 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Generation of Spatial Relations in Text and Image Generative Models
Nov 12, 2024



Understanding spatial relations is a crucial cognitive ability for both humans and AI. While current research has predominantly focused on the benchmarking of text-to-image (T2I) models, we propose a more comprehensive evaluation that includes \textit{both} T2I and Large Language Models (LLMs). As spatial relations are naturally understood in a visuo-spatial manner, we develop an approach to convert LLM outputs into an image, thereby allowing us to evaluate both T2I models and LLMs \textit{visually}. We examined the spatial relation understanding of 8 prominent generative models (3 T2I models and 5 LLMs) on a set of 10 common prepositions, as well as assess the feasibility of automatic evaluation methods. Surprisingly, we found that T2I models only achieve subpar performance despite their impressive general image-generation abilities. Even more surprisingly, our results show that LLMs are significantly more accurate than T2I models in generating spatial relations, despite being primarily trained on textual data. We examined reasons for model failures and highlight gaps that can be filled to enable more spatially faithful generations.
DetermiNet: A Large-Scale Diagnostic Dataset for Complex Visually-Grounded Referencing using Determiners
Sep 07, 2023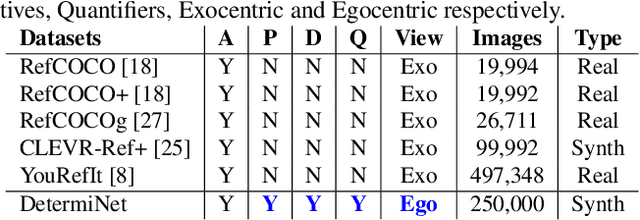
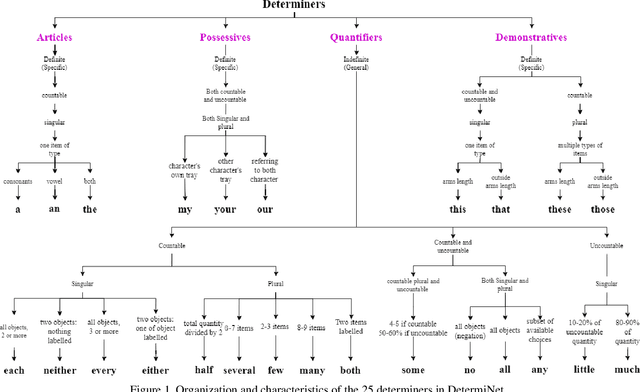
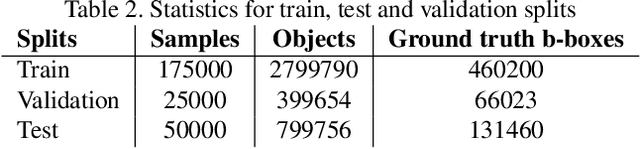

State-of-the-art visual grounding models can achieve high detection accuracy, but they are not designed to distinguish between all objects versus only certain objects of interest. In natural language, in order to specify a particular object or set of objects of interest, humans use determiners such as "my", "either" and "those". Determiners, as an important word class, are a type of schema in natural language about the reference or quantity of the noun. Existing grounded referencing datasets place much less emphasis on determiners, compared to other word classes such as nouns, verbs and adjectives. This makes it difficult to develop models that understand the full variety and complexity of object referencing. Thus, we have developed and released the DetermiNet dataset , which comprises 250,000 synthetically generated images and captions based on 25 determiners. The task is to predict bounding boxes to identify objects of interest, constrained by the semantics of the given determiner. We find that current state-of-the-art visual grounding models do not perform well on the dataset, highlighting the limitations of existing models on reference and quantification tasks.
IB-GAN: A Unified Approach for Multivariate Time Series Classification under Class Imbalance
Oct 14, 2021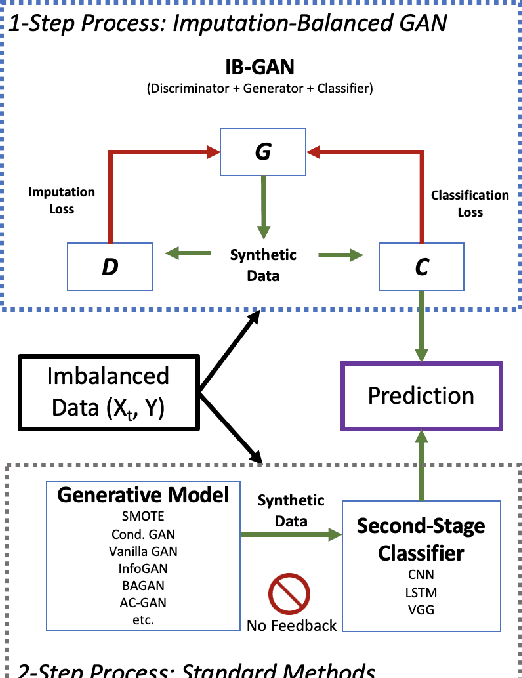
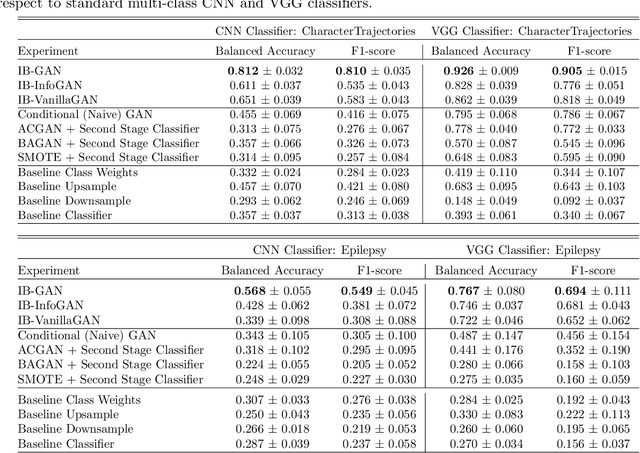
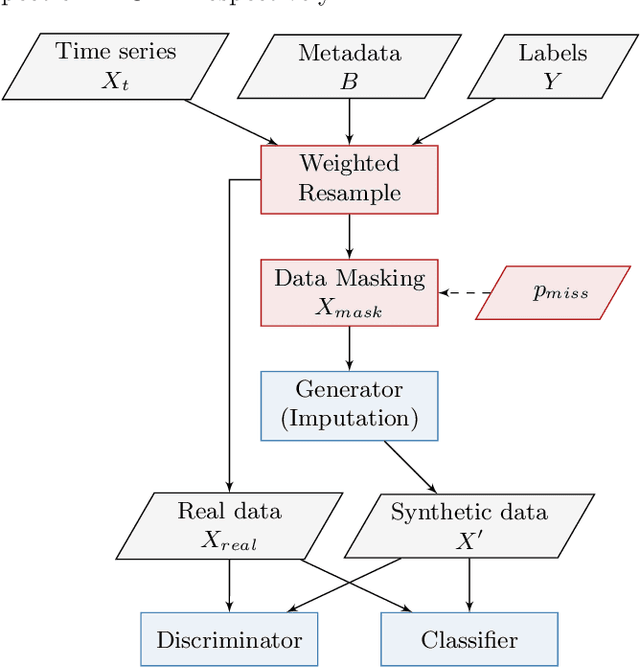
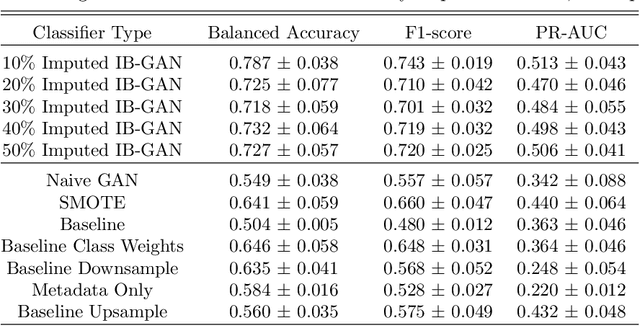
Classification of large multivariate time series with strong class imbalance is an important task in real-world applications. Standard methods of class weights, oversampling, or parametric data augmentation do not always yield significant improvements for predicting minority classes of interest. Non-parametric data augmentation with Generative Adversarial Networks (GANs) offers a promising solution. We propose Imputation Balanced GAN (IB-GAN), a novel method that joins data augmentation and classification in a one-step process via an imputation-balancing approach. IB-GAN uses imputation and resampling techniques to generate higher quality samples from randomly masked vectors than from white noise, and augments classification through a class-balanced set of real and synthetic samples. Imputation hyperparameter $p_{miss}$ allows for regularization of classifier variability by tuning innovations introduced via generator imputation. IB-GAN is simple to train and model-agnostic, pairing any deep learning classifier with a generator-discriminator duo and resulting in higher accuracy for under-observed classes. Empirical experiments on open-source UCR data and proprietary 90K product dataset show significant performance gains against state-of-the-art parametric and GAN baselines.