 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-like compositional learning of visually-grounded concepts using synthetic environments
Apr 09, 2025
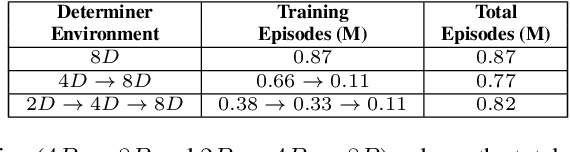
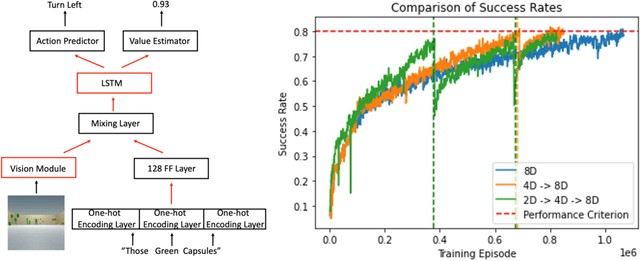
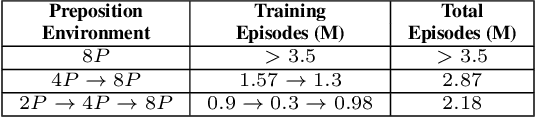
The compositional structure of language enables humans to decompose complex phrases and map them to novel visual concepts, showcasing flexible intelligence. While several algorithms exhibit compositionality, they fail to elucidate how humans learn to compose concept classes and ground visual cues through trial and error. To investigate this multi-modal learning challenge, we designed a 3D synthetic environment in which an agent learns, via reinforcement, to navigate to a target specified by a natural language instruction. These instructions comprise nouns, attributes, and critically, determiners, prepositions, or both. The vast array of word combinations heightens the compositional complexity of the visual grounding task, as navigating to a blue cube above red spheres is not rewarded when the instruction specifies navigating to "some blue cubes below the red sphere". We first demonstrate that reinforcement learning agents can ground determiner concepts to visual targets but struggle with more complex prepositional concepts. Second, we show that curriculum learning, a strategy humans employ, enhances concept learning efficiency, reducing the required training episodes by 15% in determiner environments and enabling agents to easily learn prepositional concepts. Finally, we establish that agents trained on determiner or prepositional concepts can decompose held-out test instructions and rapidly adapt their navigation policies to unseen visual object combinations. Leveraging synthetic environments, our findings demonstrate that multi-modal reinforcement learning agents can achieve compositional understanding of complex concept classes and highlight the efficacy of human-like learning strategies in improving artificial systems' learning efficiency.
Compositional Learning of Visually-Grounded Concepts Using Reinforcement
Sep 08, 2023



Deep reinforcement learning agents need to be trained over millions of episodes to decently solve navigation tasks grounded to instructions. Furthermore, their ability to generalize to novel combinations of instructions is unclear. Interestingly however, children can decompose language-based instructions and navigate to the referred object, even if they have not seen the combination of queries prior. Hence, we created three 3D environments to investigate how deep RL agents learn and compose color-shape based combinatorial instructions to solve novel combinations in a spatial navigation task. First, we explore if agents can perform compositional learning, and whether they can leverage on frozen text encoders (e.g. CLIP, BERT) to learn word combinations in fewer episodes. Next, we demonstrate that when agents are pretrained on the shape or color concepts separately, they show a 20 times decrease in training episodes needed to solve unseen combinations of instructions. Lastly, we show that agents pretrained on concept and compositional learning achieve significantly higher reward when evaluated zero-shot on novel color-shape1-shape2 visual object combinations. Overall, our results highlight the foundations needed to increase an agent's proficiency in composing word groups through reinforcement learning and its ability for zero-shot generalization to new combinations.
DetermiNet: A Large-Scale Diagnostic Dataset for Complex Visually-Grounded Referencing using Determiners
Sep 07, 2023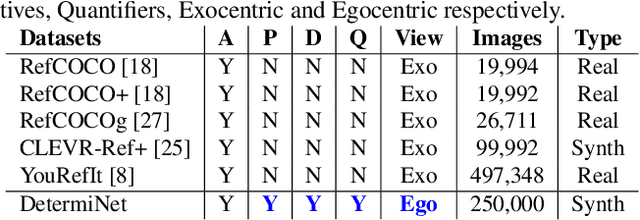
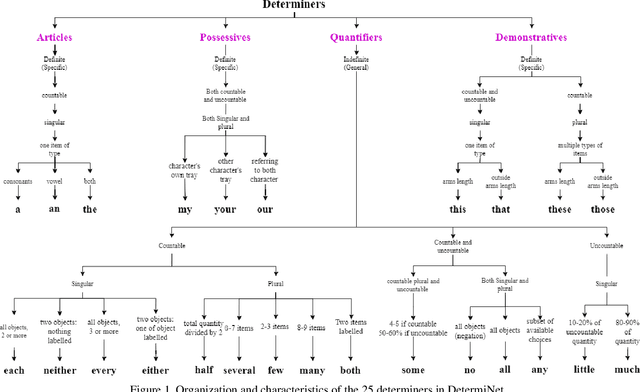
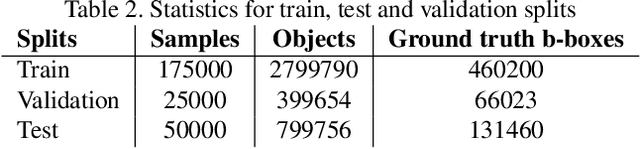

State-of-the-art visual grounding models can achieve high detection accuracy, but they are not designed to distinguish between all objects versus only certain objects of interest. In natural language, in order to specify a particular object or set of objects of interest, humans use determiners such as "my", "either" and "those". Determiners, as an important word class, are a type of schema in natural language about the reference or quantity of the noun. Existing grounded referencing datasets place much less emphasis on determiners, compared to other word classes such as nouns, verbs and adjectives. This makes it difficult to develop models that understand the full variety and complexity of object referencing. Thus, we have developed and released the DetermiNet dataset , which comprises 250,000 synthetically generated images and captions based on 25 determiners. The task is to predict bounding boxes to identify objects of interest, constrained by the semantics of the given determiner. We find that current state-of-the-art visual grounding models do not perform well on the dataset, highlighting the limitations of existing models on reference and quantification tasks.
A nonlinear hidden layer enables actor-critic agents to learn multiple paired association navigation
Jul 16, 2021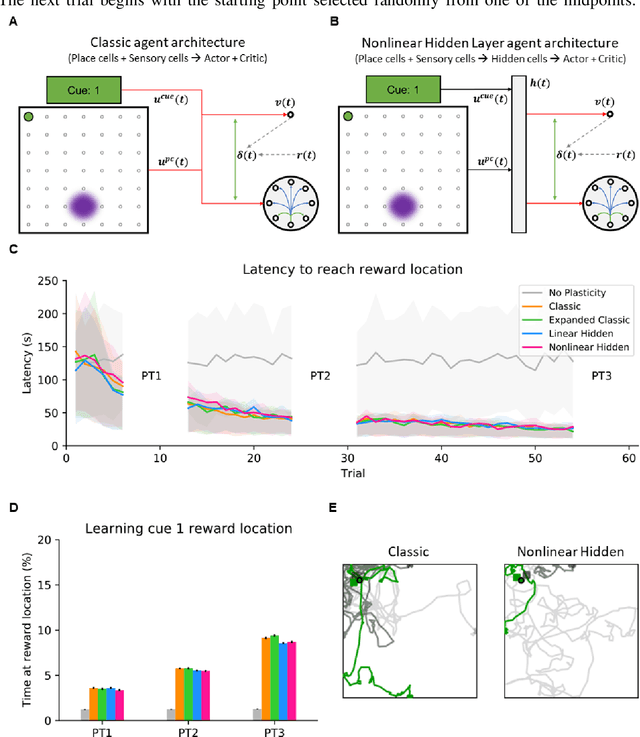
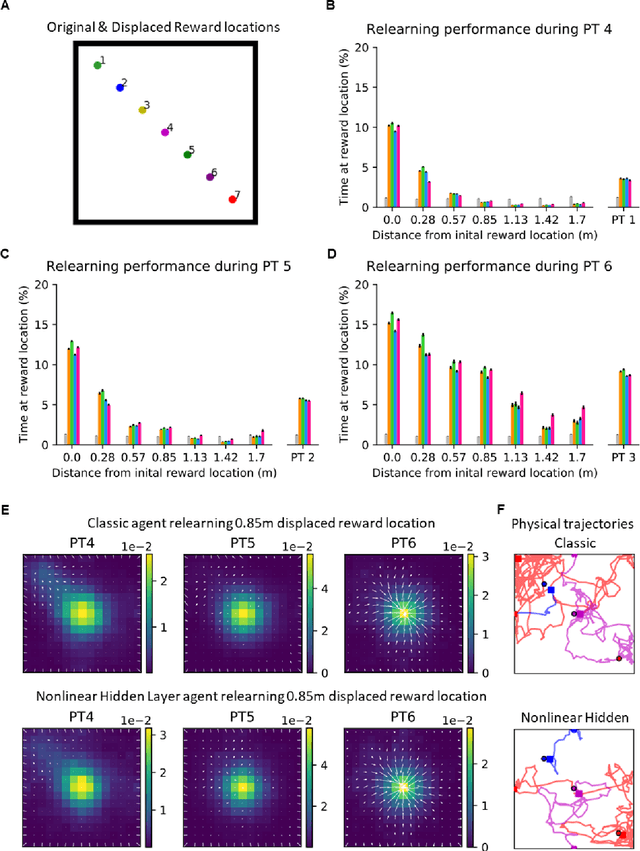

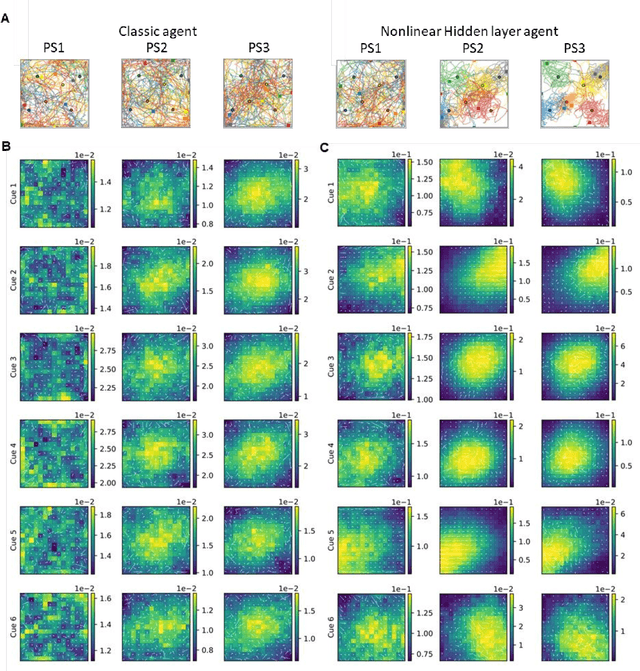
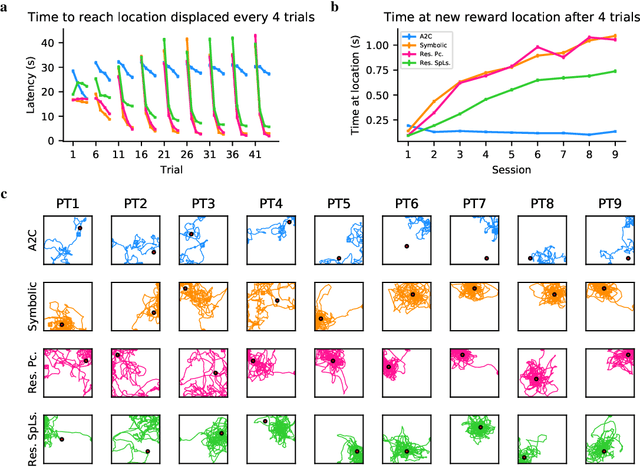
Navigation to multiple cued reward locations has been increasingly used to study rodent learning. Though deep reinforcement learning agents have been shown to be able to learn the task, they are not biologically plausible. Biologically plausible classic actor-critic agents have been shown to learn to navigate to single reward locations, but which biologically plausible agents are able to learn multiple cue-reward location tasks has remained unclear. In this computational study, we show versions of classic agents that learn to navigate to a single reward location, and adapt to reward location displacement, but are not able to learn multiple paired association navigation. The limitation is overcome by an agent in which place cell and cue information are first processed by a feedforward nonlinear hidden layer with synapses to the actor and critic subject to temporal difference error-modulated plasticity. Faster learning is obtained when the feedforward layer is replaced by a recurrent reservoir network.
One-shot learning of paired associations by a reservoir computing model with Hebbian plasticity
Jun 07, 2021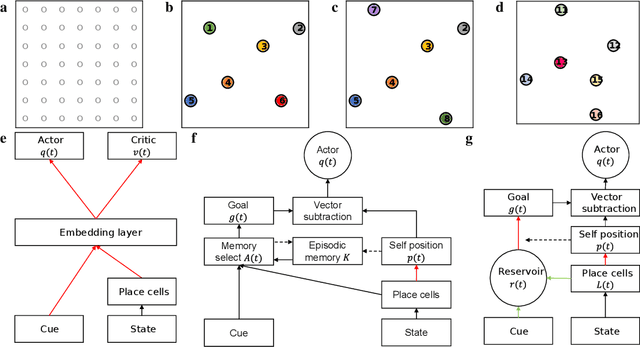


One-shot learning can be achieved by algorithms and animals, but how the latter do it is poorly understood as most of the algorithms are not biologically plausible. Experiments studying one-shot learning in rodents have shown that after initial gradual learning of associations between cues and locations, new associations can be learned with just a single exposure to each new cue-location pair. Foster, Morris and Dayan (2000) developed a hybrid temporal difference - symbolic model that exhibited one-shot learning for dead reckoning to displaced single locations. While the temporal difference rule for learning the agent's actual coordinates was biologically plausible, the model's symbolic mechanism for learning target coordinates was not, and one-shot learning for multiple target locations was not addressed. Here we extend the model by replacing the symbolic mechanism with a reservoir of recurrently connected neurons resembling cortical microcircuitry. Biologically plausible learning of target coordinates was achieved by subjecting the reservoir's output weights to synaptic plasticity governed by a novel 4-factor variant of the exploratory Hebbian (EH) rule. As with rodents, the reservoir model exhibited one-shot learning for multiple paired associations.