 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIB-GAN: A Unified Approach for Multivariate Time Series Classification under Class Imbalance
Oct 14, 2021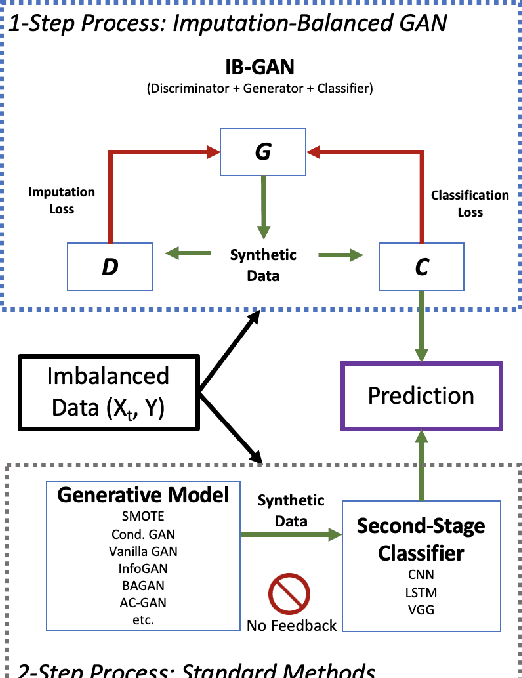
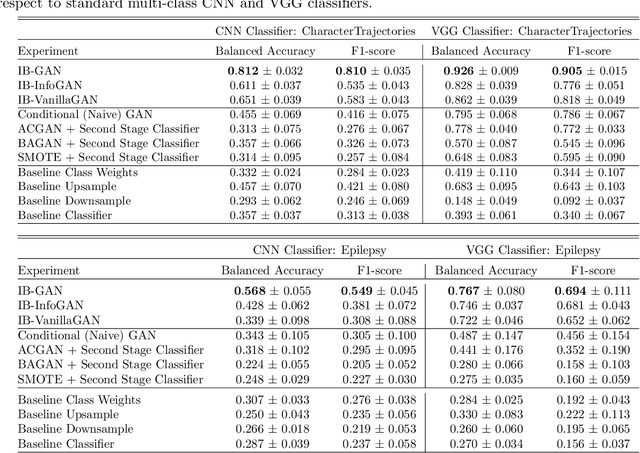
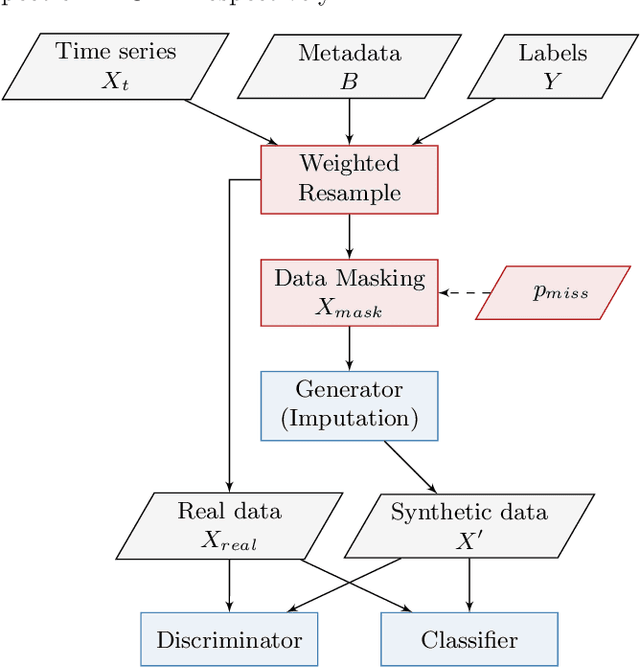
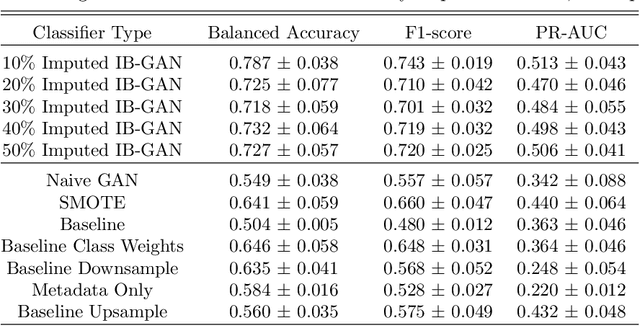
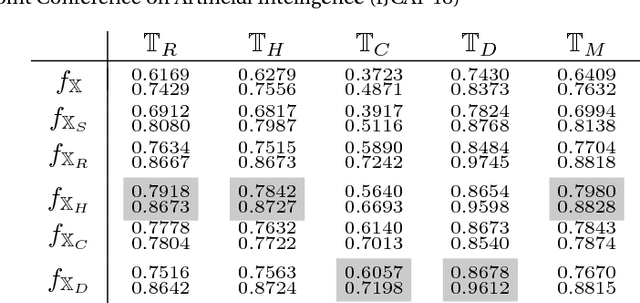
Classification of large multivariate time series with strong class imbalance is an important task in real-world applications. Standard methods of class weights, oversampling, or parametric data augmentation do not always yield significant improvements for predicting minority classes of interest. Non-parametric data augmentation with Generative Adversarial Networks (GANs) offers a promising solution. We propose Imputation Balanced GAN (IB-GAN), a novel method that joins data augmentation and classification in a one-step process via an imputation-balancing approach. IB-GAN uses imputation and resampling techniques to generate higher quality samples from randomly masked vectors than from white noise, and augments classification through a class-balanced set of real and synthetic samples. Imputation hyperparameter $p_{miss}$ allows for regularization of classifier variability by tuning innovations introduced via generator imputation. IB-GAN is simple to train and model-agnostic, pairing any deep learning classifier with a generator-discriminator duo and resulting in higher accuracy for under-observed classes. Empirical experiments on open-source UCR data and proprietary 90K product dataset show significant performance gains against state-of-the-art parametric and GAN baselines.
Analysis of E-commerce Ranking Signals via Signal Temporal Logic
Jan 14, 2021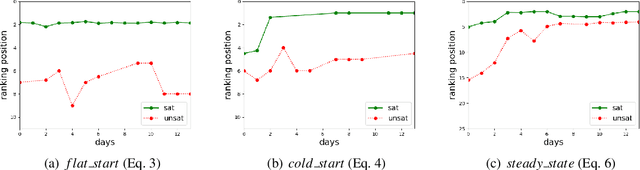
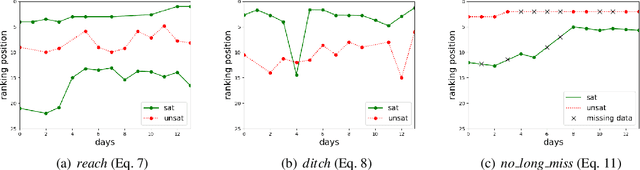
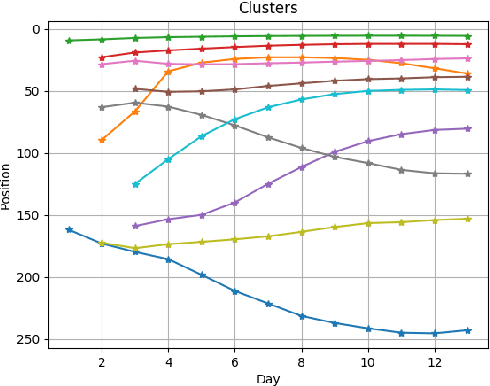
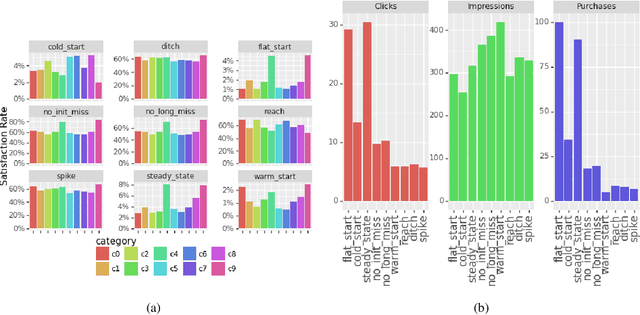
The timed position of documents retrieved by learning to rank models can be seen as signals. Signals carry useful information such as drop or rise of documents over time or user behaviors. In this work, we propose to use the logic formalism called Signal Temporal Logic (STL) to characterize document behaviors in ranking accordingly to the specified formulas. Our analysis shows that interesting document behaviors can be easily formalized and detected thanks to STL formulas. We validate our idea on a dataset of 100K product signals. Through the presented framework, we uncover interesting patterns, such as cold start, warm start, spikes, and inspect how they affect our learning to ranks models.
* In Proceedings SNR 2020, arXiv:2101.05256
Scenic: A Language for Scenario Specification and Data Generation
Oct 13, 2020
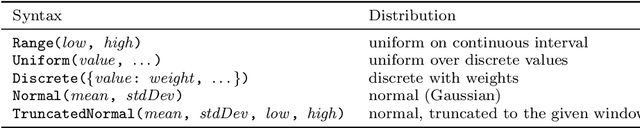
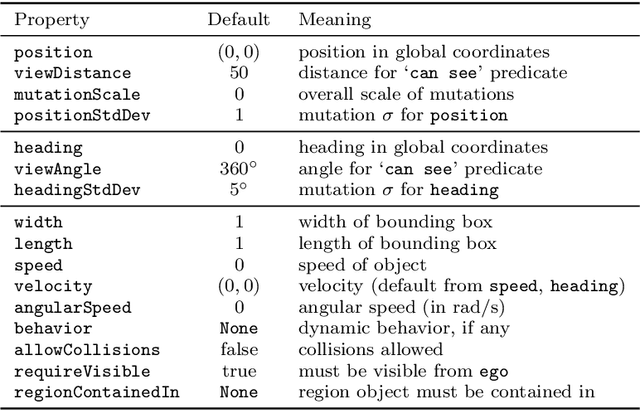
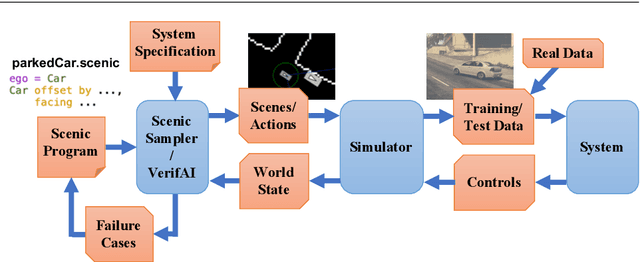
We propose a new probabilistic programming language for the design and analysis of cyber-physical systems, especially those based on machine learning. Specifically, we consider the problems of training a system to be robust to rare events, testing its performance under different conditions, and debugging failures. We show how a probabilistic programming language can help address these problems by specifying distributions encoding interesting types of inputs, then sampling these to generate specialized training and test data. More generally, such languages can be used to write environment models, an essential prerequisite to any formal analysis. In this paper, we focus on systems like autonomous cars and robots, whose environment at any point in time is a 'scene', a configuration of physical objects and agents. We design a domain-specific language, Scenic, for describing scenarios that are distributions over scenes and the behaviors of their agents over time. As a probabilistic programming language, Scenic allows assigning distributions to features of the scene, as well as declaratively imposing hard and soft constraints over the scene. We develop specialized techniques for sampling from the resulting distribution, taking advantage of the structure provided by Scenic's domain-specific syntax. Finally, we apply Scenic in a case study on a convolutional neural network designed to detect cars in road images, improving its performance beyond that achieved by state-of-the-art synthetic data generation methods.
A Formalization of Robustness for Deep Neural Networks
Mar 24, 2019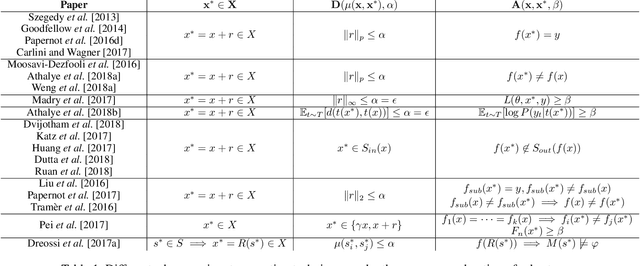
Deep neural networks have been shown to lack robustness to small input perturbations. The process of generating the perturbations that expose the lack of robustness of neural networks is known as adversarial input generation. This process depends on the goals and capabilities of the adversary, In this paper, we propose a unifying formalization of the adversarial input generation process from a formal methods perspective. We provide a definition of robustness that is general enough to capture different formulations. The expressiveness of our formalization is shown by modeling and comparing a variety of adversarial attack techniques.
VERIFAI: A Toolkit for the Design and Analysis of Artificial Intelligence-Based Systems
Feb 14, 2019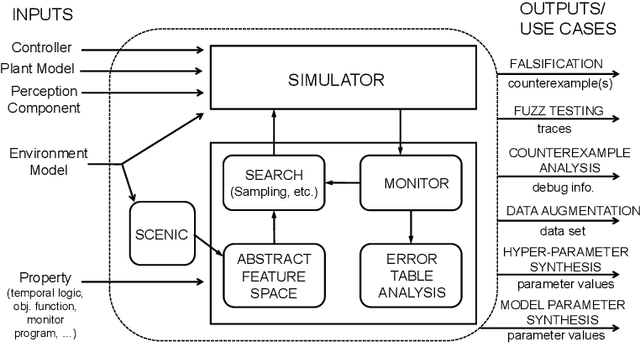



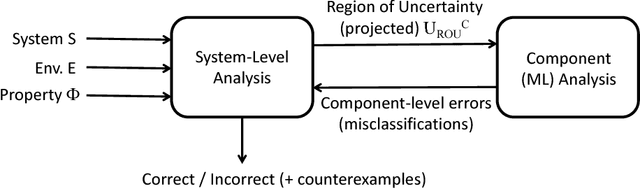
We present VERIFAI, a software toolkit for the formal design and analysis of systems that include artificial intelligence (AI) and machine learning (ML) components. VERIFAI particularly seeks to address challenges with applying formal methods to perception and ML components, including those based on neural networks, and to model and analyze system behavior in the presence of environment uncertainty. We describe the initial version of VERIFAI which centers on simulation guided by formal models and specifications. Several use cases are illustrated with examples, including temporal-logic falsification, model-based systematic fuzz testing, parameter synthesis, counterexample analysis, and data set augmentation.
Scenic: Language-Based Scene Generation
Sep 25, 2018
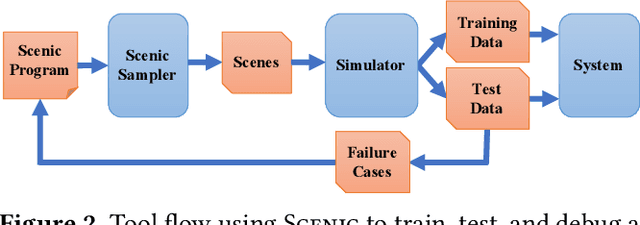
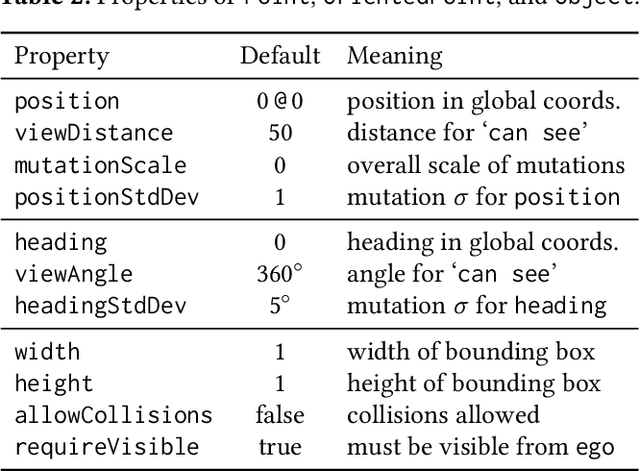

Synthetic data has proved increasingly useful in both training and testing machine learning models such as neural networks. The major problem in synthetic data generation is producing meaningful data that is not simply random but reflects properties of real-world data or covers particular cases of interest. In this paper, we show how a probabilistic programming language can be used to guide data synthesis by encoding domain knowledge about what data is useful. Specifically, we focus on data sets arising from "scenes", configurations of physical objects; for example, images of cars on a road. We design a domain-specific language, Scenic, for describing "scenarios" that are distributions over scenes. The syntax of Scenic makes it easy to specify complex relationships between the positions and orientations of objects. As a probabilistic programming language, Scenic allows assigning distributions to features of the scene, as well as declaratively imposing hard and soft constraints over the scene. A Scenic scenario thereby implicitly defines a distribution over scenes, and we formulate the problem of sampling from this distribution as "scene improvisation". We implement an improviser for Scenic scenarios and apply it in a case study generating synthetic data sets for a convolutional neural network designed to detect cars in road images. Our experiments demonstrate the usefulness of our approach by using Scenic to analyze and improve the performance of the network in various scenarios.
Semantic Adversarial Deep Learning
May 18, 2018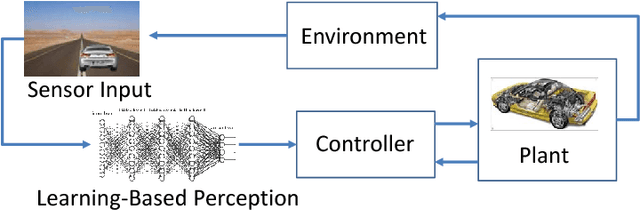
Fueled by massive amounts of data, models produced by machine-learning (ML) algorithms, especially deep neural networks, are being used in diverse domains where trustworthiness is a concern, including automotive systems, finance, health care, natural language processing, and malware detection. Of particular concern is the use of ML algorithms in cyber-physical systems (CPS), such as self-driving cars and aviation, where an adversary can cause serious consequences. However, existing approaches to generating adversarial examples and devising robust ML algorithms mostly ignore the semantics and context of the overall system containing the ML component. For example, in an autonomous vehicle using deep learning for perception, not every adversarial example for the neural network might lead to a harmful consequence. Moreover, one may want to prioritize the search for adversarial examples towards those that significantly modify the desired semantics of the overall system. Along the same lines, existing algorithms for constructing robust ML algorithms ignore the specification of the overall system. In this paper, we argue that the semantics and specification of the overall system has a crucial role to play in this line of research. We present preliminary research results that support this claim.
Counterexample-Guided Data Augmentation
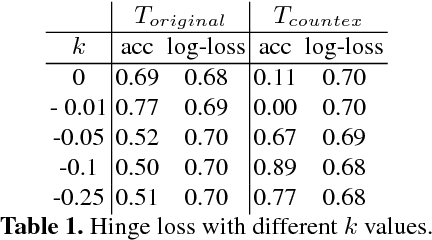
May 17, 2018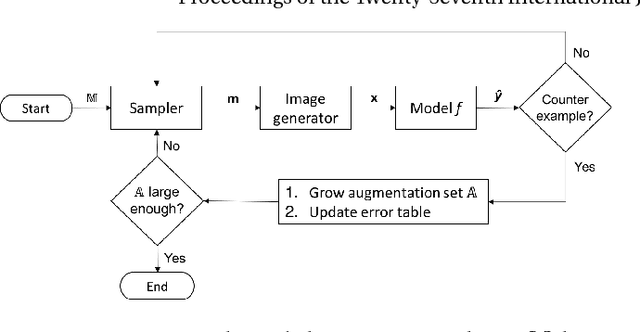


We present a novel framework for augmenting data sets for machine learning based on counterexamples. Counterexamples are misclassified examples that have important properties for retraining and improving the model. Key components of our framework include a counterexample generator, which produces data items that are misclassified by the model and error tables, a novel data structure that stores information pertaining to misclassifications. Error tables can be used to explain the model's vulnerabilities and are used to efficiently generate counterexamples for augmentation. We show the efficacy of the proposed framework by comparing it to classical augmentation techniques on a case study of object detection in autonomous driving based on deep neural networks.
Compositional Falsification of Cyber-Physical Systems with Machine Learning Components
Nov 22, 2017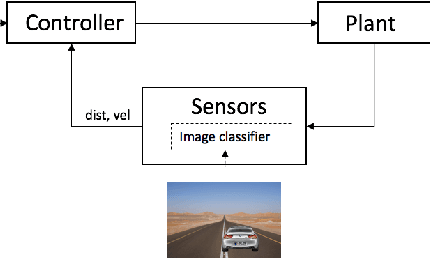
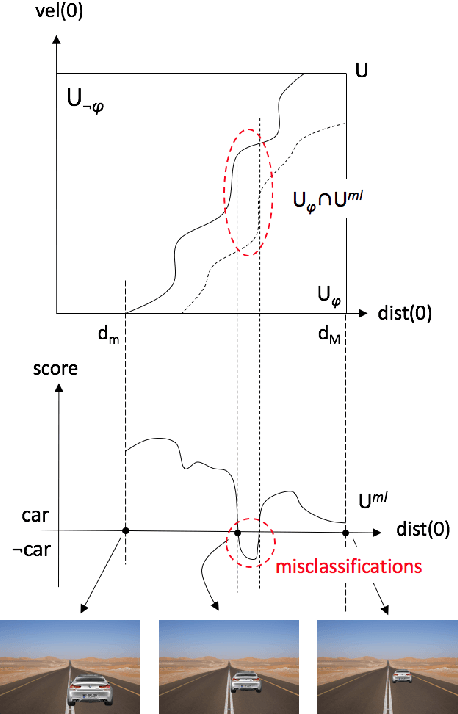
Cyber-physical systems (CPS), such as automotive systems, are starting to include sophisticated machine learning (ML) components. Their correctness, therefore, depends on properties of the inner ML modules. While learning algorithms aim to generalize from examples, they are only as good as the examples provided, and recent efforts have shown that they can produce inconsistent output under small adversarial perturbations. This raises the question: can the output from learning components can lead to a failure of the entire CPS? In this work, we address this question by formulating it as a problem of falsifying signal temporal logic (STL) specifications for CPS with ML components. We propose a compositional falsification framework where a temporal logic falsifier and a machine learning analyzer cooperate with the aim of finding falsifying executions of the considered model. The efficacy of the proposed technique is shown on an automatic emergency braking system model with a perception component based on deep neural networks.
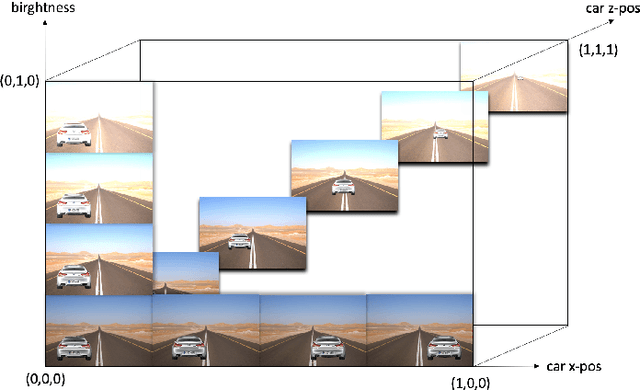
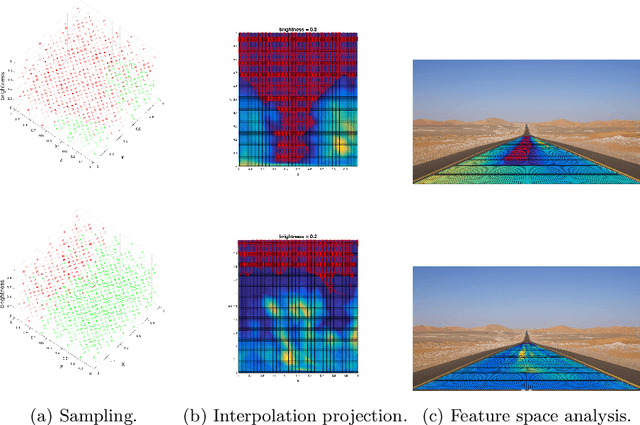
Systematic Testing of Convolutional Neural Networks for Autonomous Driving
Aug 11, 2017
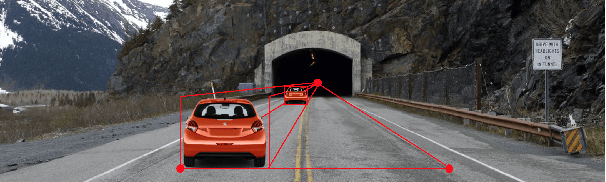
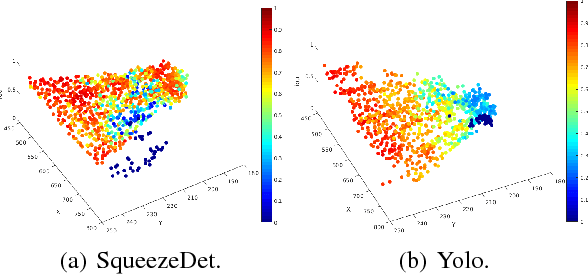
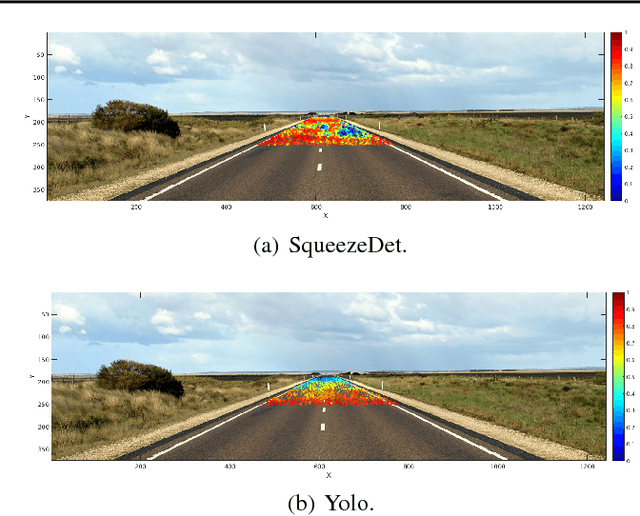
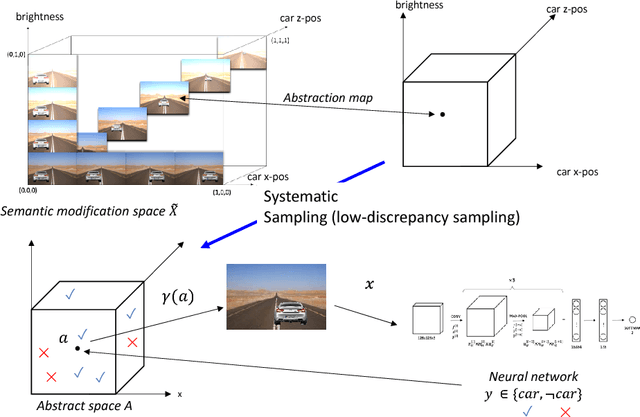
We present a framework to systematically analyze convolutional neural networks (CNNs) used in classification of cars in autonomous vehicles. Our analysis procedure comprises an image generator that produces synthetic pictures by sampling in a lower dimension image modification subspace and a suite of visualization tools. The image generator produces images which can be used to test the CNN and hence expose its vulnerabilities. The presented framework can be used to extract insights of the CNN classifier, compare across classification models, or generate training and validation datasets.