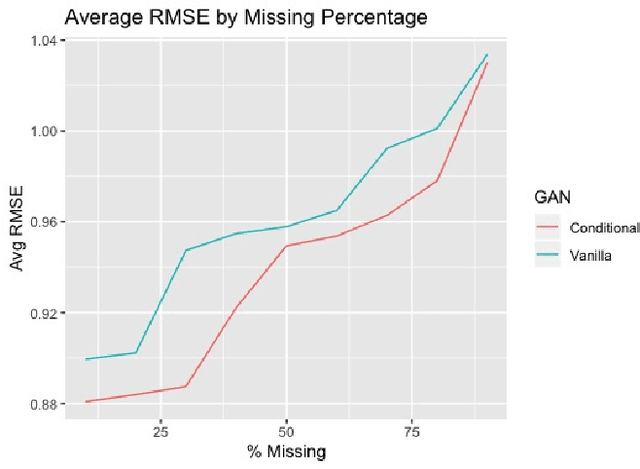
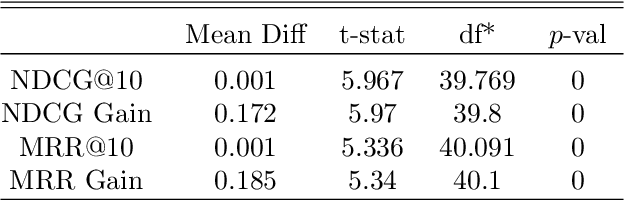
We explore the role of Conditional Generative Adversarial Networks (GAN) in imputing missing data and apply GAN imputation on a novel use case in e-commerce: a learning-to-rank problem with incomplete training data. Conventional imputation methods often make assumptions regarding the underlying distribution of the missing data, while GANs offer an alternative framework to sidestep approximating intractable distributions. First, we prove that GAN imputation offers theoretical guarantees beyond the naive Missing Completely At Random (MCAR) scenario. Next, we show that empirically, the Conditional GAN structure is well suited for data with heterogeneous distributions and across unbalanced classes, improving performance metrics such as RMSE. Using an Amazon Search ranking dataset, we produce standard ranking models trained on GAN-imputed data that are comparable to training on ground-truth data based on standard ranking quality metrics NDCG and MRR. We also highlight how different neural net features such as convolution and dropout layers can improve performance given different missing value settings.