 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-like compositional learning of visually-grounded concepts using synthetic environments
Paper and Code
Apr 09, 2025
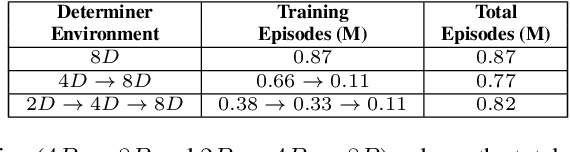
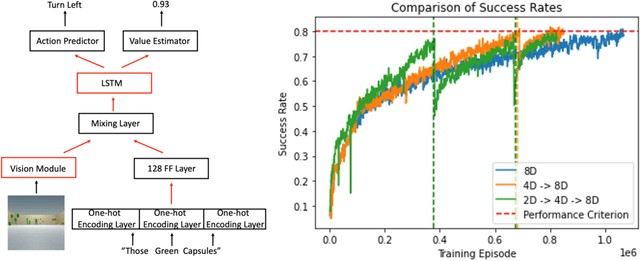
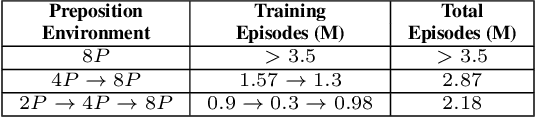
The compositional structure of language enables humans to decompose complex phrases and map them to novel visual concepts, showcasing flexible intelligence. While several algorithms exhibit compositionality, they fail to elucidate how humans learn to compose concept classes and ground visual cues through trial and error. To investigate this multi-modal learning challenge, we designed a 3D synthetic environment in which an agent learns, via reinforcement, to navigate to a target specified by a natural language instruction. These instructions comprise nouns, attributes, and critically, determiners, prepositions, or both. The vast array of word combinations heightens the compositional complexity of the visual grounding task, as navigating to a blue cube above red spheres is not rewarded when the instruction specifies navigating to "some blue cubes below the red sphere". We first demonstrate that reinforcement learning agents can ground determiner concepts to visual targets but struggle with more complex prepositional concepts. Second, we show that curriculum learning, a strategy humans employ, enhances concept learning efficiency, reducing the required training episodes by 15% in determiner environments and enabling agents to easily learn prepositional concepts. Finally, we establish that agents trained on determiner or prepositional concepts can decompose held-out test instructions and rapidly adapt their navigation policies to unseen visual object combinations. Leveraging synthetic environments, our findings demonstrate that multi-modal reinforcement learning agents can achieve compositional understanding of complex concept classes and highlight the efficacy of human-like learning strategies in improving artificial systems' learning efficiency.